はじめに
先日発表があったCerebras SystemsのCS-3については、下記のブログに書きました。
今日の半導体チップ雑談では、この CS-3 についてお話します。
そして、Cerebrasが Cerebras AI Day 2024 というプライベートイベントを開催し、その模様が Youtube にアップされたのの覗いてみました。
Cerebas AI Day 2024
下記の Hardware Keynot - Sean Lie (CTO and Founder) を見ていきます。
以下の図(スライド)は、上記のYoutubeから説明のために引用します
CS-3
下図にCS-1/CS-2/CS-3の比較です。

コアの数が、850,000 から 900, 000 と微増です。また、on chip memory は 40GB から 44GB に微増です。これはコア数が増えた分なのでしょう。一方、トランジスタ数がが 2.6Tから4Tを爆増しています。
下図は、2枚のスライドのCS-2とCS-3を並べています。上記のCS-2とCS-3でトランジスタ数が爆増している理由が分かります。4-way 16b SIMD が 8-way 16b SIMD になったためです。上記の比較のところにも「Each CS-3 core has 8-wide FP16 SIMD units, a 2x increase over CS-2」と書いたのでそれは想定内です。 16-way 8b SIMD とあるのはこれが入っているのではなく、8-way 16b/16-way 8b ができるSIMDになったということだと思います。
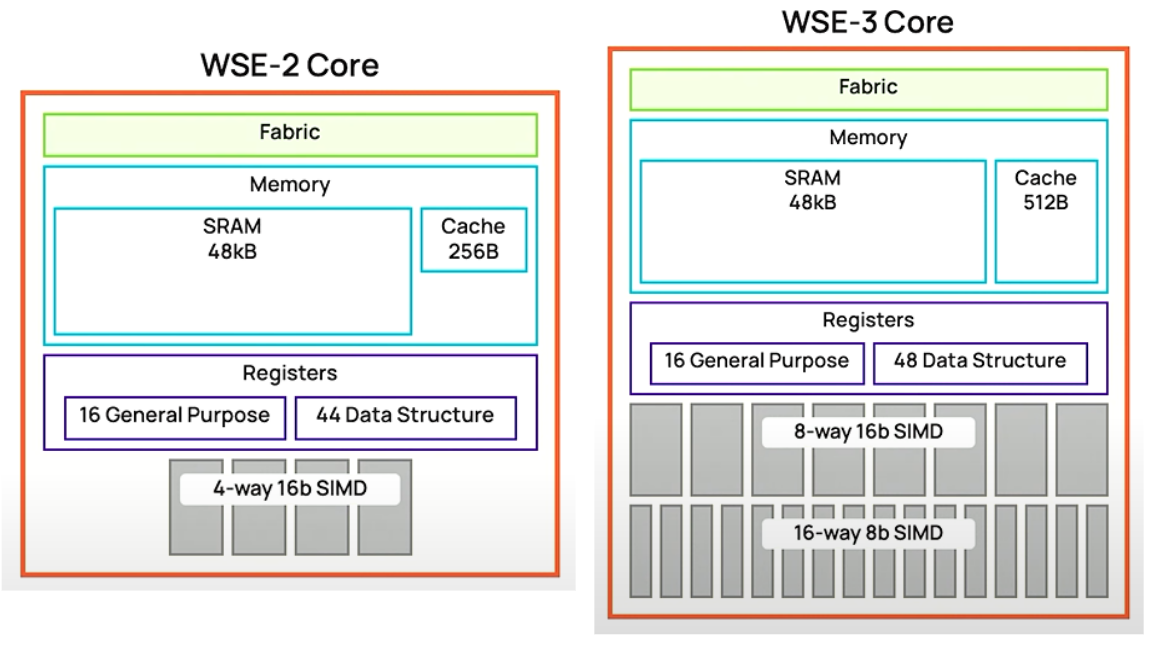
WSE-3は、84 die から構成されます。900000コアなので、1 Die では 10.7K cores になります。CS-2の時は、1 Die 10.1K cores ですね。

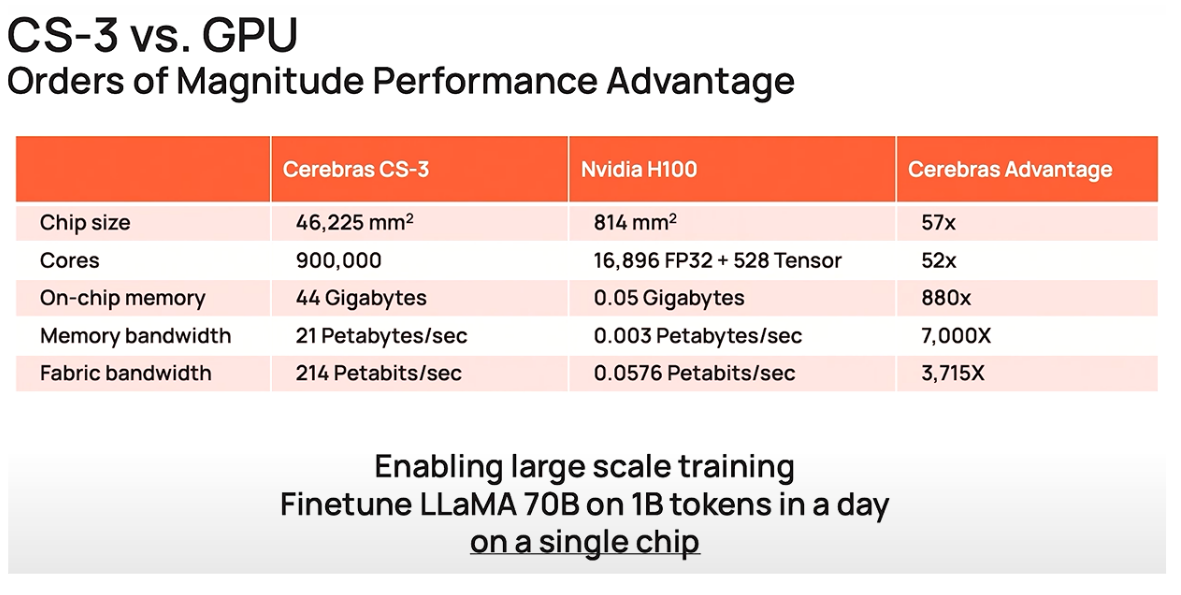
比較の対象はやっぱりH100です。
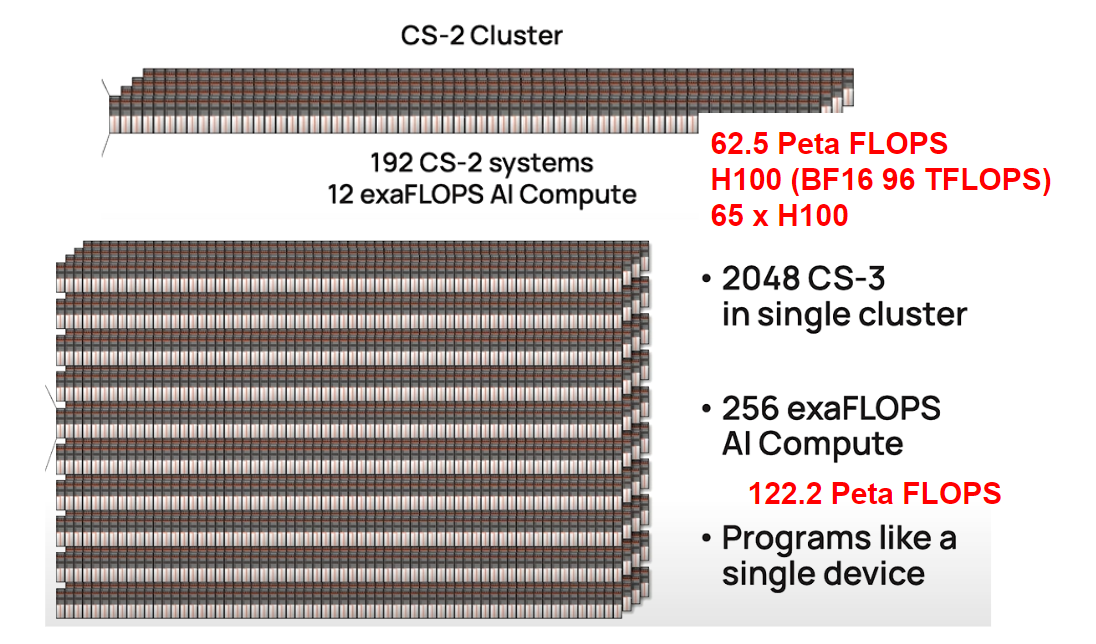
CS-3 Cluster
Cluster の CS-2 から CS-3 になると大きくなります。下図は、2枚のスライドのCS-2 ClusterとCS-3 Clusterを並べています。128台から2048台です。16倍です。 性能は、12 exa FLOPS から 256 exa FLOPS で 21.3 倍です。これは、CS-2 と CS-3 のコア内の SIMD の性能が2倍になったが性能はスケールしていませんね。
下図の Link Speed が CS-2 の 100Gb/s から CS-3 での 400Gb/s, 800Gb/s にアップグレードされるようです。
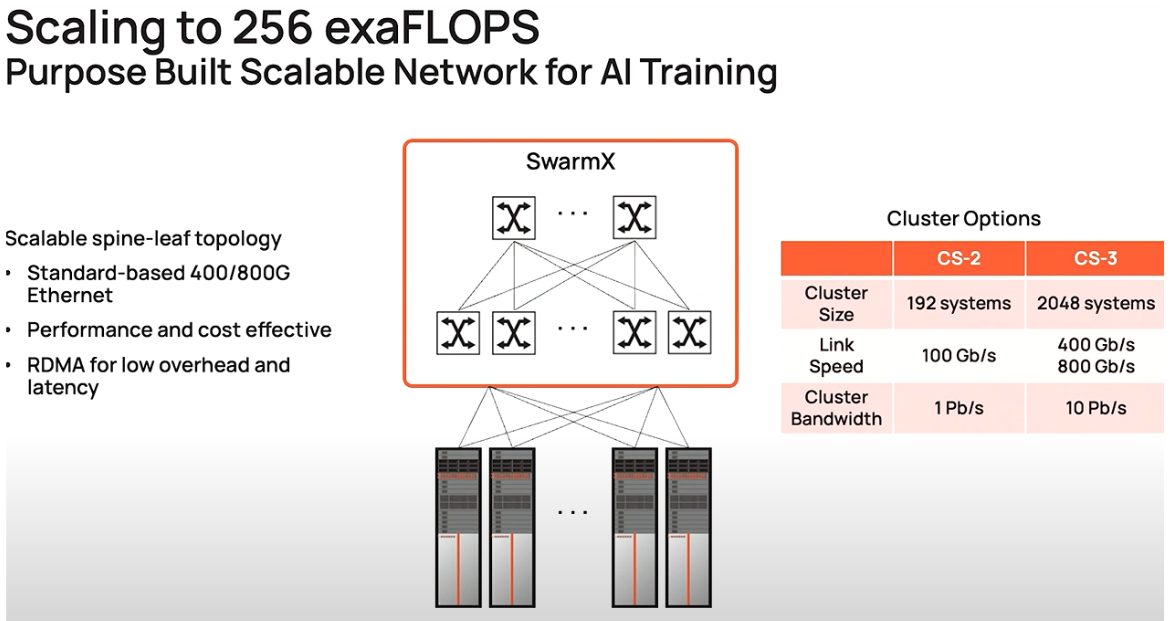
Ethernet の件
Ethernetを 100Gbps を 400Gbps に上げる件は、下記のブログの後半で書いています。
今まで、WSEの両端をFPGAにしていて、そのFPGAの100GbpsのEthenetを使っていた。それを ASIC を開発して、400Gb/s, 800Gb/s にするのと。
おわりに
上記の Ethernet の ASIC の件、SwamXは400Gbps, 800Gbps にするのは市販のEthernet Card、例えば、NVIDIA ConnextX-7 や ConnextX-8 を使えばいいけど、ASIC に 800Gps は結構辛そうな気がします。