はじめに
ARM が Neoverse V3/N3/E3/CMN-S3を発表しました。
今回は、The Nextplatform の下記の記事をみてみます。
以下の図は、上記の記事から説明のために引用します。
Neoverse V3 / N3
64コアのNeoverse V3 と 32コアのNeoverse N3です。

- I/O
- DDR5
- Die to Die
があります。
- Socket で 128コアまでサポート
- メモリは、DDR5/LPDDR5だけでなく、HBM3もサポート
- I/O は、PCIe Gen5 だけでなく、CXL 3.0 も

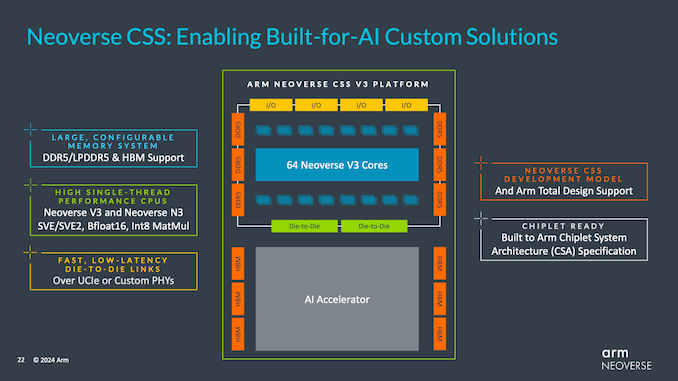
Compute Subsystems (CSS)
Neoverse N2 の時に、Compute Subsystems (CSS) がありましたが、Neoverse V3/N3 でも CCS があります。

AI Accelerator も繋げられる
Die to Die で、AI Accelelator を接続するというもの。AL Accelerator 側には HBM3 が6個。お、これって、CoWos-4 前提?
下図は、「10年で5世代の進化を遂げた高性能パッケージング技術「CoWoS」(後編)」から説明のために引用します。2023年目標ですが、どうなんでしょうか?

その次もある
ちゃんと、次もオープンにしています。Arm san はロードマップはちゃんと公開するし、ちゃんとリリースします。

おわりに
ARM 再上場時は、それほど株価があがりませんでしたが、先日爆上げして、2倍になりましたね。。。なんでだろうか?
関連、Xの投稿
ARM Neoverse V3 (64コア x 2die = 128コア)+ CMN-S3に対して、
— Vengineer@ (@Vengineer) 2024年2月26日
- Ventana Veyron V1 : 16コアなchiplet
- Tenstorrent : 8コア x 16 = 128コア
また、
- Ampere Computing : AmpereOne Max 192コア
- NVIDIA Grace : Neoverse V2 x 72コアhttps://t.co/PGTcTINFoF
この中で、Ventana Veyronって、CPUのみの chiplet ですが、I/O Die が無いと何もできない気がします。その I/O Die って、誰が作るのでしょうか?
AMD EPYC Rome の IO Die shot ですが、ここから説明のために画像を引用します。
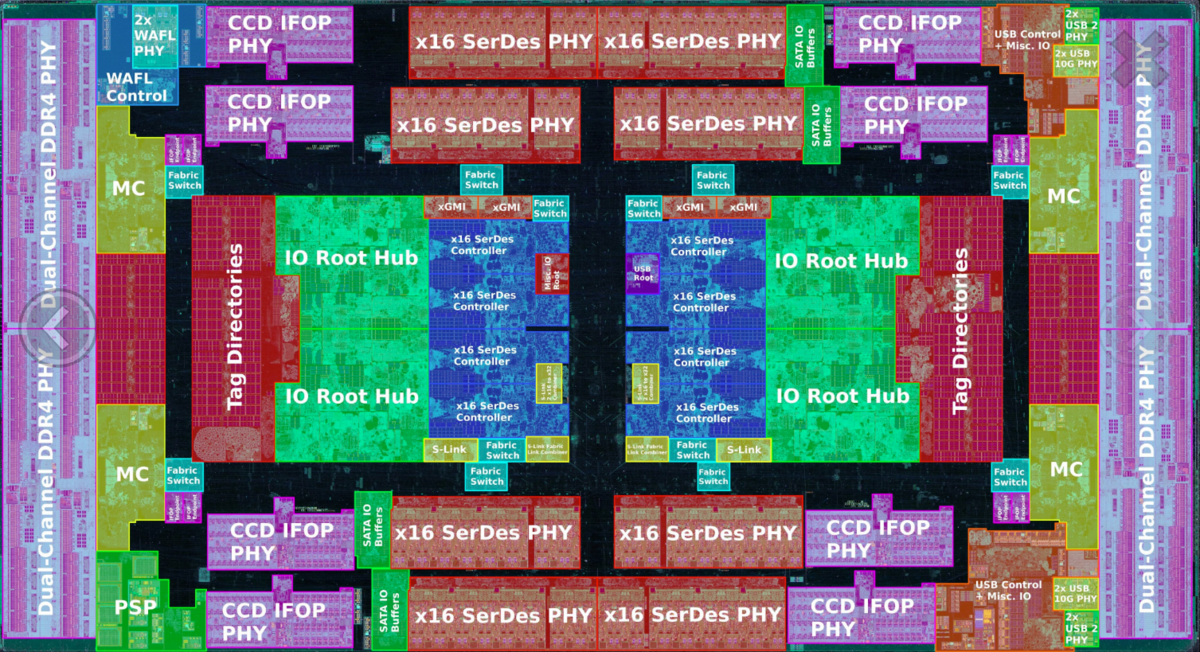
この中の
- Tag Directories
- IO Root Hub
とか、全体の性能に大きな影響を与えるのですが、ARM AMBA CHI で繋げるだけで出来るものでしょうか?また、16コアに対して、1ポートで性能大丈夫なんでしょうか?