はじめに
Intel Habana Gaudi 2 と NVIDIA A100 の比較について、昨日のブログに書きました。
計算機のBF16/FP16のFLOPsやPackage間での転送帯域には大きな違いがないのに、A100の方が速いよねと。
そこで、NVIDIA A100/H100, AMD MI250X/MI300X, Intel Habana Gaudi 2/Gaudi 3 について、振り返ってみたいと思います。
NVIDIA A100/H100, AMD MI250X/MI300X, Intel Habana Gaudi 2/Gaudi 3 の比較
下図は、ブログ「Gaudi2は、コスパがいい?」の中で紹介した記事「LLM Training and Inference with Intel Gaudi 2 AI Accelerators」から説明のために引用します。
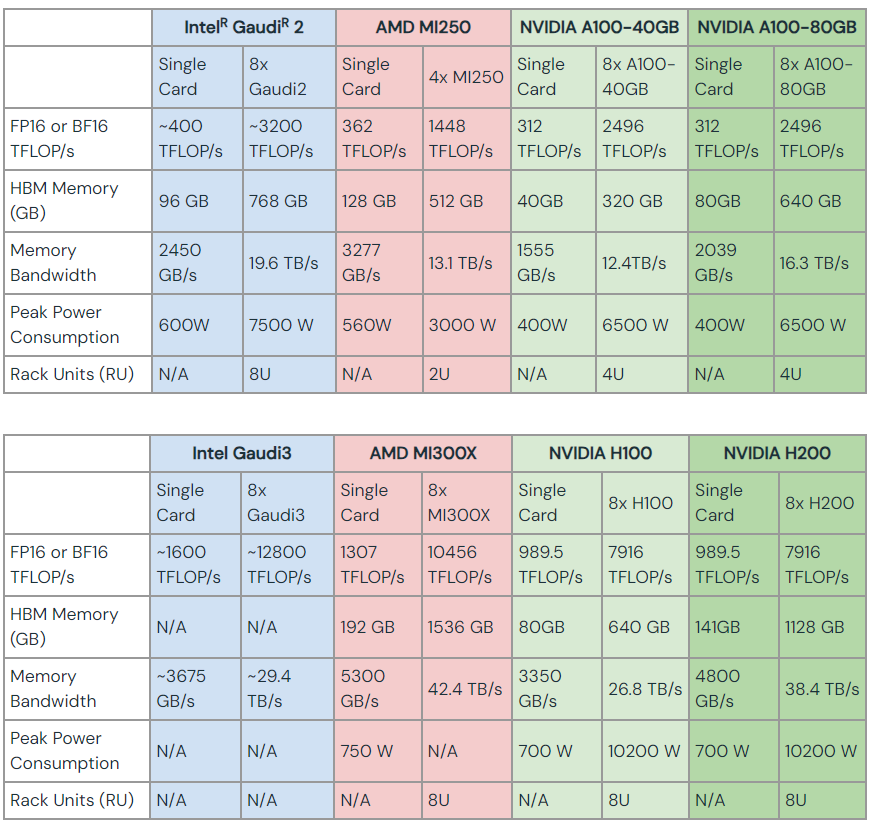
この図に無いのは、Packageと外部との転送帯域の値です。
下記の転送帯域は片側です。
- NVIDIA A100 : NVLink v3 : 25GB/s x 12 = 300GB/s
- NVIDIA H100 : NVLink v4 : 25GB/s x18 = 450GB/s
- AMD MI250X : 50GB/s x 7 = 350GB/s
- AMD MI300X : 64GB/s x 7 = 448GB/s
- Intel Habana Gaudi 2 : 24 x 100Gbps = 2400Gbps = 300GB/s
- Intel Habana Gaudi 3 : Gaudi 2 x 1.5 = 36 x 100Gbps = 3600Gbps = 450GB/s
こうしてみると、
でPackageと外部との転送帯域はほぼ同じです。
Node内を見てみる
- NVIDIA HGX A100/DGX A100 : 各A100は NVSwitch v2 x 6を経由して、他のA100に接続している
- NVIDIA HGX H100/DGX H100 : 各A100は NVSwitch v3 x 4を経由して、他のH100に接続している
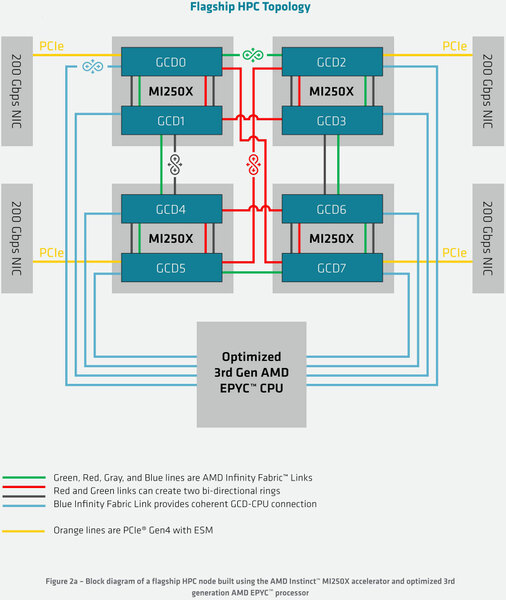
- AMD MI250X : 下図(ここでは、1組~2組のInfinity Fabricにて接続している)
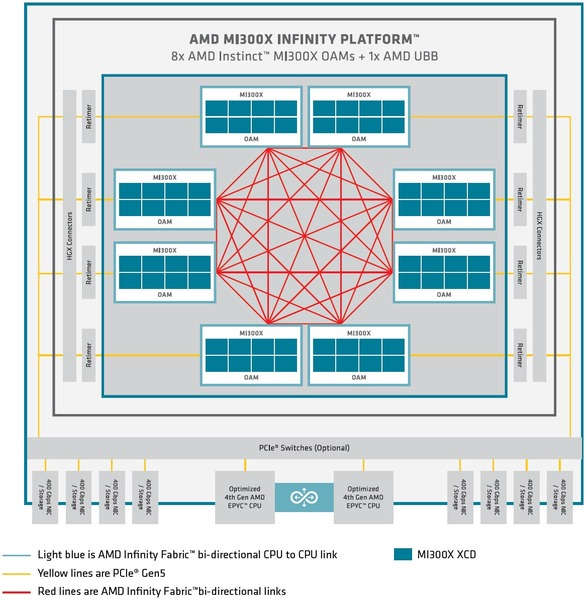
- AMD MI300X : 下図(ここにあるように、各MI300Xとは1組のInfinity Fabricにて接続している)
- Intel Habana Gaudi 2 : 一昨日のブログ「Gaudi2は、コスパがいい?」に書いたようにGaudi 2間は 3 x 100Gbps で接続。
- Intel Habana Gaudi 3 : まだ発表されていないが、基本的には Gaudi 2 と同じ想定
大きな違いは、NVIDIAは NVSwitch にて、Package間の接続を自由にできるということである。AMDやIntel Habana の場合は、決まった方法で繋がっている。
おわりに
NVIDIA A100/H100、AMD MI250X/MI300、Intel Habana Gaudi 2 の LLM の Benchmark のデータを見て、なんで、NVIDIAが強いのかがちょっとわかった気がします。Package単体での性能ではなく、Node内、Node間の性能が上げられる仕組みとしての NVSwitch がいるのだと思うようになりました。