はじめに
昨日、 Gaudi2 のコスパについてみてみました。今日は、Gaudi2 と A100 の性能比較をもうちょっとしてみます。
- Gaudi2 : BF16=400 TFLOP/s, HBM=96GB, 2450GB/s (4.166)
- A100 : BF16=312 TFLOP/s, HBM=80GB, 2039GB/s (3.9)
メモリ帯域とメモリ容量は、Gaudi 2の方がいいですね。
学習になると、1個のデバイスだけでなく、複数のデバイス間のデータ転送が必要です。そこで、x8 構成のものを見てみます。
- Gaudi2 x 8 :
- A100-80GB x 8 => HGX A100 or DGX A100
Gaudi2 x 8
SUPERMICRO が Gaudi 2 を8個載せたサーバー、SYS-820GH-TNR2 を販売しています。
SYS-480GH-TNR2 の USER'S MANUAL も公開されています。
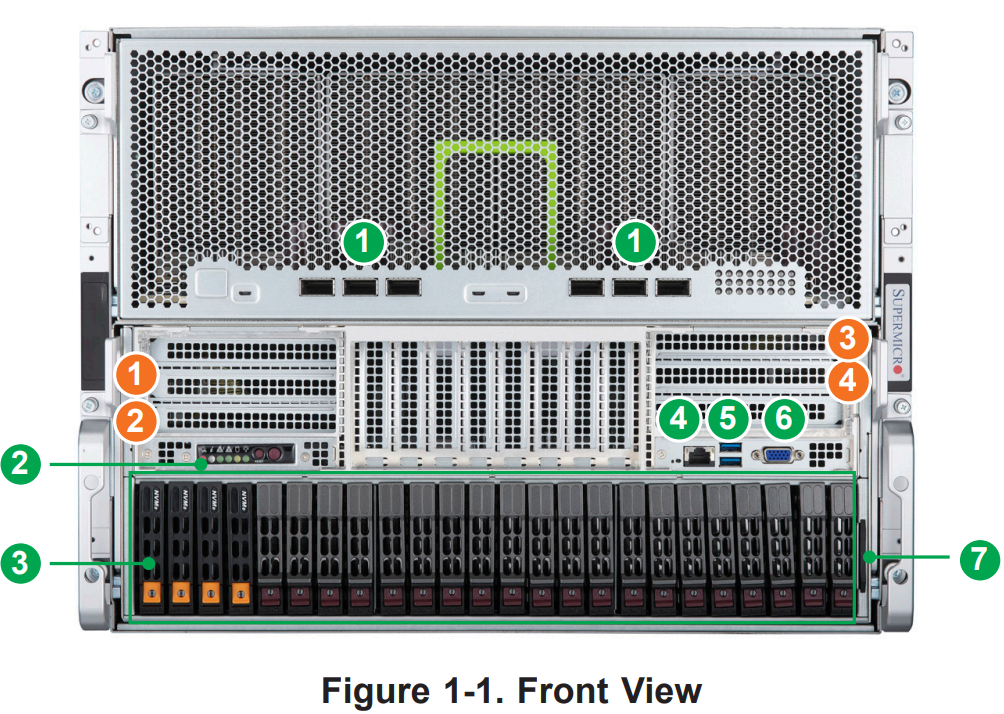
下記は、Front View です。説明のために引用します。⑤がQSFP-DD Ports で 6個の 400GbE が出ています。
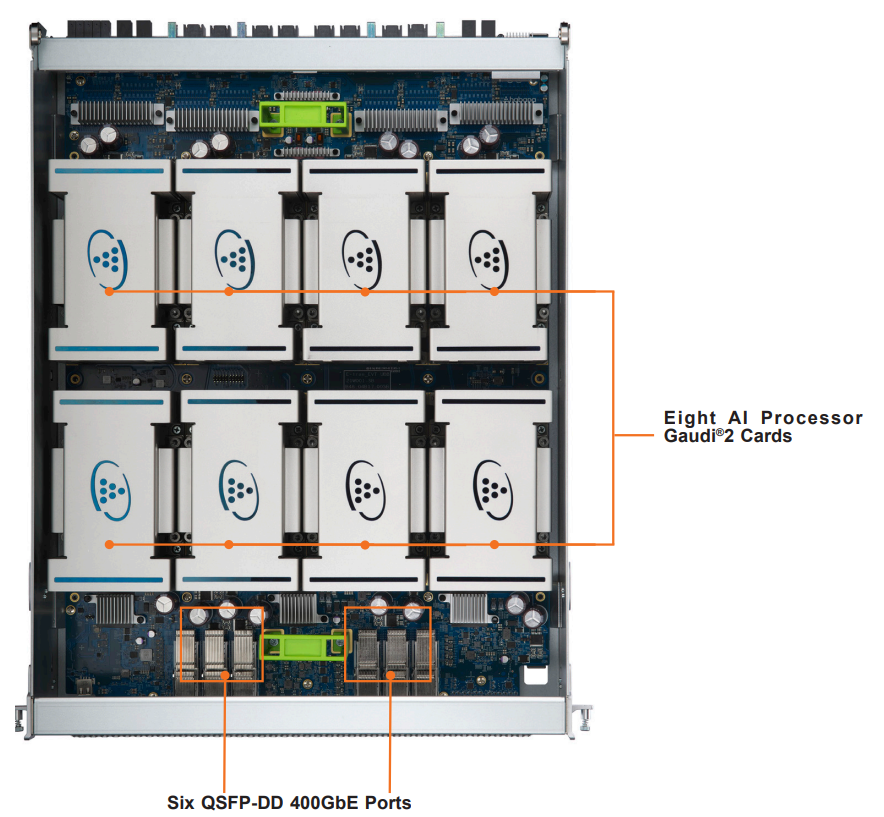
下図は Board を上から見たものです。説明のために引用します。
下図はブロック図です。説明のために引用します。Gaudi 2 間がどのように接続しているかはわかりません。Frontには 400GbE x 6 = 2400 Gbps なので、8個で割ると300Gbpsです。各Gaudi 2 から 100GbE x 3 出ているのでは?

とありました。100GbE x 3 で接続しているっぽいです。
Intel Habana Gaudi2 のサイトに下記の図がありました。やっぱり、21 x 100GbE になっていますね。

Gaudi x 8 : SYS-420GH-TNGR
Gaudi 版のSYS-420GH-TNGR もあります。
SYS-420GH-TNGR の USER'S MANUAL も公開されています。
下記は、Front View です。説明のために引用します。⑤がQSFP-DD Ports で 6個の 400GbE が出ています。

下図は Board を上から見たものです。説明のために引用します。

下図はブロック図です。説明のために引用します。CPU Module から PCIe Switch 経由で Gaudi と接続しています。また、PCIe Switch 間も接続しています。
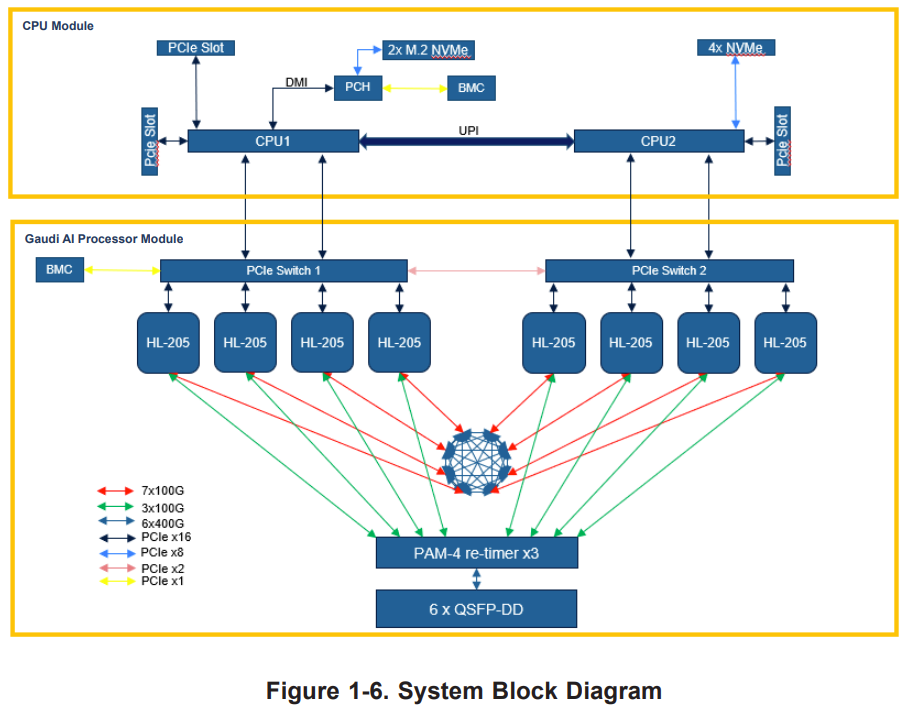
Gaudi からは (7 + 3) x 100GbE が出ています。 7 はボード上の7個のGaudiとそれぞれ 100GbE で接続しています。3 は PAM-4 re-timer x 3 に経由で 6 x QSFP-DD (3 x 8 = 24 x 100 GbE = 6 x 400GbE) で外に出ています。
A100のNVLINKは?
A100のNVLINKは、v3 で 25GB/s x 12 です。200 Gbps x 12 = 2400 Gbps。これは、Gaudi 2と同じです。
NVIDIA DGX A100 User Guide にブロック図が載っています。説明のために引用します。各A100から6つのNVSwitchに2組のNVLINKで接続しています。
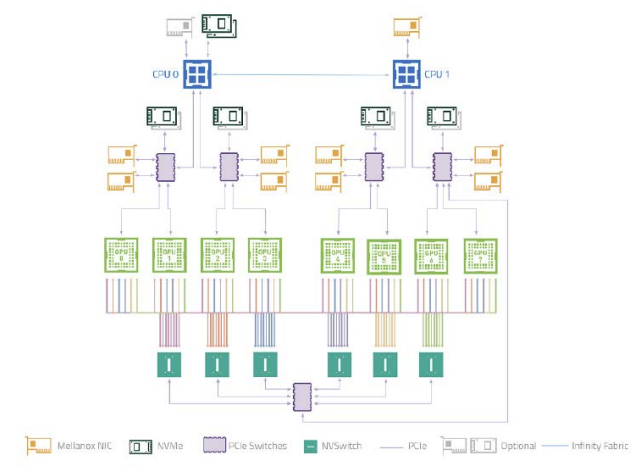
DGX A100の場合は、ノード内は必ずNVSwitch経由接続しています。
おわりに
Gaudi 2は、24 x 100GbE (300GB/s)。A100はNVLINK v3(25GB/s x 12 = 300GB/s)と同じですが、ボード上での接続方法が違います。
8x の構成では、Gaudi 2 の場合は、21 x 100GbE = 2100 Gbps、DGX A100 の場合は、25GB/s x 12 = 2400 Gbps
また、Gaudi 2 の場合は、Gaudi 2間は 3 x 100GbE ですが、DGX A100 の場合は 最大 25GB/s x 12 = 300GB/s で転送ができます。そして、Gaudi 2は 24 ports に対して、A100 は 12 ports なので転送効率は A100 の方がよさそうです。。