@Vengineerの戯言 : Twitter
SystemVerilogの世界へようこそ、すべては、SystemC v0.9公開から始まった
はじめに、
Google AIのブログにアップされたこのブログ「Machine Learning for Computer Architecture」
Google AI Blog: Machine Learning for Computer Architecture
人間が決めていたAIアクセラレータのアーキテクチャをMLにて決めるというもの。
1月18日の
vengineer.hatenablog.com
の「Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices 」でも同じような感じで、PE、MAC、NoC、PE Architecture、PE SIMD Support、Global Buffer Size、Areaでの検討をやっているので、比較すると面白いかもしれませんね。
Apollo: Transferable Architecture Exploration
ブログの大本の論文は、「Apollo: Transferable Architecture Exploration」Apolloの対象はエッジ用アクセラレータ。
arxiv.org
探索の対象としたモデル
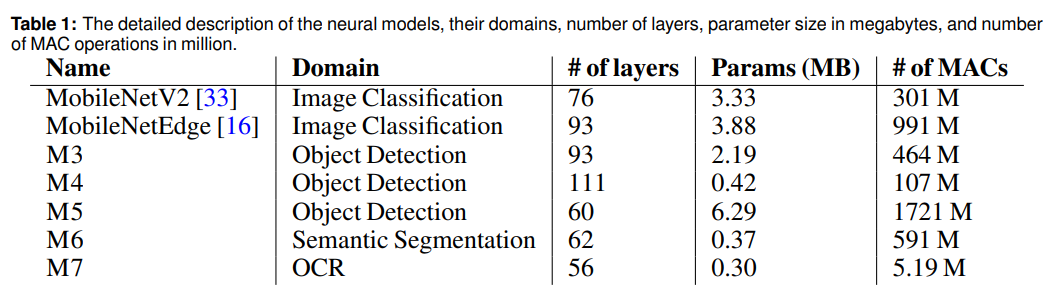
下表(論文から引用しています)のようなモデルに対して、コンピュータアーキテクチャを探索しているようです。MobileNetV2、MobileNetEdge以外の M3からM7については具体的な名前は付いていないものの Layers、Params、# of MACs を見る限り、MobileNetV2やMobileNetEdgeに比べて大幅な増加がみられないのでエッジ側のコンピュータ・アーキテクチャを決めたいのかなと思いました。
評価関数
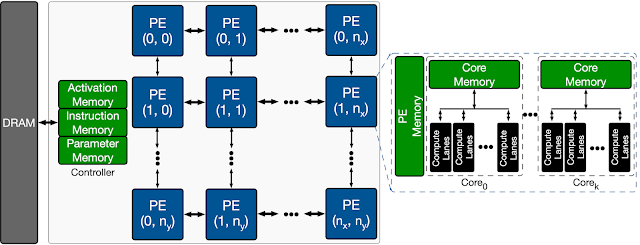
テンプレートとなるAIアクセラレータのアーキテクチャは下記の図(ブログから引用しています)です。この図は論文にはありません。チップ外にはDRAMが付いているのでパラメータがそれなりに大きくなっても使える感じのアクセラレータを想定しているんでしょうね。DRAMからController内のメモリに、Activation用メモリ、命令用メモリ、パラメータ用メモリがあり、これらのメモリは各PEが共通して使用する。各PEには複数のコア(メモリ)とコアで共有して使うPEメモリがあります。
論文には下表のようなパラメータ(上記の図の各構成要素をパラメータにしている感じ)を変えて、AIアクセラレータのアーキテクチャを探索したようです。最後の I/O Bandwidth は外部にDRAMを接続しているので必要なパラメータだと思います。全体としては、5 x 10^8 ぐらい。。。5000万パターン。。。莫大だ。。。

探索時の評価関数は、下記のように、上記のAIアーキテクチャのパラメータだけでなく、workloads (w) を入力として、面積 と Latency を設定した数値以下にする感じですかね。

最適化戦略
Apolloでは、最適化の方法としては、次の5つを使っています。詳細は省きます。
- Evolutionary
- Model-Based Optimization (MBO)
- Population-Based black-box optimization (P3BO)
- Random
- Vizier
評価
- Single model architecture search
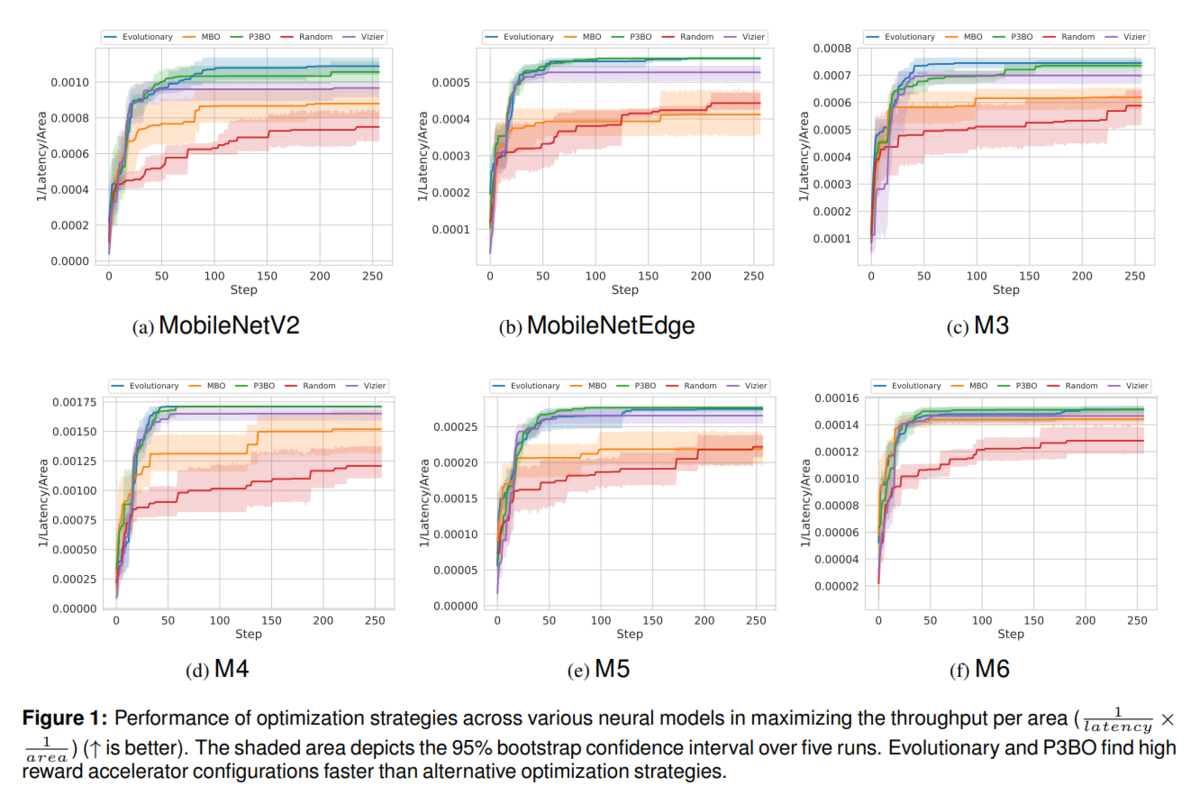
下図(論文からの引用)では、各モデルに対して、各最適化戦略を適応した時に、1/Latency/Area vs step です。Random (赤)が下の方にあるので、上の方にある方がいいのかな?
青(Evolutionary)、緑(Population-Based black-box optimization (P3BO))、紫(Vizier)の順でいい感じ?
- Multi-model architecture search
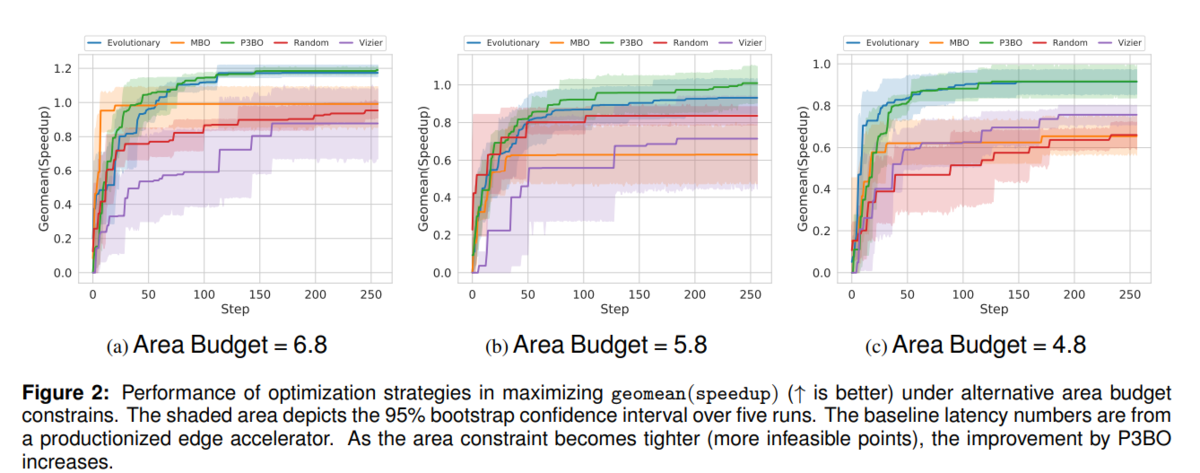
Area Budgetを 6.8, 5,8, 4.8 に変えたの時の図(論文からの引用)。
こちらでは、緑(Population-Based black-box optimization (P3BO))、青(Evolutionary)の順。紫(Vizier)は全然ダメですね。。Area Budget が 5.8, 4.8 だと、1.0 以下ですね。1.0 は、
The baseline runtime numbers are obtained from a productionized edge accelerator.
とありますね。となると、Area Budge は、6.8 ㎜^2 でないと、Google Edge TPUよりはよくならないと。。。
- Transfer learning between optimizations with different constraints
Area Budget 6.8 mm^2 の学習結果を、Area Budget 4.8 mm^2 に転移学習してみたら、下図(論文からの引用)のように、全体的によくなった。特に、ダメだった Vizer が他の戦略(EvolutionaryとP3BO)以上によくなっている。
あれ、もしかしたら、紫(Vizier) がいいのを確認するためのものだったの?
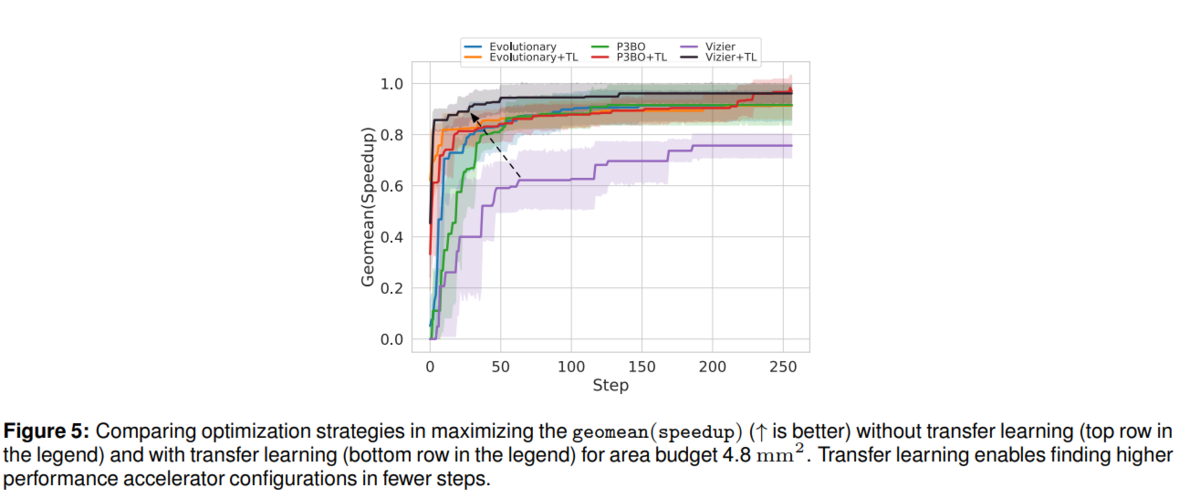
どうしてそうなったかは、
This suggest that Vizier uses the selected trials from the source task more efficiently than Evolutionary and P3BO for optimizing the target task.
ということのようですね。
そして、
We leave extending Evolutionary and P3BO by more advanced transfer learning approaches as future work.
ともありますね。
終わりに、
論文のPage.2に、
In this work, we use an in-house and highly parameterized edge accelerator.
と記載があります。
現在市販されている Google Edge TPUは、32コア(リング構成になっていると妄想)ですが、次のEdgeTPUはDRAM付の2D構成のPEになるんでしょうかね。Google Edge TPUのコアとこの論文のPE(PE内部のコア)には互換性があるんでしょうかね。Pixel 4 に搭載されている Pixel Neural Core だと DRAM(LPDDR4)が付いているので、Pixel 6に搭載する EdgeTPUなんでしょうかね?。
1月2日にこのブログにアップした「ハードウェアを意識したNASからハードウェアの構成も一緒に決めるNASに!」では、ハードウェアの構成も一緒に決めるNAS、NAHASを紹介しました。
vengineer.hatenablog.com
今日紹介した Apollo も同じような感じですね。ApolloはGoogleからですが、NAHASはどこからなんでしょうね。。Google からだと思っていましたが、Apollo が出てきたので、そうじゃないのかな?
AIアクセラレータのマクロ・アーキテクチャーは人間が決めるものだと思いますが、マイクロ・アーキテクチャについては今回紹介したブログ・論文にあるようにMLにて決めた方が良くなるんでしょうね。
人間はより上位のマクロ・アーキテクチャを決めていくしかないんでしょうね。。。辛いと思うか、楽しいと思うかは人それぞれですが、、、実際の半導体に実装できる環境じゃないと、マクロ・アーキテクチャを決めても「絵に描いた餅」なんですけどね。。
最後に、昨日の MobileDets の論文でもそうだったが、
Our results indicate that transfer learning is effective in improving the target architecture exploration, especially when the optimization constraints have tighter bounds
とあるので、転移学習は重要なんだね。。
P.S
Conclusion に、
The evolution of accelerator architectures mandates broadening the scope of optimizations to the entire computing stack, including scheduling and mapping, that potentially yields higher benefits at the cost of handling more complex optimization problems. We argue that such co-evolution between the cascaded layers of the computing stack is inevitable in designing efficient accelerators honed for a diverse category of applications. This is an exciting path forward for future research directions.
とあったので、まだまだ研究は続く。