はじめに
AMDがMI300A/MI300Xの詳細を公開しました。
MI300A
- 6 x XCD (38 CUs)
- 3 x CCD (8 Zen4)
- 4 x IOD
- 8 x HBM3 (128GB/8H)
- 256MB Infinity Cache
- 3.5D packaging
GPU die に関して
- GPU Architecture : CDNA3
- Lithography : TSMC 5nm | 6nm FinFET
- Stream Processors : 14,592
- Compute Units : 228
- Peak Engine Clock : 2100 MHz
- Peak Half Precision (FP16) : 980.6 TFLOPs
- Peak Single Precision Matrix (FP32) : 122.6 TFLOPs
- Peak Double Precision Matrix (FP64) : 122.6 TFLOPs
- Peak Single Precision (FP32) : 122.6 TFLOPs
- Peak Double Precision (FP64) : 61.3 TFLOPs
- Peak INT8 : 1.96 POPs
- Peak bfloat16 : 980.6 TFLOPs
MI300X
- 8 x XCD (38 CUs)
- 4 x IOD
- 8 x HBM3 (192GB/12H)
- 256MB Infinity Cache
- 3.5D packaging
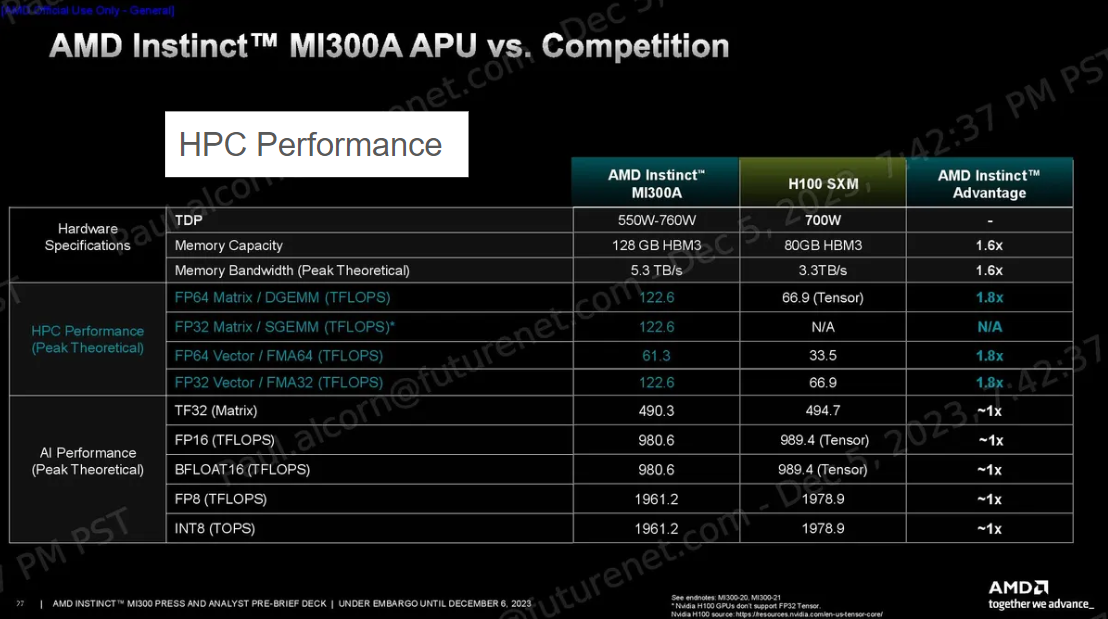
性能比較
NVIDIA H100とMI300Aの比較です。MI300Xではありません。AI性能だけでなく、HPC性能がすごいよというのがAMDの主張ですね。
ノード構成
下記は、AMD MI300AのData sheetからの引用です。MI300A x 4 が node 単位です。
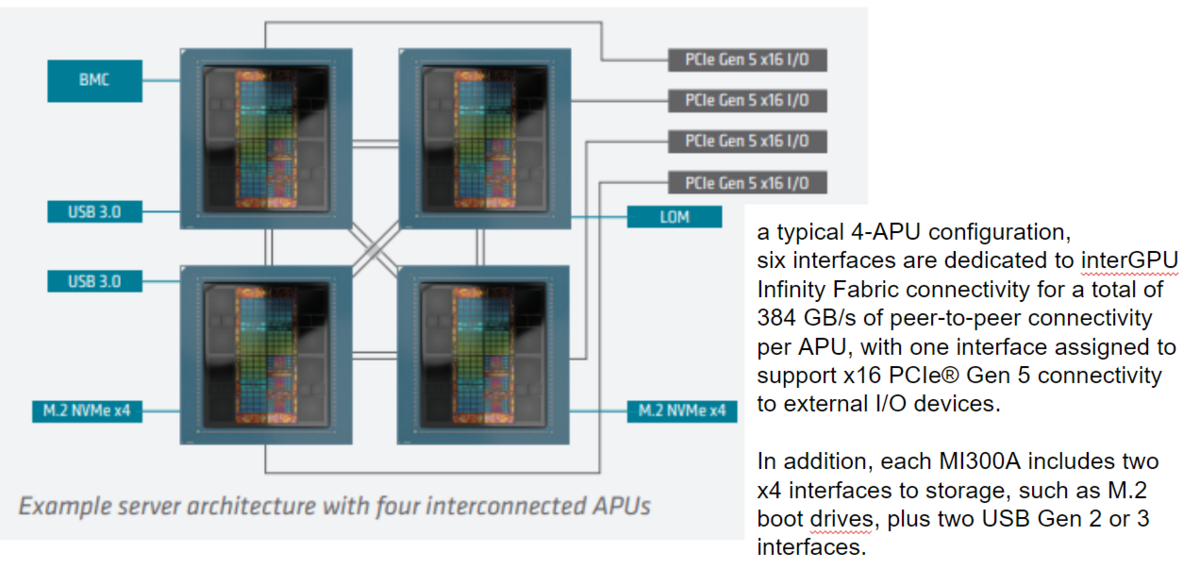
HPE Cray の Blade になると、PCIe Gen5 のところに、Slingshot が付く感じですかね。
下記は、GIGABYTEのサーバー機の写真です。ここから説明のために引用します。

こちらの写真では、サーバー全体が映っています。ここから説明のために引用します。

MI300X では、下記のように NVIDIA HGX H100 のような感じですね。ここから説明のために引用します。

おわりに
AMDI MI300A/MI300X の情報を集めてみると、
の silicon die と非常に似ているような気がしました。
参考のために、
関連記事