@Vengineerの戯言 : Twitter
SystemVerilogの世界へようこそ、すべては、SystemC v0.9公開から始まった
突然、Graphcore から MK2 GC200 および IPU-Machie M2000 発表があった。
何故?このタイミングだったかの?
6/25の
INTERNATIONAL WORKSHOP ON MACHINE LEARNING HARDWARE (IWMLH), CO-LOCATED WITH ISC2020
で講演したばかりなのに。
新しいチップが MK2 GC200 になったので、今までの IPU は、MK1に rename された。
MK1は16nmで、MK2は7nm。内部プロセッサ数はそれほど変わらないが、SRAMが300MBから3倍の900MBに。ほとんど、SRAMを増やしただけっぽく感じちゃう。
たぶん、対象にしているアプリケーションでは、SRAM足りなくなったんでしょうね。
一応、Streaming Memoryという機能を使って、内部SRAMが足りなくなった時にホストのメモリに一時対比する機能はあるようですが、退避していると時間がかかり性能劣化が激しいんでしょうね。
IPUのページもMK1からMK2に変わっています。
また、1Uサーバーの IPU-Machine M2000 も同時にアナウンスされた。リリース時期はQ4.2020なので、あと3か月先。予約も開始すると。
で、この IPU-Machine M2000 のお値段が、32450ドルと、かなりお安い(かな?)
どのぐらいお安いかというと、IPU-Machine M2000 * 8 と NVIDIA DGX A100 を比較したスライド(下図は、The Nextplatform のTHE ELEGANCE (AND LIMITATIONS) OF PRECISELY ENGINEERED ACCELERATORSにあるものをURL組み込みで取り込んでいます)をみると、
FP32 compute の性能比で、12倍
AI compute の性能比で、3倍 (これって、BF16のことでしょうかね)
AI Memory の容量比で、10倍 (これってメモリ帯域、A100はHBM2、MK2はSRAM)
お値段は、+60000ドル。

MK1のPCIe Cardを8枚入れたDELLサーバーがDGX A100が出る前、ざっくり140KドルだったのをDGX A100発表後、100Kドル弱に値下げして対応しましたが、ここで一気にコスパ競争に持ち込みましたね。
DGX A100は既にクラウドベンダーに導入し始めて、どんな感じかが分かりそうですが、MK2とIPU-Machine M2000 はまだ半年ぐらいはかかりそうですね。あ、そういえば、クラウドサービスもやっていた気がするが、MK2も使えるのでしょうかね。
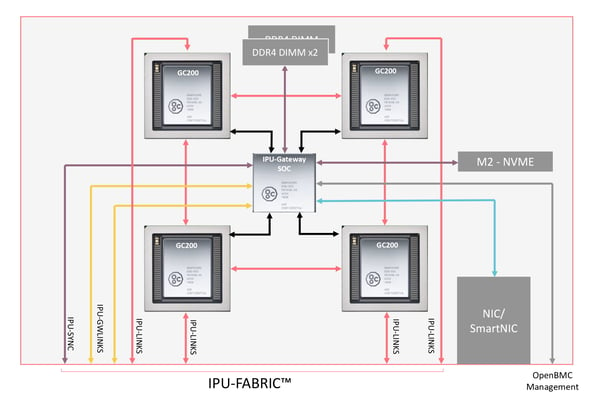
お値段もインパクトを与えましたが、IPU-Machine M2000の中には、IPU-Gateway SoCなるものが入ってます。
下図は、最初に紹介したブログにあるものをURL組み込みで取り込んでいますが、この図によると、そのSoCには、DDR4x2 + DDR4 の3枚のメモリが接続しているっぽいんですよね。そして、4個のMK2と接続、その他に、M2 (SSD)、NIC/SmartNICもあります。
図の下の方に書いてある IPU-FABRIC というものは、
- 各MK2からの IPU-LINKS
- SoCからの IPU-GWLINKS
- SoCからの IPU-SYNC
なる信号をまとめたもののようで、2.8Tbps の転送レートがあると、GB/s ではなく、Tbps というのは何か理由があるのでしょうか?
MK2のIPU-LINKSの転送レートは、10 x IPU-LINKS = 320GB/s とありますので、1 x IPU-LINKS は、32GB/s * 8 = 256Gbps ですね。
M2000内のチップ間は、2個に接続しています。この部分の接続は、左右には3個の IPU-LINS と繋がっていて、上下のチップとは2個のIPU-LINKSと繋がっていると思います。
下図は、ブログの「3D Ring Topology」を説明しているビデオからの引用です。
左右のチップとの接続は3組のIPU-LINKS(8x2x3)になっています。ということで上下のチップとは、各1組(8x2) になるんだと思います。

ちなみに、DELLサーバーの時もPCIe Card間の接続は、下図(このブログからのURL組み込みです)のようになっています。

したがって、IPU-LINKS は8組になり、IPU-FABRIC の 2.8Tbps の内、2.048Tbps が IPU-LINKS が占めているのだと思います。残りの 752Gbps が 2本の IPU-GWLINKS と IPU-SYNC になるんだと思います。
では、この IPU-GWLINKS と IPU-SYNC とは、どんなものか?
それは、明日のブログに書きますね。