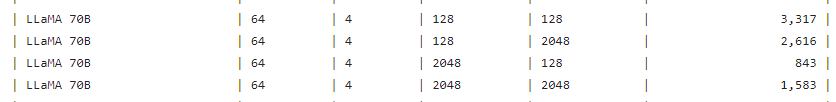はじめに
NVIDIA A100 vs H100/H200 の比較って、下記のNVIDIAのブログにて、どうなっているのかを振り返りしてみた。
- NVIDIA Hopper アーキテクチャの徹底解説
- NVIDIA TensorRT-LLM が NVIDIA H100 GPU 上で大規模言語モデル推論をさらに強化
- New NVIDIA NeMo Framework Features and NVIDIA H200 Supercharge LLM Training Performance and Versatility
A100 と H100 の演算性能比較
下図は、A100に対して、H100での演算性能向上をどのようにしているかを示しています。
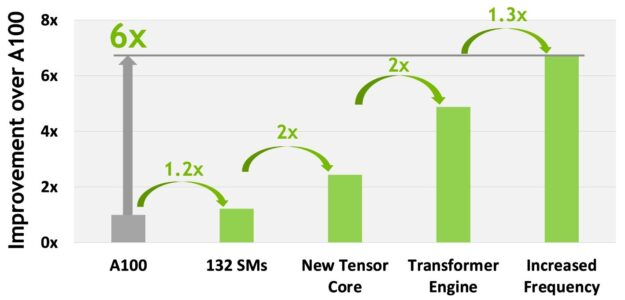
- SMs : 1.2x
- New Tensor Core : 2.0x
- Transformer Engine : 2.0x
- Increased Frequency : 1.3x
同じプログラムであれば、
- SMs (1.2x) x New Tensor Core (2.0x) x Increased Frequency (1.3x) = 3.12x
になりますね。
Transformer Engine を使うと、追加で、2.0x になる感じです。
FP16/BF16 Tensor Core の性能は、
- A100 : 312 TFLOPS
- H100 : 1000 TFLOPS
H100 は、FP8 Tensor Core の演算性能は、2000 TFLOPS です。
FP16/BF16 は、3.2x です。
A100 vs H100 の推論性能比較
NVIDIA は、Meta、AnyScale、Cohere、Deci、Grammarly、Mistral AI、MosaicML (現在は Databricks の一部)、OctoML、ServiceNow、Tabnine、Together AI、Uber などの主要な企業と緊密に協力し、LLM の推論の高速化と最適化に取り組んできました。
とあります。
これだけ多くのカスタマーがLLMの推論の高速化と最適化をやっているんですからね。。。。
これらのイノベーションは、オープンソースの NVIDIA TensorRT-LLM ソフトウェアに統合され、Ampere、Lovelace、Hopper GPU に対応し、数週間以内にリリースされる予定です。
その成果は、既に公開されている TensorRT-LLM に統合されているようです。Ampereでも使えると。
が入っているですね。
下図は、Llama 2 70B の A100 と H100 のTensorRT-LLM の有無による比較です。

- A100 => H100 Auguest : 2.6X
- A100 => H100 TensorRT-LLM : 4.6X
演算性能比較としては、
- 3.12 x
- Transformer Engine を追加 : 3.12 x 2.0 x
に対して、
- H100 Auguest : 2.6 x <= 3.12 x
- H100 TensorRT-LLM : 4.6 x <= 6.24 x
な感じですかね。。。
- H100 Auguest の 2.6x は、3.12x に対して、83.3%
- H100 TensorRT-LLM の 4.6x は、6.24 x に対して、73.7%
2.6x => 4.6x は、1.769倍
A100 vs H200 の学習性能比較
H200 は、演算性能は H100 と同じですが、メモリが 141 GB (H100は80GB) になっています。
下記の図は、
- Llama 2 7B : A100 (211 TFLOPS) => H200 (779 TFLOPS)
- Llama 2 13B : A100 (206 TFLOPS) => H200 (822 TFLOPS)
- Llama 2 70B : A100 (201 TFLOPS) => H200 (836 TFLOPS)
ただし、A100のNeMoは 23.08、H200のNeMoは、24.01-alpha で NeMo のバージョンが違うのがかなり気になります。
A100ではモデルサイズが大きくなると、 TFLOPS は下がっていますが、H200ではモデルサイズが大きくなると、TFLOPSが上がっています。 何故でしょうか?
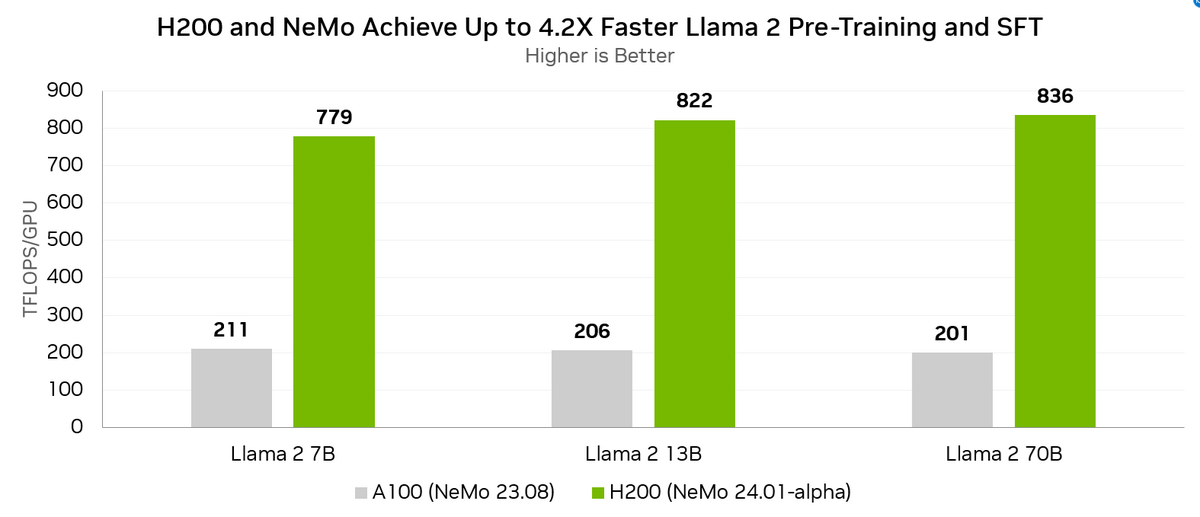
- Llama 2 7B : 211 => 779 だと、211/312 (0.676)、779/1000 (0.779)、779/211 (3.69)
- Llama 2 13B : 206 => 822 だと、206/312 (0.660)、822/10000 (0.822)、822/206 (3.99)
- Llama 2 70B : 201 => 836 だと、201/312 (0.644)、836/1000 (0.836)、836/201 (4.15)
A100では演算性能の60%台、H200では演算性能の70-80%台を出しています。これは、メモリが80GB => 141GBに増えたからでしょうか?
A100とH100の演算性能比較では、Transformer Engineを除くと、3.12倍なので、それよりも高いです。
おわりに
は、Englishと日本語
は、Engilishと中文
なんか、気持ちが分かります。。。
追記)、2024.03.13
NVIDIAのTensorRT-LLMでの
— Vengineer@ (@Vengineer) 2024年3月13日
- A100 vs H100
- A100 vs H200
はしているんだけど、H100とH200の比較していないのどうしてと思ったのが、このブログを書いた時。https://t.co/5SuiKukN8w
そして、今、H100とH200のそれぞれの値を見つけた。
LIama 70B-128/128
H200 FP8 : 3,844
H100 FP8 : 3,269
あれ2割
一つ前のデータ(2024.3月)では、パラメータが違う
A100 FP16 : LIama2 70B

H100 FP8 : LIama2 70B
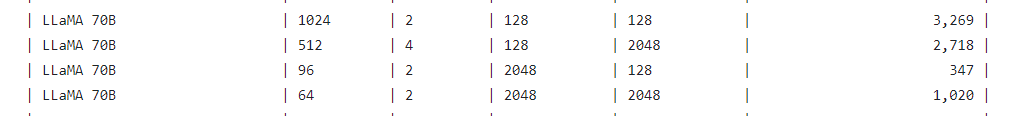
H200 FP8 : LIama2 70B (New)

そして、一つ前のデータ(2023.12.4)だと、パラメータが全く同じで、2-3倍ぐらい。ブログの値と違う。。。
A100 FP16 : LIama2 70B
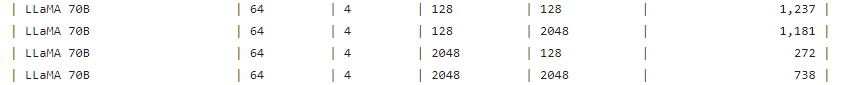
H100 FP8 : LIama2 70B