はじめに
NVIDIA H100に対して、H200の LLM Inference 性能が向上すると、NVIDIAは下記のように言っています。
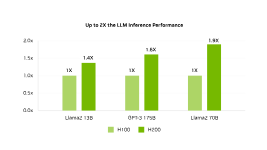
- LIama2 13B で、1.4X
- GPT-3 175B で、1.6X
- LIma2 70B で、1.9X
です。
H100 => H200 になって変わったもの
H100からH200になって変わったのは、メモリです。
- H100 では、HBM3 80GB, 3TB/s
- H200 では、HBM3e 141GB, 4.8TB/s
メモリ帯域が、1.6倍になっています。HBMへのアクセスがボトルネックであるのなら、1.6倍程度までは性能向上になると思います。。。
上記のデータでは、
- LIama2 13B : 1.4X
- GPT-3 175B : 1.6X
です。LIama2 13B なら、80G/141GBの両方に入るので、この1.4倍はメモリの帯域向上によるものでしょうか?
Llama2 13B: ISL 128, OSL 2K | Throughput | H100 1x GPU BS 64 | H200 1x GPU BS 128
とあるので、バッチサイズを2倍にしています。。
GPT-3 175B は、パラメータを4バイトとすると、700GBなのでHBMにはすべてのパラメータを搭載できません。
GPT-3 175B: ISL 80, OSL 200 | x8 H100 GPUs BS 64 | x8 H200 GPUs BS 128
とあります。8つのGPUによる推論のようです。700GB/8 = 87.5GB なので H100の時はHBMには載らないですが、H200の141GBなら載っているのかもしれません。その部分が影響しているかもです。
LIama2 70B は、パラメータを4バイトとすると、280GBなのでHBMにはすべてのパラメータを搭載できません。
Llama2 70B: ISL 2K, OSL 128 | Throughput | H100 1x GPU BS 8 | H200 1x GPU BS 32.
とあるので、バッチサイズを8倍にしています。。
これ、バッチサイズが違うと単純な比較できないですね。
おわりに
うーん、バッチサイズが同じ場合にどうなるかを知りたいです。。。