はじめに
TURINGがAMD(Xilinx)の巨大なFPGA評価ボードを購入しましたね。ということを4月3日に書きました。
今回は、その巨大なFPGA評価ボードの準備として、Kria KV260 を使ったという 下記のTuring の Tech Blog について記録に残します。
FPGAによるLLM推論 : Swan
FPGAに実装したのは、llama2.c を参考に、Transformerとその本質的な演算だけをFPGA用に実装した swan のようです。
この github を見て、気が付いたのが、これです。

どこかで見たことがある。。。
そう、クレイジーピエロ san です。
これ以上は、突っ込まないことにします。
ソースコードの中身を覗いてみる
Host側のtesor_fpga.cpp のMatmulFPGA関数の下記の部分です。
q.enqueueMigrateMemObjects({buffer_a, buffer_b}, 0);
kernel_matmul.setArg(3, kDim);
kernel_matmul.setArg(4, kDim);
q.enqueueTask(kernel_matmul);
q.enqueueMigrateMemObjects({buffer_result}, CL_MIGRATE_MEM_OBJECT_HOST);
q.finish();
うーん、Task なんですね。。。
CPUやGPUのOpenCLだと、Taskじゃないんですよね。FPGAだと、Taskなんです。。。
巨大なFPGAへの実装
Kria KV260 => Versal VP1802 になると、各Kernelはシーケンシャルに実行するのではなく、パイプラインで実行することになります。
となると、カーネル間のデータの受け渡しは、DRAM経由ではなく、PIPEという特別な方法(FPGAだけで使える)で実装しないと性能でないと思うんですよね。
でも、Google君に聞いたら、昔はサポートしていたけど、今はサポートしていないんですよね。
どうするのかな?
kernel_matmul.cpp を眺めてみたら、計算の部分とデータ移動の部分がちゃんと分離されて書かれていますね。これなら、DRAM経由でなく、カーネル間を直結にすることもできそうですね。
extern "C" {
void kernel_matmul(float* i_vec, float* i_mat, float* o_vec, int vec_size,
int col_size) {
#pragma HLS INTERFACE m_axi port = i_vec bundle = gmem0
#pragma HLS INTERFACE m_axi port = i_mat bundle = gmem1
#pragma HLS INTERFACE m_axi port = o_vec bundle = gmem0
static hls::stream<float> vec_stream("vec_stream");
static hls::stream<float> mat_stream("mat_stream");
static hls::stream<float> out_stream("out_stream");
#pragma HLS dataflow
load_vec(i_vec, vec_stream, vec_size);
load_mat(i_mat, mat_stream, vec_size, col_size);
compute_matmul(vec_stream, mat_stream, out_stream, vec_size, col_size);
store_result(o_vec, out_stream, col_size);
}
}
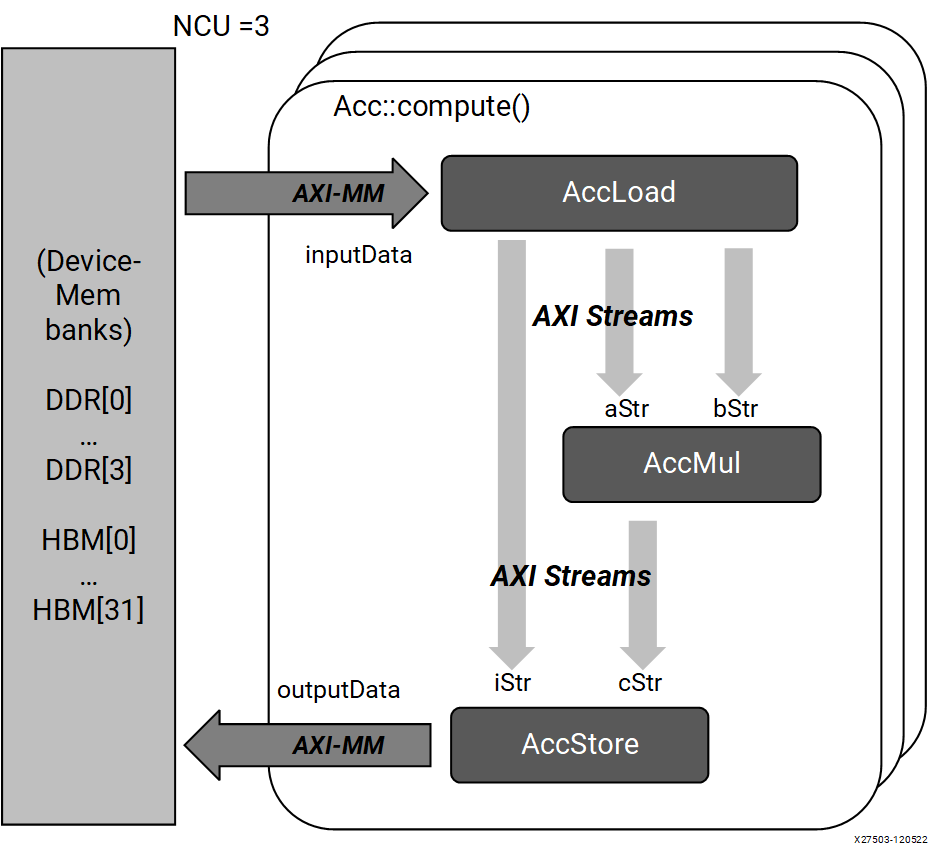
Vitisのマニュアルのシングルパス同期のパイプラインな感じになると思います。下図は説明のために引用しています。
おわりに
巨大なFPGAへの実装は、そのFPGAに依存するコードがたくさん入ります。 そこから、どう、ASICに持っていくところが色々と面倒なんですが、そこんところを是非、聞いてみたいです。
あたしは過去、何度かFPGA PROTOTYPINGを行いました。FPGAで機能検証後、ASICへの実装します。 この場合は、FPGAに特化した記述は極力避けるか、FPGA用のコードを別途用意します。 今回のケースとの大きな違いはFPGAに実装した後に、ASICに移行するのではなく、ASIC用のコードをRTL Simulationで検証後、FPGAへ持っていきます。
そこんところも聞いてみたいです。
ご連絡をお待ちしております。