@Vengineerの戯言 : Twitter
SystemVerilogの世界へようこそ、すべては、SystemC v0.9公開から始まった
はじめに
この記事では、MITの Song Han さんの講演ビデオ(OFA : Once-for-ALL Netowrk ) を観て、そこから得られたものをまとめたものです。
OFA : Once-for-ALL Netowrk とは、
OFA : Once-for-ALL Netowrk の論文としては、Once for all: Train one network and specialize it for efficient deployment
日本語の解説(Qiita)は、こちら。
qiita.com
1つの once-for-all network を training して、その network の sub-nets を specialized することで、large/small/tiny な モデルを Cloud AI/Mobile AI/Tiny AI(AIoT) で動かすと。
ポイントは、
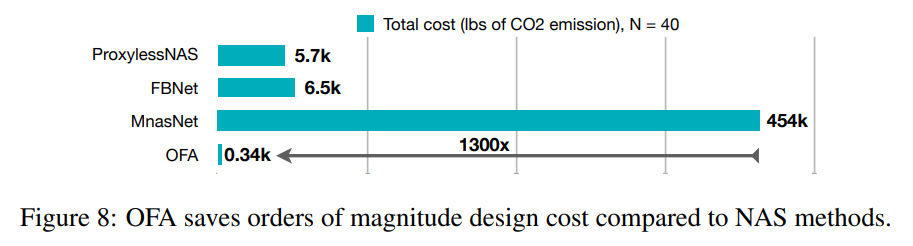
- CO2 Emission が MnasNet よりも 1335倍少ないということのようです。
- 各デバイスに合わせたネットワーク構築の設計が不要になるので、デザインコストがO(N)からO(1)の固定になる。
- 今までのモデルは、Cloud AIからMobile AIまでように探索していたが、once-for-all では Tiny AI (AIoT)も対象にしている。
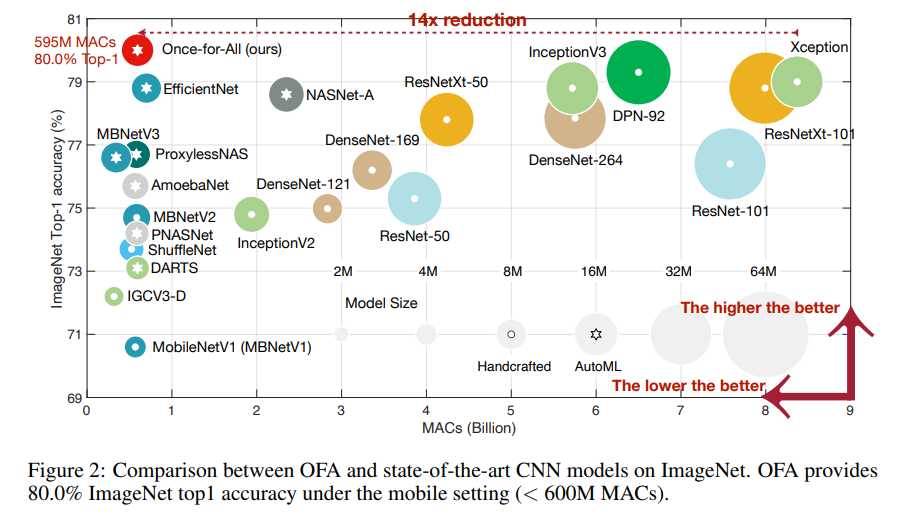
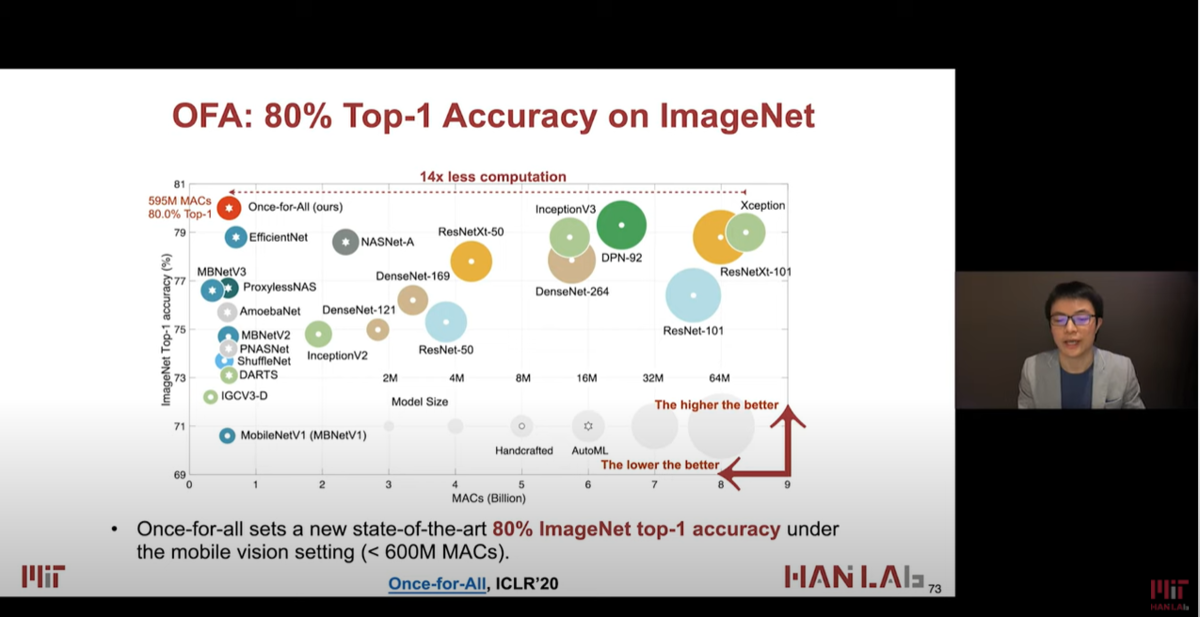
下図は各モデルとの比較。汎用的なモデルとしているので、x軸は Latency ではなく、MACs になっている。
600M MACs以下のモデルの中で最高の精度。。ということを言いたかったので、x軸は MACs なのかもしれない。
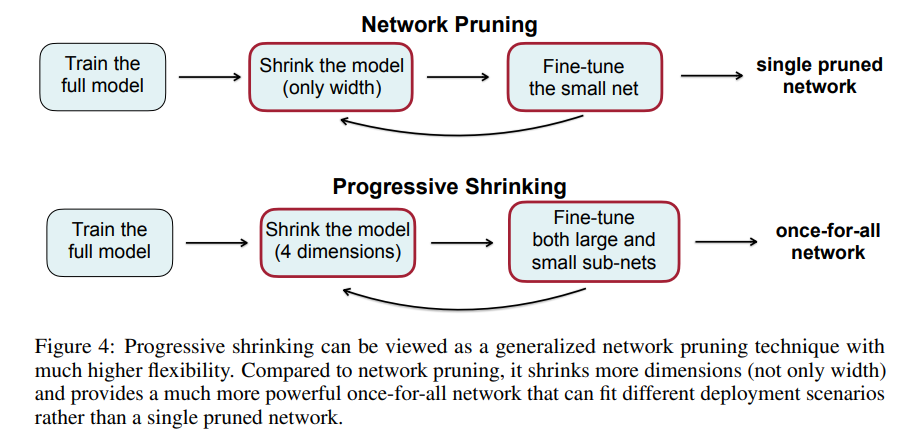
Network Pruningでは、モデルをShrink (widthのみ)して、小さなネットを Fine-tune し、フィードバックをかける。最終的に、1つのpruned network が出来上がるが、
once-for-all network では、モデルをShrink を 4 dimensions で行い、large および small な sub-nets で Fine-tune し、フィードバックをかける。
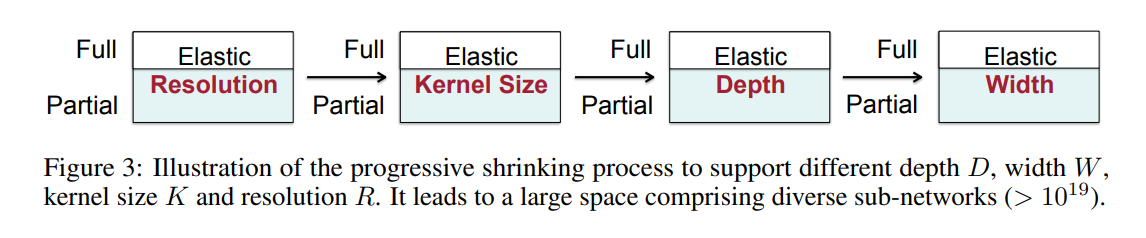
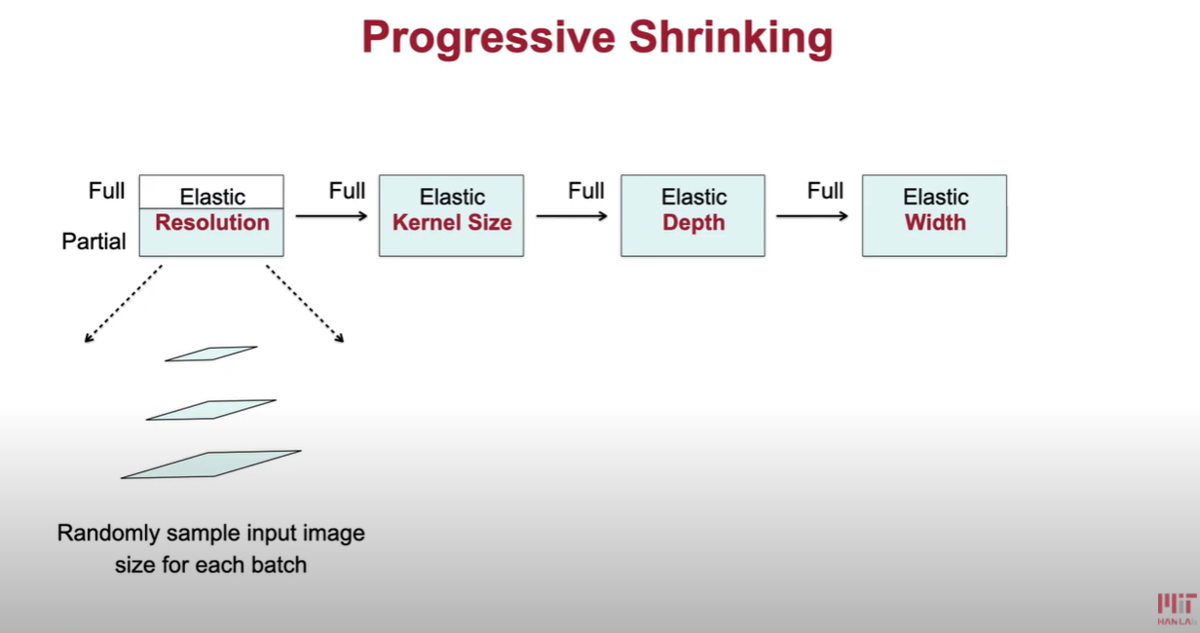
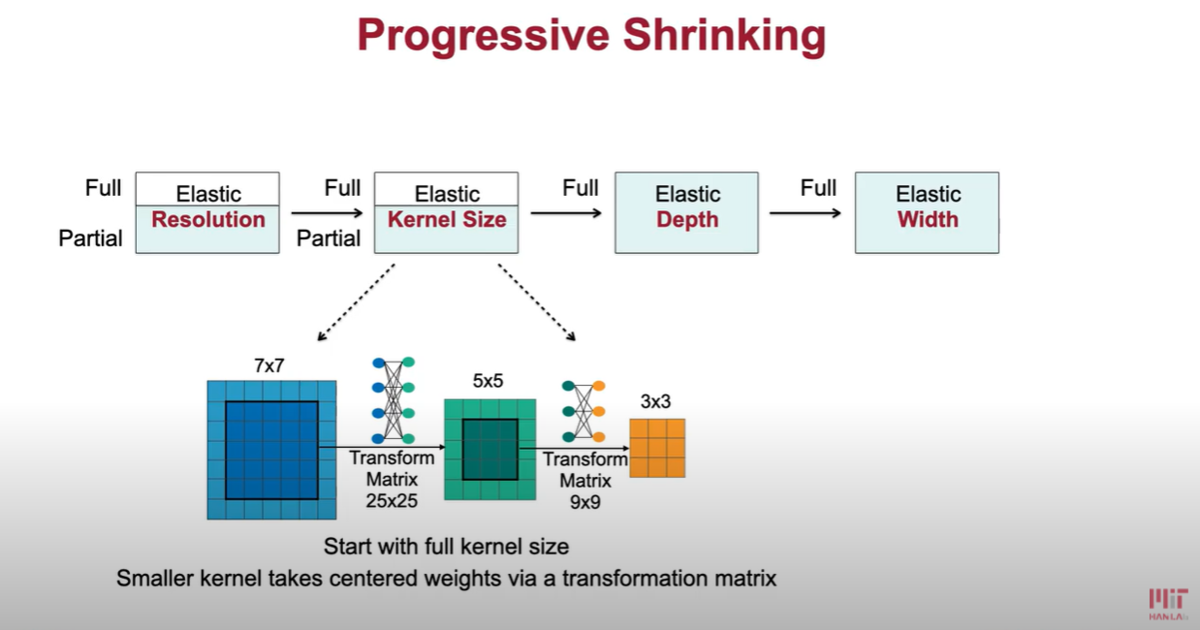
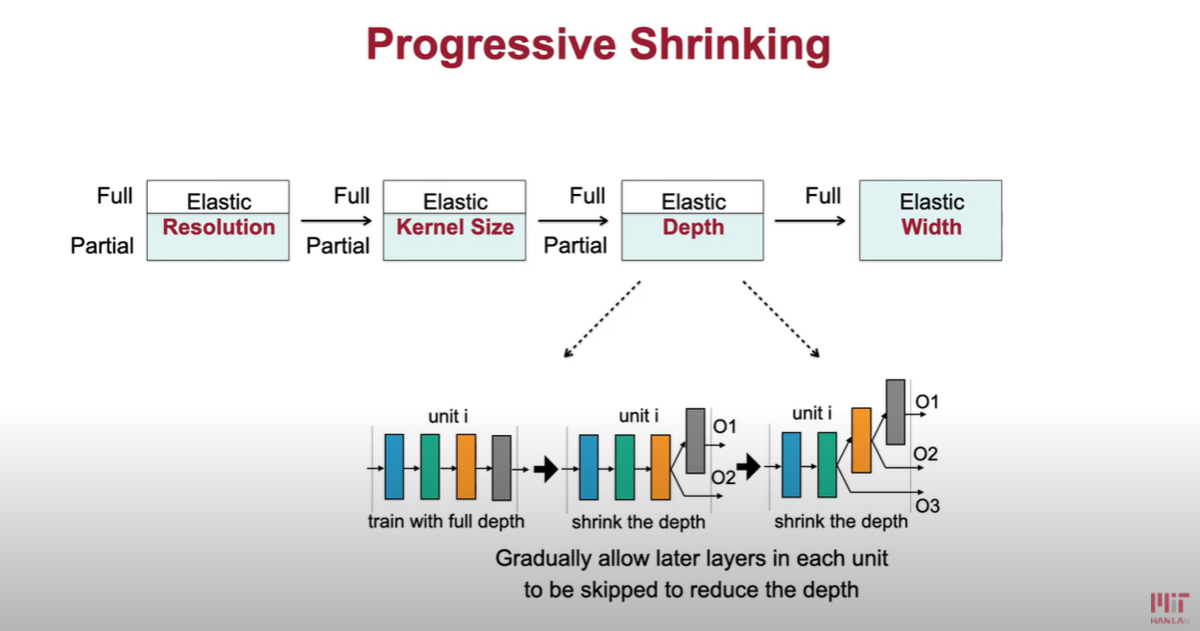
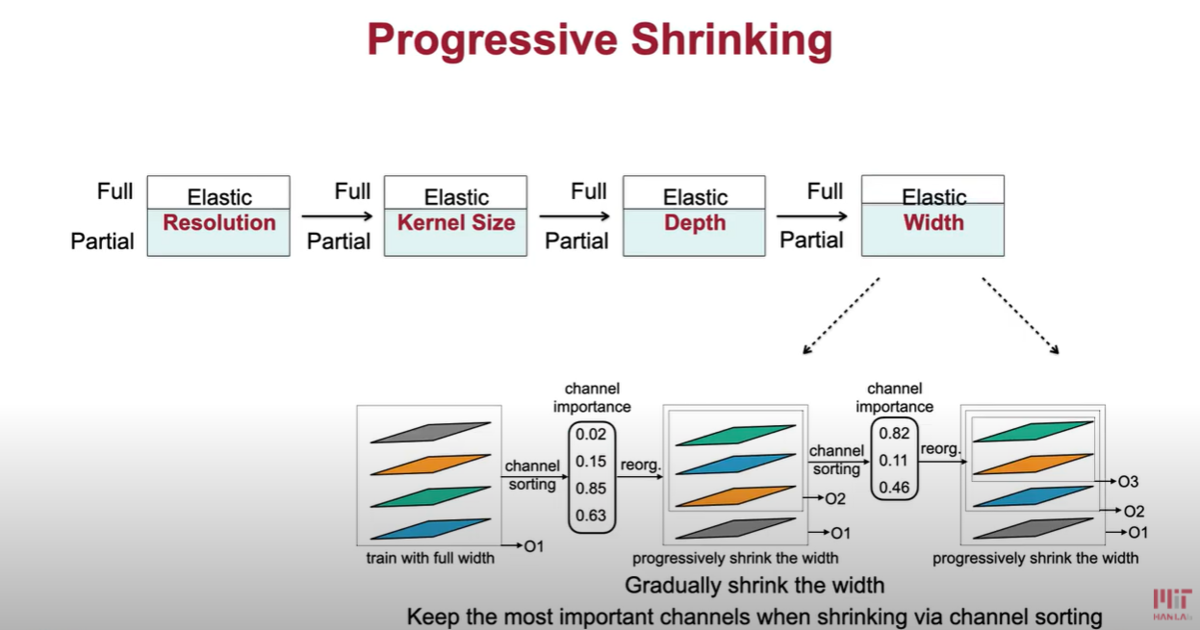
具体的には、下図のように、Resolution => Kernel Size => Depth => Width の 4つのdimention にて Shrink していく。
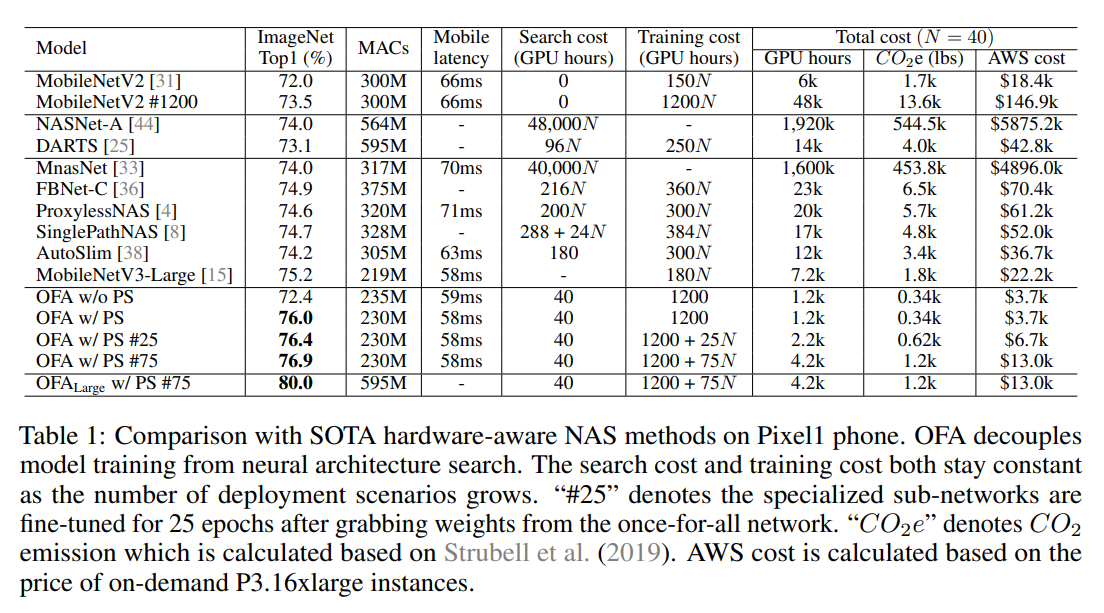
各モデルとの比較:精度、MACs、Mobile latencyの他に、Search cost (GPU hours)、Training cost (GPU hours)、Total costが載っている。
GoogleのNASNet-AやMnasNetはSearch costが48,000N/40,000Nでめちゃくちゃ高い。まさに富豪だからできる力業。
一方、OFA は Search cost は一定で40 hours。Training cost が 1200 hours で 富豪でなくてもできる?いた、Total cost が 3.7Kドルって、3700ドル、40万円なのでそれなりにかかる。
Progressive Shrinking ありなしでは、costは変わらないが、tuningのために epoch 数を増やすと当然それだけ cost が増える。。。
ビデオ:[https://www.youtube.com/watch?v=a_OeT8MXzWI:title=[ICLR 2020] Once for All: Train One Network and Specialize it for Efficient Deployment]
に、Resolution、Kernel Size、Depth、Width の説明があります。
下図はこの論文でのポイントの一つである CO2 emission の比較。富豪の Mnasnet に対して、1300倍少ないと。。。
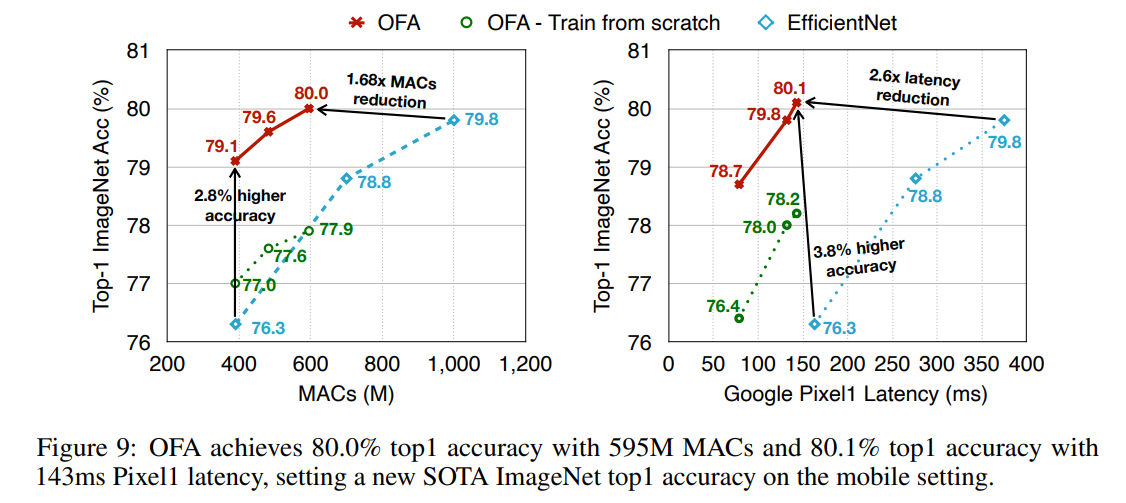
富豪Googleの EfficientNet との比較。MACsを少なくして、精度も向上。Pixel1でのLatencyも向上。。(Pixel1というかなり古いスマホだけどね)
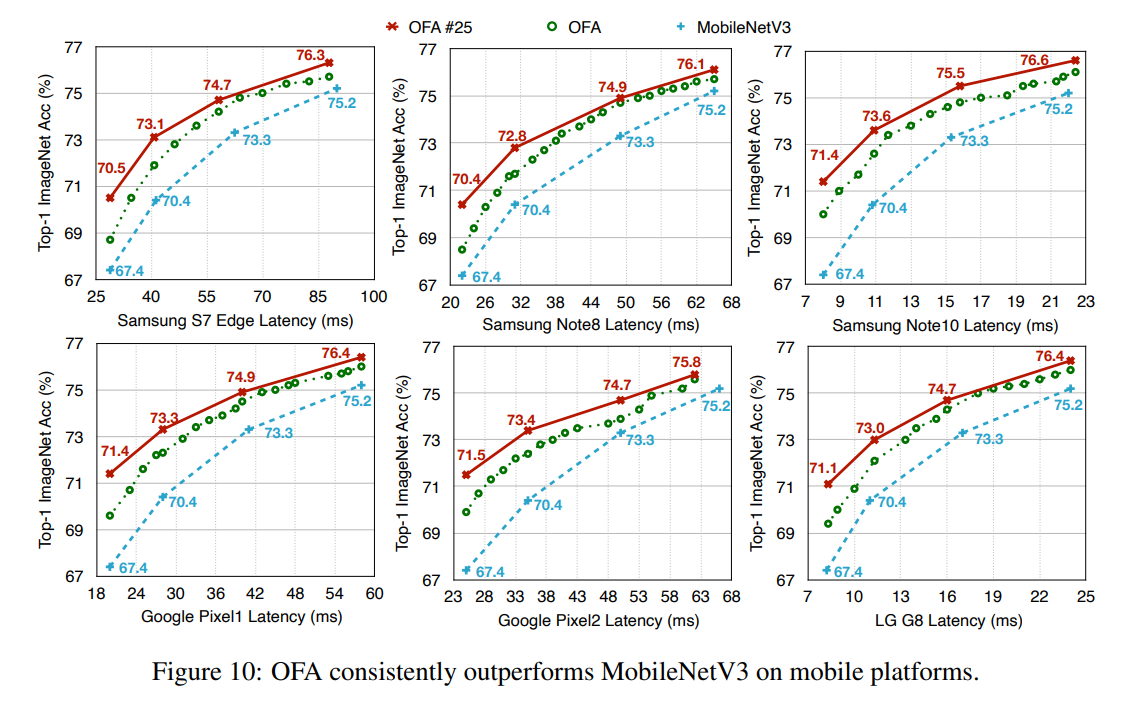
Mobile用の一般的な MobileNetV3 との比較。Latencyが変わらずに、1%程度精度が上がって、25 epoch しているけど、プラス3000ドルかかる。
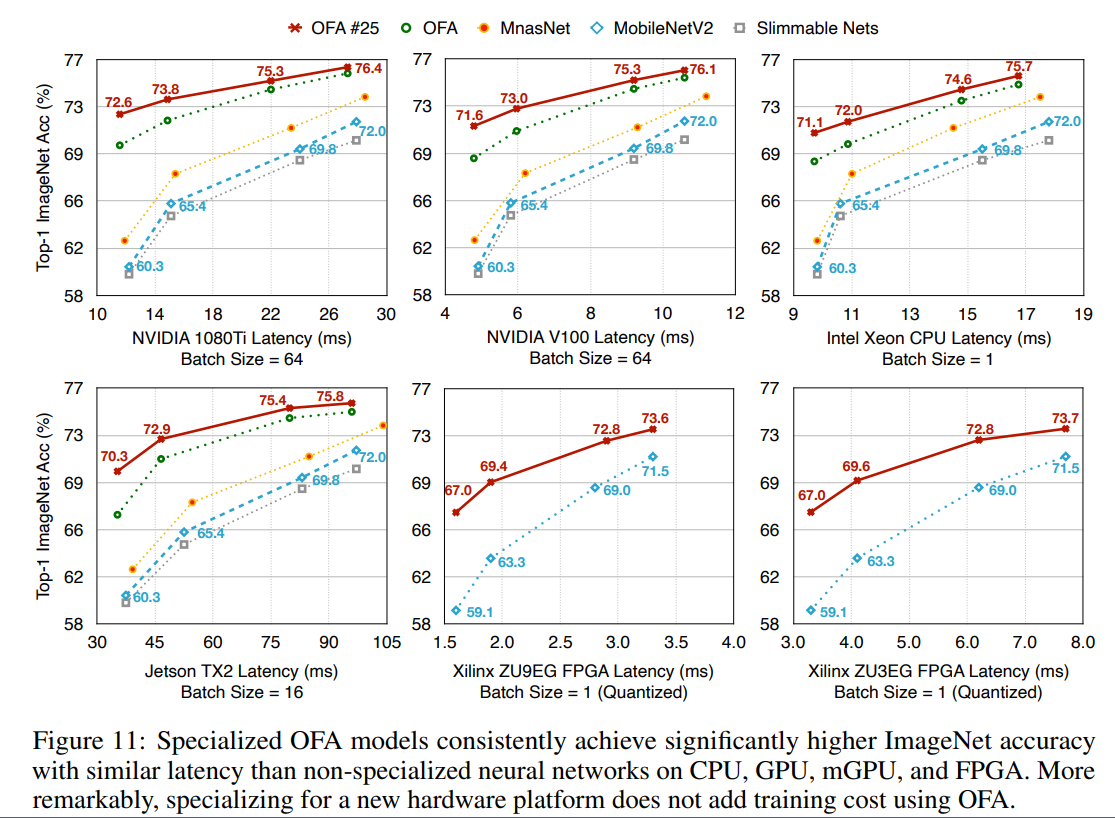
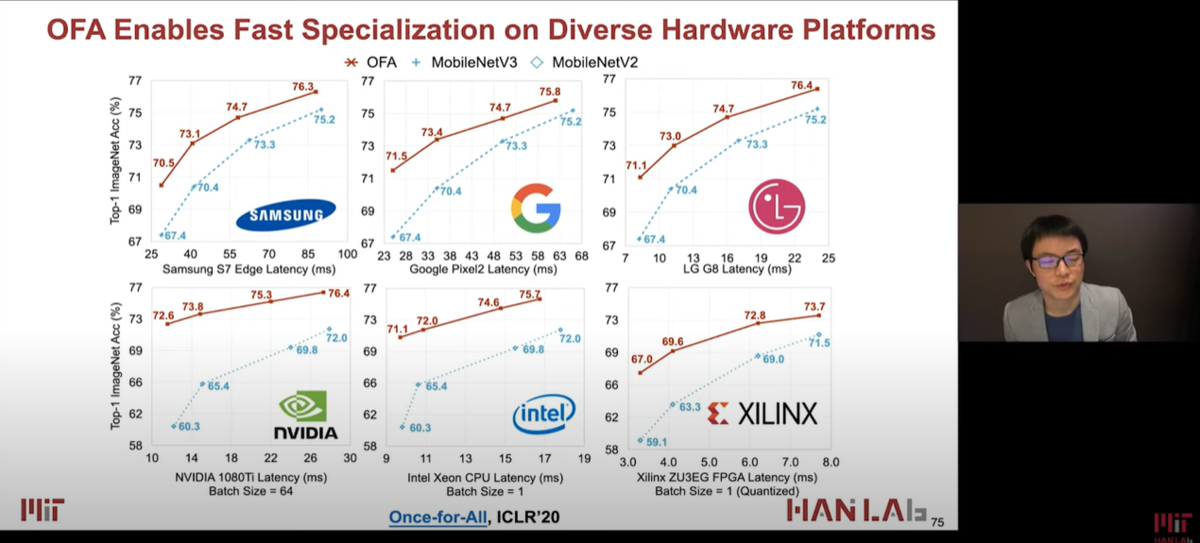
いろいろなハードウェアでの精度とLatency。NVIDIA 1080Ti, NVIDIA V100, Intel Xeon CPU, NVIDIA Jetson TX2, Xilinx ZU9EG, ZU3EG がある。RasPi4あたりも欲しかった。
なんでベースモデルがMobileNetV3なのかなー、と思い、MobileNetV2とMobileNetV3の違いをGoogle君に聞いたら、出てきました。
に詳しく書いてあって、V3はAutoMLにて生成したというこということなんですね。
下記のビデオ:[CVPR 2020 Tutorial] AutoML for TinyML with Once-for-All Network
これには、EfficientNet と MobileNetV3 をベースモデルとして、Once-for-All Network で Re-training しているっぽいです。
www.youtube.com
下記のスライドでは、OFA (Once-for-ALL Netowrk) では、600M MAC/s 以下のモデルで 80% を超える Top-1 Accurary on ImageNet ということです。
下記のスライドでは、いろいろなハードウェア(スマホ、NVIDIA GPU、Intel Xeron、Xilinx FPGA)での Top-1 Accurary が載っています。
下記のスライドは、Once-for-All Network のまとめ

終わりに
最近のモデルは巨大になっていてそのモデルを学習するには、クラウド上のコンピュータリソースを使ってもかなりの時間だけでなく、費用(数万ドルから数百万ドル)もかかります。
NASにていろいろなモデルを探求するどうしても何回も何回も学習するために、時間と費用が必要になってくるわけです。
今回の OFA : Once-for-ALL Netowrk は、1つの once-for-all network を training して、その network の sub-nets を specialized することで、large/small/tiny な モデルを Cloud AI/Mobile AI/Tiny AI(AIoT) で動かすモデルを学習することで、学習の時間と費用を抑えることができるというものです。
Googleなどの富豪環境であれば巨大なモデルの学習を繰り返すことができますが、そうでないところでは、いろいろな工夫で学習の時間と費用を抑える必要があるというわけですね。
また、学習の時間や費用というポイントだけでなう、CO2 Emission という点でもいい、というのを入れたのは何か意味があるのだろうか?
コンピュータリソースを使えば当然、CO2 Emission は増えるのだから。。。
追記)、2021.04.10
tinyML Summit 2021 Keynote Song Han: Putting AI on a Diet: TinyML and Efficient Deep Learningのビデオ
www.youtube.com