はじめに
NVIDIAの下記の論文を見直して、気が付きました。
GPGPUのL3 Cacheって、LLMの性能にどのような影響を与えるのか?
グラフを見てみたら、
下図は上記の論文の Figure 9 です。これを見ると、Trainingのところに、Transformerがありますが、Inferenceにはありません。
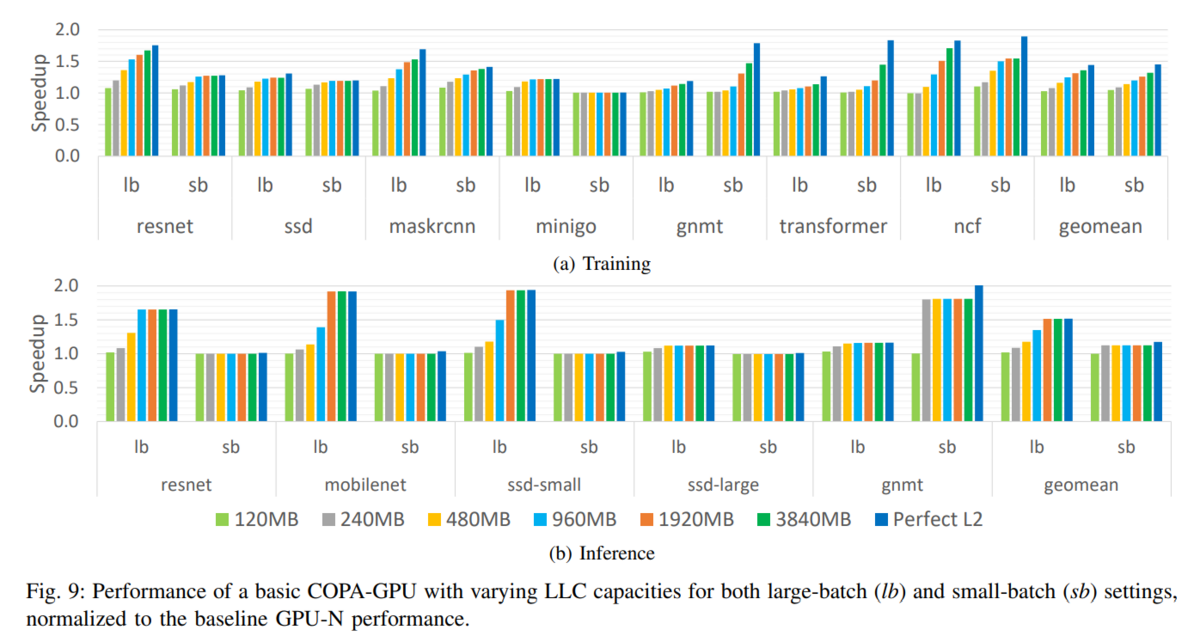
ということは、LLM Inference には、L3 Cache の効果はあまりないということなんでしょうね。
となると、
- L3 Cache有 : LLM Training用
- L3 Cache無 : LLM Inference用
としてプロダクトが作れますね。
この論文を書いていた時は、
- L3 Cache有 : DL用
- L3 Cache無 : HPC用
を想定していましたが、2022年11月の ChatGPT のリリースによって、HPC用なんてやるより、LLM Inference に使えるっぽいことになりそうですね。
そして、B100の妄想
NVIDIA B100の妄想
— Vengineer@ (@Vengineer) 2024年2月11日
この論文(https://t.co/zfhz57YVgT)の
bのケース 3D で Compute die の下に Cache Die を置く作戦。これで Compute die を 2 個。
1 die + L3 Cache 960MB
最初には、B100としてTraining用として出し。
その後に、Inference用が必要になったら、L3 Cache無しを出す。
当たるかな? pic.twitter.com/qQ9ZHOsGcD
おわりに
未来に何が起こるかは、わかりませんが、あまり儲からないと思っていたHPC用の構成が LLM Inference 用として大きな需要を生むことになれば、NVIDIAさん、一粒で2倍美味しい、グリコになりますね。。。