はじめに
Graphcoreは、Cloudサービスを提供しています。基本的には、16個のチップを搭載した IPU-POD16 と 64個のチップを搭載した IPU-POD64 によるものです。
IPU-POD128/IPU-256POD
今回は、IPU-POD64を2個接続した IPU-POD128 と 4個接続した IPU-POD256 をアナウンスしました。
性能
RESNET50 v1.5のTensorFlow Traiingに対しては、
- IPU-POD16 : 29,565 images/sec
- IPU-POD64 : 102,320 images/sec (87% up)
- IPU-POD128 : 186,553 images/sec (91% up)
- IPU-POD256 : 355,021 images/sec (95% up)
BERT-LARGE Ph1 (SL128) TensorFlow
- IPU-POD16 : 3,665 seq/sec
- IPU-POD64 : 12,908 seq/sec (88% up)
- IPU-POD128 : 25,097 seq/sec (97% up)
IPU-POD256 のデータはありませんね。
RESNET50 v1.5 よりもBERT-LARGEの方がスケールしていますね。
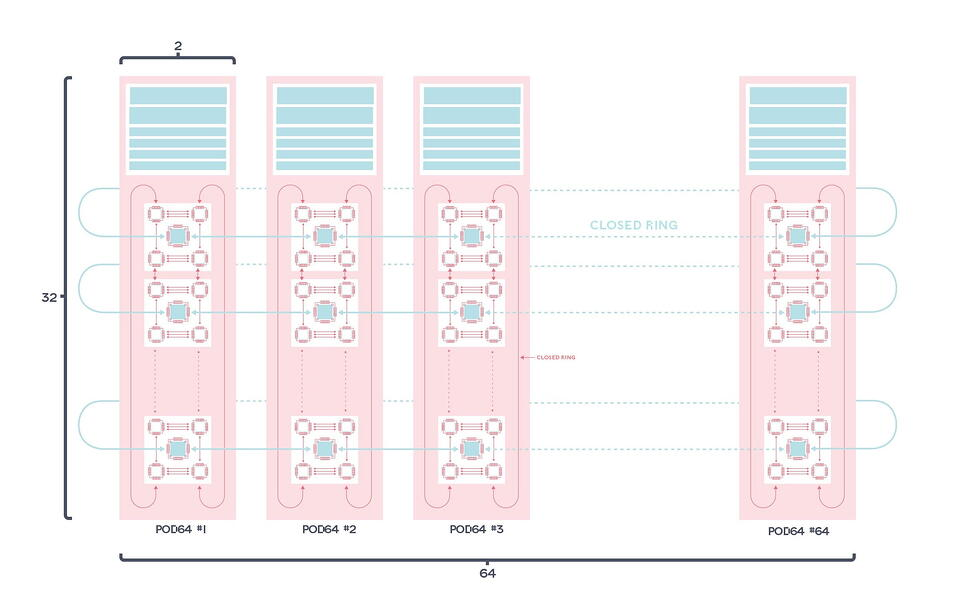
どのように、IPU-POD間を接続しているのか?
下図を説明のために引用します。IPU-POD64間の接続は、IPU-M2000内のIPU-Gatewayから出ている GW-Links (100Gb)にて両サイドのIPU-POD64内の同じ位置のM2000と接続しています。
最大64のIPU-POD64と接続できるようです。
おわりに
Graphcoreは現在、TSMC 3nm (ここでは、MK3と呼ぶことにします)での実装をしているようです。
TSMC 16nm の MK1 => TSMC 7nm の MK2 では、基本的には内部SRAMを増やした(300MB => 900MB) に増やしたためです。内部SRAMで足りなくなると、IPU-Gatewayに接続しているDDR4メモリにアクセスすることになります。MK2からIPU-Gatewayとの間は、PCIe Gen4 x8 相当(MK2はPCIe Gen4 x16であるが、IPU-Gateway側がPCIe Gen3 x16であるため、結果的に PCIe Gen4 x8になっている)で接続しています。
Graphcoreでは内部SRAMが多いので、IPU-GatewayのDDR4へのアクセスレイテンシーは隠蔽できると言っているが、MK3 ではどうなるのでしょうか? もしこの部分がボトルネックになっているのなら、MK3のPCIe GenX を変えるのではなく、IPU-Gateway の方を変える必要があるんじゃないのかな?と思っています。
候補としては、Ampere ComputingのAltraなんかいいと思います。PCIe Gen4 x16 が8個付いています。ただし、100GbEが無いので外部にチップを付ける必要はありますね。