@Vengineerの戯言 : Twitter
SystemVerilogの世界へようこそ、すべては、SystemC v0.9公開から始まった
今週は、Intelを昨年やめたJim Kellerさんが AI Chip company の Tenstorrent に、President and CTO, with a seat on the board という立場でジョインしたというニュースが入ってきました。
下記の記事によると、DECを辞めた後にはCPU関連の会社の2年から4年で移っているみたいですね。。。Intelで何をやったかまでは書いていませんけど。
SPARC以外全部関わっている感じです。
Breaking News: Jim Keller (@jimkxa) has taken a position at AI Chip company @Tenstorrent. Jim is President and CTO, with a seat on the board, and will help drive the next generation of AI hardware. @IanCutress has the details.https://t.co/mAQWnof8It pic.twitter.com/VXCEg3ztat
— AnandTech (@anandtech) 2021年1月6日
で、AI Chip company の Tenstorrent って何?というのが一般的なお気持ちだと思います。
この Tenstorrent については、このブログでも何度か取り上げています。
特に、この2つ。
vengineer.hatenablog.com
vengineer.hatenablog.com
ここから詳細を探っていきます。The Linley Spring Processor Conference 2020 と The Linley Fall Processor Conference 2020 の講演ビデオです。
「The Linley Spring Processor Conference 2020」の講演ビデオで、初めて Tenstorrent の詳細が公開されました。
Tenstorrent: Neurons, NAND Gates, or Networks: Choosing an AI Compute Substrate
www.youtube.com
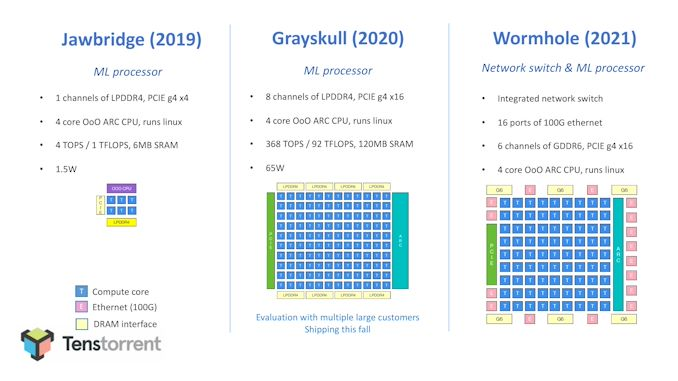
Tenstorrentの最初のチップは評価用チップで 2019年2月の Jawbrigde です。Global Foundary の 14nm で、1ch LPDDR4, PCIe Gen3 x4 で SRAM 5MB, 3.7 TOPSのようです。
次のチップは、2020年1月のGrayskull です。Global Foundary の 12nm で、4ch LPDDR4, PCIe Gen4 x16 で 120MB, 368 TOPSのようです。
下図は講演ビデオの11:28頃の Grayskull のスライドです。右下に High Level Architecture の図があります。横に12個、縦に10個 = 120個 の T (Tensixのこと) と言うブロックが並んでいます。
SRAM 120MB なので、1個当たり 1MB です。評価チップのJawbrigde は SRAM 5MB、3.7 TOPS なので、5個の Tensix が入っているのでしょうか?

368 TOPS は 8bit の場合であり、16bit の場合は 92 TOPS と 1/4 になってしまうのですね。
(12月にLabに届いたとありますね。違うスライドでは1月とありましたが。。。)
下図(10:39頃のスライド)では、Tensix の構造を示しています。5つのRISCコア(このRISCコアのアーキテクチャは公開されていません) + 3 TOPS Compute Engine + Packet Processing から構成されています。最初はこの5つのRISCコアが処理するのかな?と思いましたが、Compute Engine と Packet Processing が実際の処理をして、RISCコアが独立したプログラムで Compute Engine と Packet Processing を制御する感じですね。
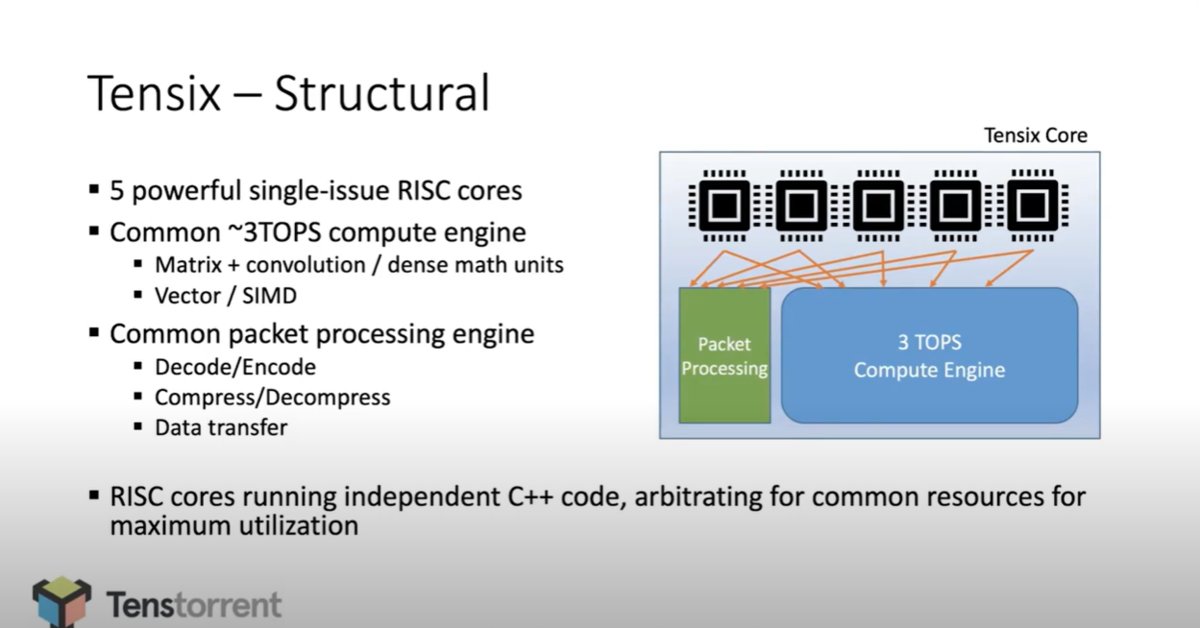
Tensixコアでの処理の流れとしては、Tesnixコアに入ってきたパケットはSRAMにストアされ、Un-Packetize 後、Compute Unit に流し込まれて、Compute Unitにて処理後、Packetizeされ、SRAMに書き込まれています
下図(10:51頃のスライド)では、Tensixコア間の接続を説明しています。Tesnixコア間は double 2D torus NoC で接続されています。縦方向の接続はあるんですが、横方向の接続は無い感じですが、間違えかな。

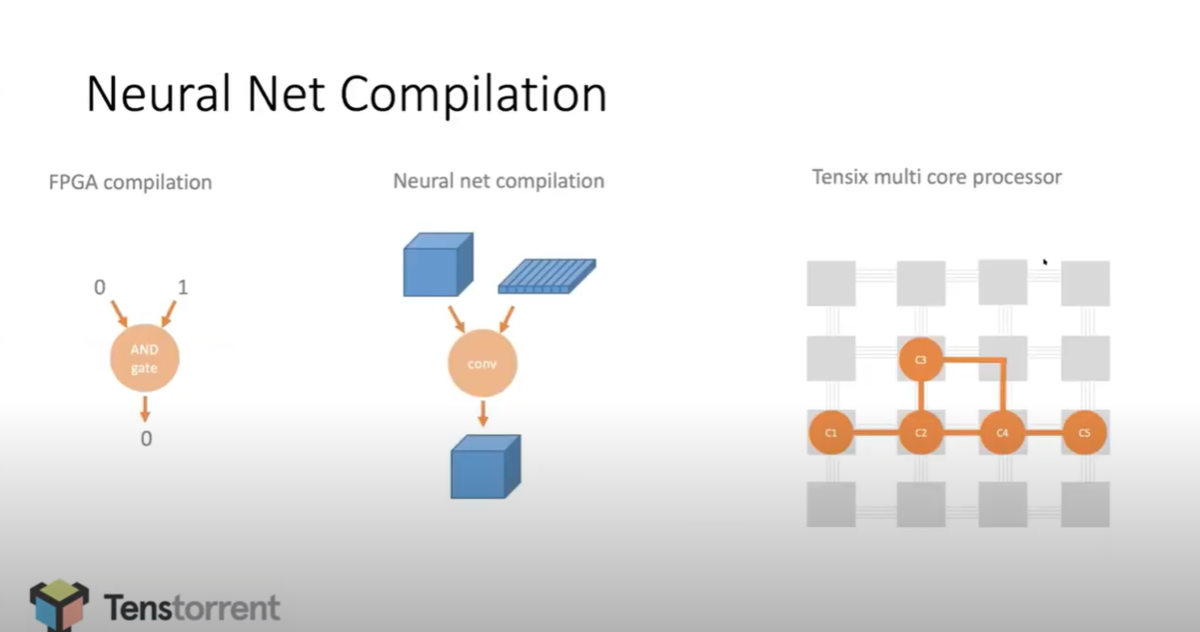
下図(11:46頃のスライド)では、FPGA compilation、Neural net compilation、Tensix multi core processor の比較をするものです。
右図が Tensix multi core processor のもので。 C1 => C2 => C3/C4 => C5 のデータフローっぽい構造になっています。
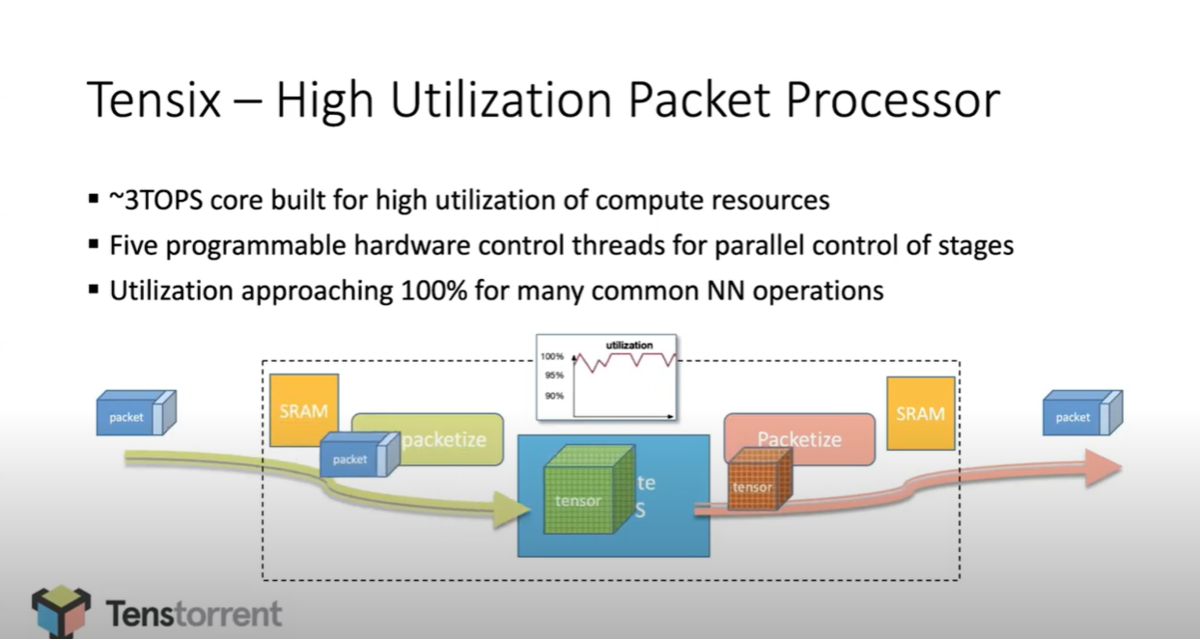
下図(13:31頃のスライド)では、Batch Size を 1 にして、low latency として利用したケースで、120コアを複数個(この場合は5つ)の塊( 32cores, 32cores, 32 cores, 16 cores, 8cores)に分割し、その塊をクラスタとして扱い、各クラスタで特定の処理をする感じの図っぽいです。

一方、下図(19:27頃のスライド)では、Batch Size を 20 にして、high throughput として利用したケースで、12コアの10個クラスタに分割して、各クラスタで 2 Batch の処理をする感じの図っぽいです。

この2つのスライドから Tenstorrent のチップは、チップ内の120個のTesnixコアをクラスタに分割して、そのクラスタを1つの単位で処理をする感じ。
これって、大みそかにブログに書いた「2020年を振り返る」の Cerebras、Graphcore、Samba Nova などのデータフロープロセッサの仲間なんですよ。(ブログにも、tenstorrent も書いています)
vengineer.hatenablog.com
下図(16:11頃のスライド)は、Software Stack Overview です。AI Chip なので、入力は PyTorch/ONNX のモデルです。Grayskullは Inference 用チップなので、学習済みのモデルを入力して、そのモデルを Front End => Opt Stage 1/2 (Optimizer) => Back End でチップ内のコアの命令に変換しています。Back End にて、Map to low-level HW primitives and layouts とあります。やっぱり layouts は必要なんですね。そうですよでデータフロー型なのでデータの流れによって各コアをどのように配置配線すればいいのかは必要ですね。
この部分とRun-time engineのところはハードウェアに依存するところですね。

下図(このスライド、どこからの引用なのかしら)は、最初のAnadtech の記事の中にもありましたが、
現在のチップ(Grayskull)である Inference 用で、現在開発中の Wormhole が学習用のようです。Grayskull では、チップ間接続用にインターフェースはないのですが、Wormhole では 16ports の 100GbE がついています。外部メモリは LPDDR4 x 8ch から GDDR6 x 6ch になっています。評価用のチップ、 Jawbrigde には 6個の Tensix が入っているようですね。
それから、4 core の Out of Order の CPU は、Synopsys の ARC で Linux が走るとありますね。
開発中の Wormhole は、100GbE にてチップ間を接続するようですが、どんな感じに接続するかは下図(9:12頃のスライド)にありました。
Moduleを 2U system に16個載せて、その 2U を 21 個 (42U Rack) にして、Rack を何本も立てる感じ。1U ではなく、2U なんですね。SambaNovaのDataScaleでも 2U なのでそんなもんなんですね。
ちなみに、SambaNova は、2UにCardinal SN10 RDUが2チップ + たぶんそれなりのDRAM(機能的にはTBオーダーのメモリとありますが)
「The Linley Fall Processor Conference 2020」の講演ビデオ、「Tenstorrent: Relegating the Important Stuff to the Compiler」では、いろいろな情報が更新されています。
www.youtube.com
評価用チップのJawbrigde (2019) のざっくりブロック図も載っています。「The Linley Spring Processor Conference 2020」の講演ビデオの中では、1ch LPDDR4, PCIe Gen3 x4 で SRAM 5MB, 3.7 TOPSとありましたが、こちらのスライドでは 4 TOPS / 1 TFLOPS(16bitは8bitの1/4の性能)。6MB SRAM で、6つの Tensix core なので、1コアで 1MB ですね。Grayskullも 1コアで 1MB なので、Tensix コアそのものの変更はなさそうですね。コア数の変更と、DRAMおよびPCIe I/F の変更だけそうですね。

下図(2:15頃)のスライドでは、Wormhole (2021) のざっくりブロック図です。9 x 8 = 72 コアで、Grayskull の 120 コアよりかなり少ないですね。プロセスが Grayskull と同じ GF12 nm だと、減らしたコアの部分の面積に 100GbE x 16 ports を置いたんでしょうかね。

下図(9:24頃)のスライドでは、ML SOFTWARE STACK では、COMPILER が COMPUTE FIRMWARE と CONNECTIVITY FIRMWARE に分けて処理していますね。
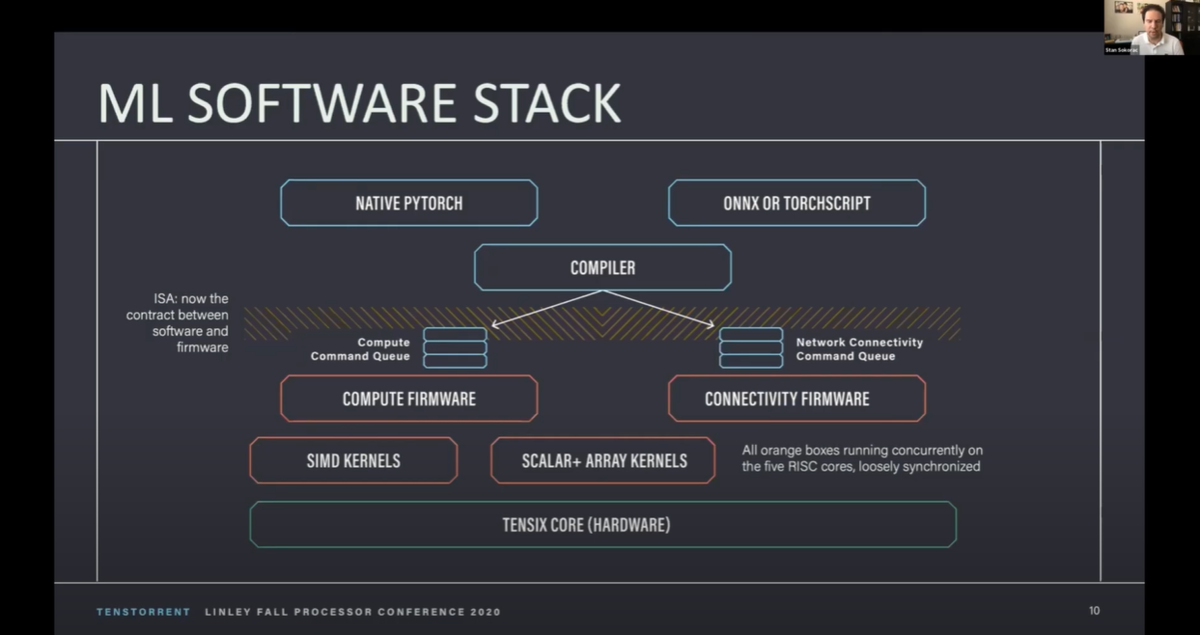
右下にある図の中の Tensor Manipulation Instructions の部分が CONNECTIVITY FIRMWARE に対応するんでしょうかね。
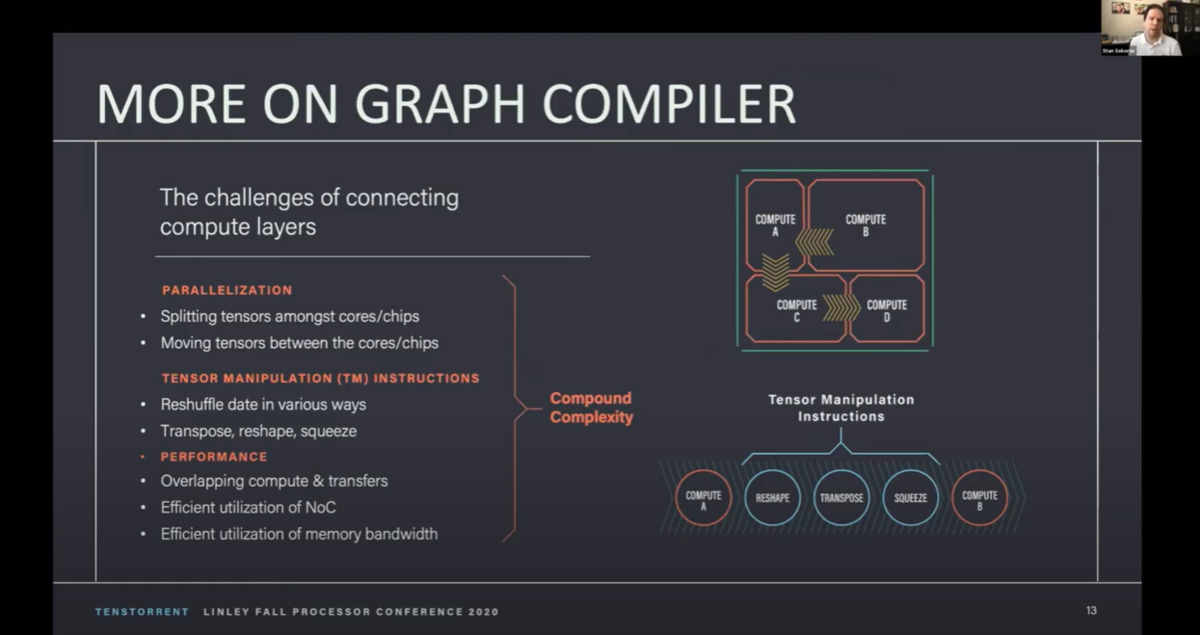
下図(16:19頃)のスライドでは、MORE ON GRAPH COMPILER では、上の図の 真ん中の 青い丸に関してはパケットを分割して、データ移動をスケジュールする感じになっていますね。
Tenstorrent のチップのポイントは、データ移動をパケット化して、スケジューリングするところっぽいです。
これ、実は非常に重要で、RESHAPE/TRANSPOSE/SQUEEZEを Compute 側でやると演算器って全く使わないので勿体ないのです。そのためにこのような演算器を使わないものは 別途並列にできるものにやらせることで演算器の効率を上げる工夫をしているんですよね。

P.S
Tenstorrent のチップは、データフロー型なので、コンパイラエンジニアだけでなく、FPGAの配置配線ツールのノウハウも必要だねと思っています。
いつものように、LinkedInで調べてみたら、なんと、トロント大学出身者が多いこと。
それから、Intel、Altera、AMD から Tenstorrent に移った人も多いようです。ベンチャーとは言っていますが、実際に働いている人はその道のプロフェッショナルが多いということですね。
ハードウェアの場合、大学・大学院時代に創業というのはほぼ無理で、実際に半導体開発やコンパイラ開発を実務でやってきた人を集めないとまともなものは作れないと思うので。