はじめに
AWS が Graviton 4 / Trainium2 を発表しました。

左 : Graviton4、右 : Trainium2
Trainium2 の HBMが左側に付いているので、Trainiumとは違います (Trainium は右側に2個付いています)
Graviton4
AWS Announces 4th Generation Graviton General Purpose Compute SoC: Scale-up Apps, Dual-Socket-Capable, Supporting SAP HANA
— Patrick Moorhead (@PatrickMoorhead) 2023年11月28日
Today, AWS announced its fourth-generation general purpose datacenter SoC,
which gives the company an even better ability to address scale-up applications… pic.twitter.com/y4cJfofyTz
上記のXの投稿によると、Graviton3 に対して、
· 30% better compute performance and 50% more cores (96 Arm Neoverse V2 cores for single socket, 2M L2 cache per core) · 75% more memory bandwidth with 12 DDR5-5600 channels · 96 lanes PCIe G5 · 7 chiplet SoC design · Encrypted DRAM, Nitro, Coherent links · Multi-socket (really) supporting 192 cores and 3X DRAM of Graviton3
です。
CPU に関しては、下記のようになっています。
- Graviton : Cortex A72 x 16
- Graviton2 : Neoerse N1 x 64
- Graviton3/3E : Neoverse V1 x 64
- Graviton4 : Neoverse V2 x 96
Ampere Computingの Altra Max (128コア)やAmpereOne(192コア)に比べるとコア数は少ないです。
DRAM I/F は、
- Graviton3/3E : DDR5 x 8 CH
- Graviton4 : DDR5 x 12 CH
コア数が 64コア => 96コア で、1.5倍なので、DRAM I/F の CH数も 1.5倍ですね。
Graviton4 での最大なる特徴は、Coherent links です。Graviton3/3E までは 1 socket でしたが、Graviton4 は 2 socket になったわけです。
Trainium2
1つの Package の中に、2 die (1 die には、HBMが2つ) になっています。初代の Trainium の学習では4倍の性能のようです。
1つの Package の中に、2 die なので、これで2倍。となると、1 die で2倍。。。
下記はTrainium のブロック図ですが、
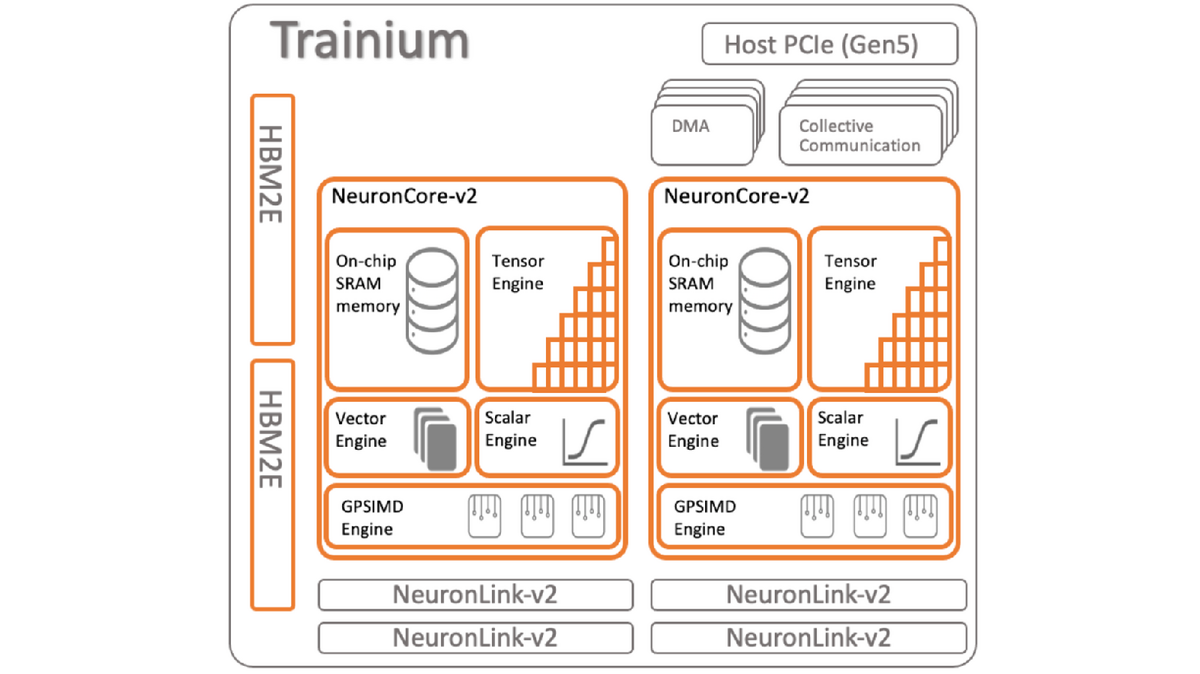
1 die に2個の NeuronCore-v2 が載っています。2個の HBM2E が載っています。HBM2E から HBM3 になれば転送レートが倍になるので、NeuronCore-v2を2倍の4個でもOKのようです。
HBMの容量は、3倍です。1 die で 1.5倍ということは、16GB x 2 => 24GB x 2 で、2 die なので96GBとなる模様。
16個の Trainium2 チップが載ったものが EC2 Trn2インスタンスになるということだと、上記の Trainium2 の Package が 8個で、チップは16個。
EC2 Trnインスタンスに対して、EC2 Trn2インスタンスは4倍の性能ですね。
おわり
夏のGoogleのTPU v5eの発表、先日のMicrosoftのCobalt 100/Maia 100の発表に続き、AWSのGraviton4/Trainium2の発表。。
3大 Cloud Service会社が自社でCPUとAIアクセラレータの開発を進めています。今後も継続して開発していくと思います。
関連ブログ
関連記事
追記)、2023.12.01
Several years ago, when we started pursuing building our own chips, a lot of folks thought this was nuts. We heard a lot of the same refrains you often hear—why make this investment, why invest in a team and all the other fixed costs to develop your own chip when you can buy from… pic.twitter.com/UH2PU1z9si
— Andy Jassy (@ajassy) 2023年11月30日
追記)、2023.12.05
追記)、2023.12.10