@Vengineerの戯言 : Twitter
SystemVerilogの世界へようこそ、すべては、SystemC v0.9公開から始まった
TwitterのTLに流れてきたこの記事。その時はそれほど気にしていなかったのですが、記事の最初を読んでみて、え、そんな発表があったの?知らなかったです。
いまさらながらですが、MLSE Advent Calendar 2019の24日めの記事を書きました #Qiita #mlse
— K. Ishizaki (@kiszk) 2020年1月13日
2019年10月のDavid Pattersonの講演の、TPU部分に関するまとめです。https://t.co/SQaSSX4WKR
公開されているビデオは、
「 Allen School Distinguished Lecture: David Patterson (UC Berkeley/Google)」
で、2019年11月6日に公開されています。
講演ビデオは、1時間12分なのですが、上記の記事にまとまっているので、こちらを最初に見て、詳しく知りたいときはビデオを見ればいいのでは?
それにしても、Patterson先生がこのようは発表をするのって、本当にすごいなーと。
Google TPUの説明のページにある図(下記は、URLにて組み込み参照しています)には、HBMは2組になっていますが、
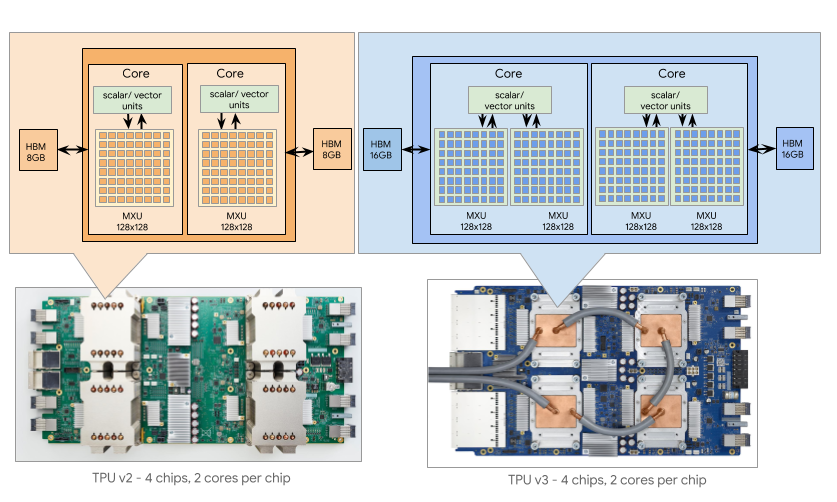
講演のこのページ(20分50秒)頃では、(下図は、記事のURLを組み込み参照しています)、HBMは2組ではなく、4組の模様。
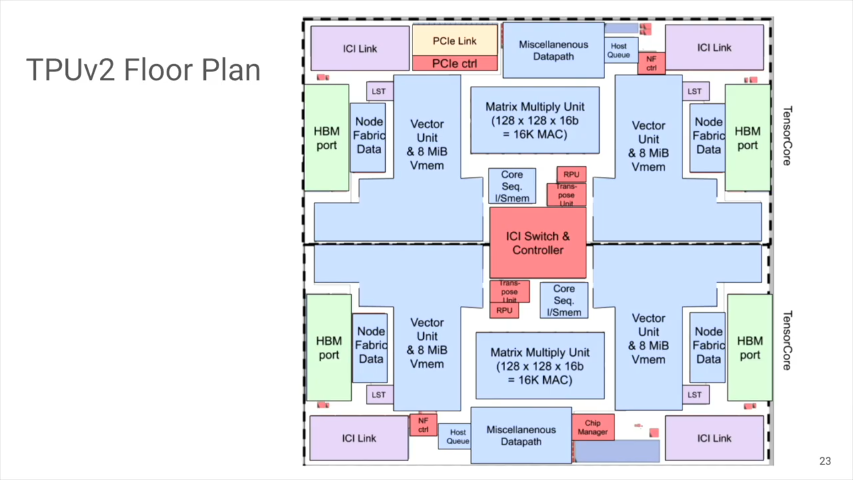
この図をベースに、ブロック間の接続を妄想してみました。

VPUは4個に見えますが、RAMの容量が半分なので、2個を分割しているみたい。このスライド(図は上記の記事のURLを参照しています)

このスライドに、
2 slots that queue data to/from Matrix Multiply Unit and Transpose Reduction Permute units とあるので、Transpose Reduction Permute UnitはMXUと同じ数だと。。
命令は、322ビットのVLIW命令で、64K個の専用メモリがあるようですね。基本的には32ビットでスカラーのレジスタが32個、メモリが4K個、ベクターレジスタ(32bit x 8 = 128bit)が32個、メモリが32K個。。。ベクターのロードとストアは1個づつ。
Google TPU v3では、
TPUv3は、TPUv2と同じテクノロジを使っています。違いは、
クロックレート、ICIバンド幅、 HBMバンド幅、1.35倍に増加
1チップで、コアあたりのMXUを1から2に増加
ダイの大きさは6%しか増えていない
結果、消費電力1.6倍になったので、液冷を使用
HBMのメモリ容量を2倍にして、コアあたり16GiBに
システム全体では、256から1024チップに増加
ということなので、こちらも妄想した。

ボード上のチップ間の接続は、2Dトーラスということなので、こんな感じかな?
