はじめに
Google TPU v5e の続き
この後、調べたりして分かったこと
お値段は、v2 よりお安い
Cloud TPU pricing によると、v5e は v2 よりお安いです。つまり、一番お安いです。

NVIDIA DGX Pod の対抗?
v5e は、256 chips ですね。NVIDIA DGX Pod の対抗品って感じですかね。DGX Pod も 256 chipです。何故なら、NVLink が 256 個まで接続できる。
v5e は、v4i の後継
256 chip までに制限すること(もっと接続できるでしょうが、システムとしては大きくしていないだけ?)で、ある程度のモデルの推論・学習用なんでしょうね。
v4i は 1 Board (4 chips) だったので、大きなモデルは v4 を使うことになっていたんでしょうね。
LLM の本命は、学習ではなく、推論
ディープラーニングがブームになってから、ずーと学習が話題になっていますが、実際に利用する時は推論ですよね。推論では、スマホで使えないとね。
LLMも現在は色々なモデルを作って、公開するという競争になっていますが、実際に使うのはやっぱり推論ですよね。
モデルをビジネスに利用して、
- 売上を上げる
- コストを下げる
ことで、
- 利益を増やす
ことができないと意味無いですよね。。。
とは言え、今は投資ということになっていますが、最終的にはその投資を回収し、投資以上に利益を出し、利回りとして、それなりにならないと。。。
v4 と v5e の比較
上記のブログに Google TPU v5e の Pod の写真が載っていました。下記のようなものです。説明のために引用します。

1台のホストに、2枚のTPU v5e Board が接続しているのが分かりますね。
そして、このブログの最初のところに、
Google Cloud’s AI-optimized infrastructure makes it possible for businesses to train, fine-tune, and run inference on state-of-the-art AI models faster, at greater scale, and at lower cost. We are excited to announce the preview of inference on Cloud TPUs. The new Cloud TPU v5e enables high-performance and cost-effective inference for a broad range AI workloads, including the latest state-of-the-art large language models (LLMs) and generative AI models.
とあります。
We are excited to announce the preview of inference on Cloud TPUs
v5e は、v4i の後継 ということなんですね。
上記のブログでの、v4 と v5e の比較。 Llama 2 7B / Llama 2 13B / Llama 2 70B / GPT-J 6B / GPT-3 175B / Stable Diffusion 2.1 でのコスパ。
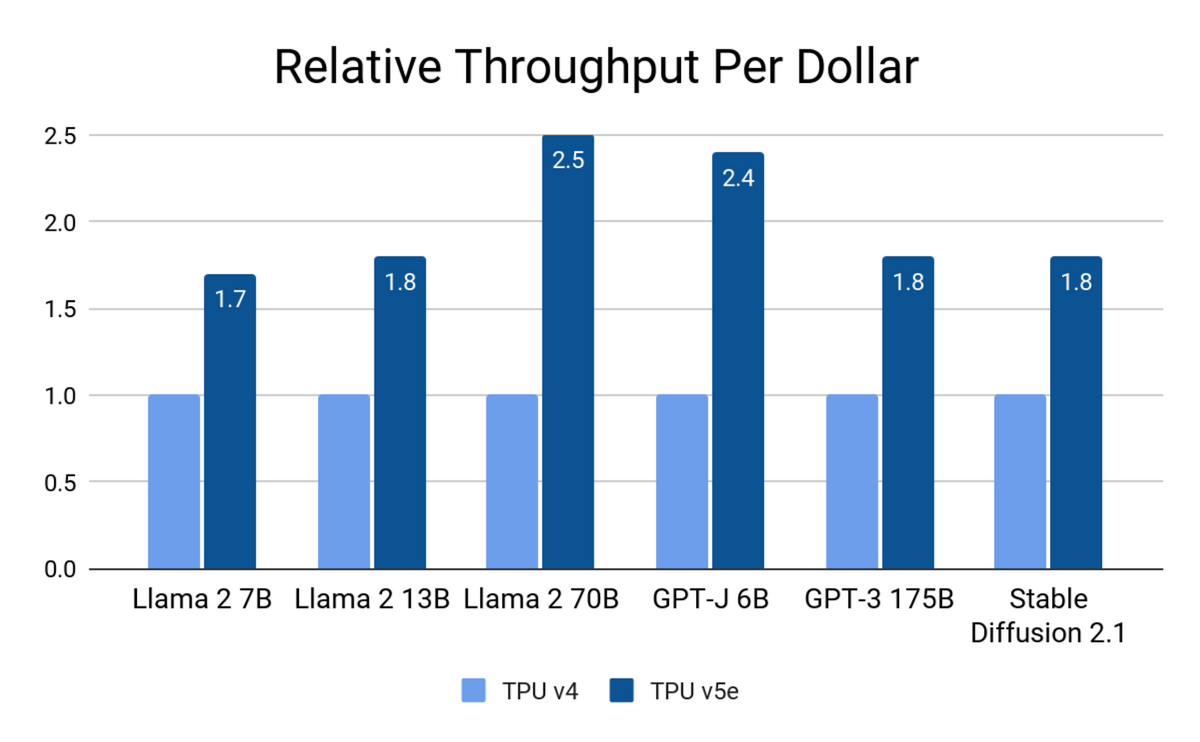
1.7 - 2.5 倍、v5e の方が v4 よりお安いです。
Latency も v5e の方が v4 よりいいです。1.6 - 1.7 倍。推論は、Latency がいい方がいいですよね。

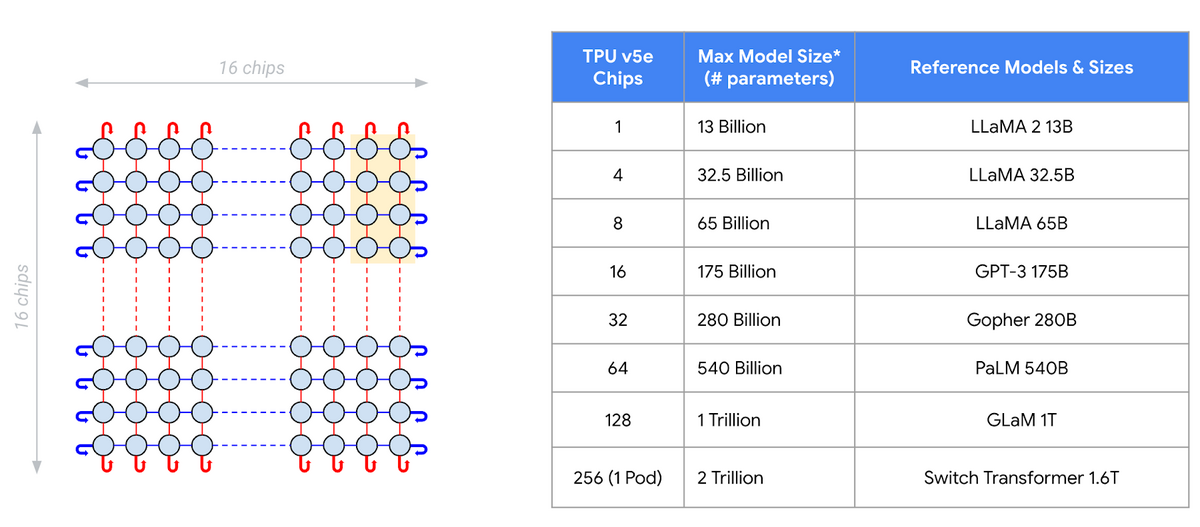
LLaMA 2 13B が1個の v5eで、GPT-3 175B が 16個の v5e、PaLM 540B が 64個の v5e で出来るようです。
int8でパラメータを表現しているようですね。bf16 だと197 TFLOPS で、int8 だと 393 TFLOPS ということです。v4 は bf16/int8 ともに 275 TFLOPS なので 推論(int8)に関しては v5e の方が性能がいいということになりますね。393/275 = 1.429 倍。Latency は 1.6 - 1.7 なので処理性能の他に何かが効いていますね。int8 にしたことで何かあるんでしょうかね。
- LLaMA 2 13B : $1.20 x 1 = $1.20
- LLaMA 65B : $1.20 x 8 = $9.6
- GPT-3 175B : $1.20 x 16 = $19.2
- PaLM 540B : $1.20 x 64 = $76.8
になります。
LLaMA 2 13B に対して、PaLM 540B は、64倍のコストがかかるんですが、64倍いいものになっているのでしょうかね。。。。
おわりに
Google Cloud の GPU のお値段を見てみました
Google TPU v5e / 16GB HBM2e は、$1.20 なので、P100 の $1.46 よりお安いです。
つまり、Google Cloud でそれなりの推論・学習をするときに一番、コスパがいいのが、v5e ということになったわけですね。。。
関連記事