はじめに
NVIDIA Research のサイトを眺めていたら、見つけました。
IPA: Floorplan-Aware SystemC Interconnect Performance Modeling and Generation for HLS-based SoCs
SystemC ベースの Floorplanを意識したインターコネクト・パフォーマンス・モデルについて、
IPA
下図は上記の論文から説明のために引用します。
- Directly Connected Links
- Central Crossbar Crossbar
- Uniform Mesh NoC
の3つのインターコネクトのタイプをサポートしているようです。

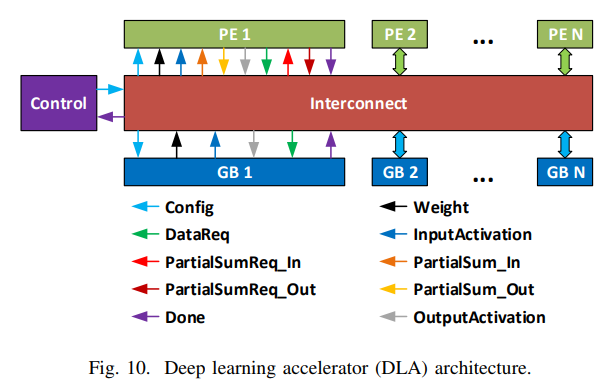
下図は、Deep Learning Accelerator の例です。どうやら、推論用、っぽいです。説明のために引用します。
- PE : processing elements
- GB : an array of global buffers
- Interconnect
の構成で、Interconnect をどのように実装するといいかをモデル化できるということです。
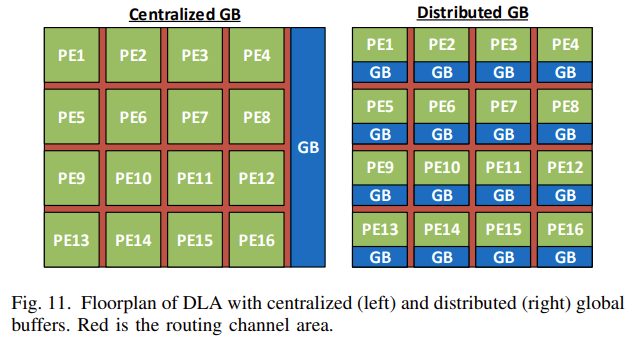
下図も説明のために引用します。左側は Centralized GB (Global Bufferを1つにした場合)、右側は Distributed GB (Global Bufferを各PEに対して、分散した場合)
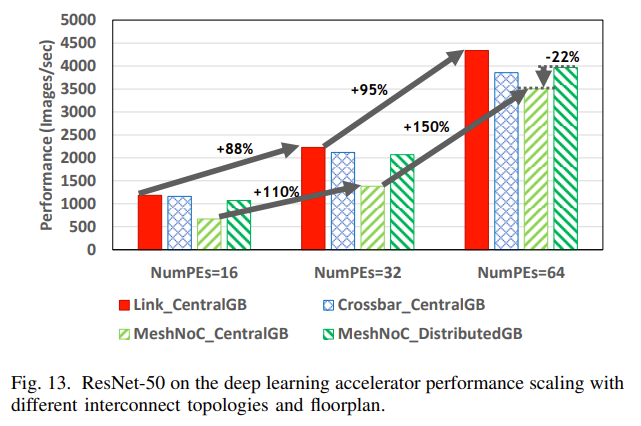
下図は ResNet-50 でのいろいろなInterconnectの評価結果です。説明のために引用します。PEの数が増えると CentralGBの方がDistributedGBの方が性能的にいいようです。
ソースコード
NVIDIA Lab の MatchLib and Connections を使っているようです。
おわりに
NVIDIA では、MatchLib を使っていろいろとやっています。ちなみに、合成ツールは、SIEMENS の Catapult HLS です。