はじめに
下記のWhite Paperで、MI300X (CDNA3) と MI250X (CDNA2) を比べてみた
MI250X

MI250X は、MI200 die を対向で接続したもの。MI200 die には、7つの Infinity Fabric と Infinity Fabric/PCIe Gen4 x16 が1つあります。対抗で接続するのは、Infinity Fabric が 4 つになっている面です。
HPC構成では、MI250Xが4基です。
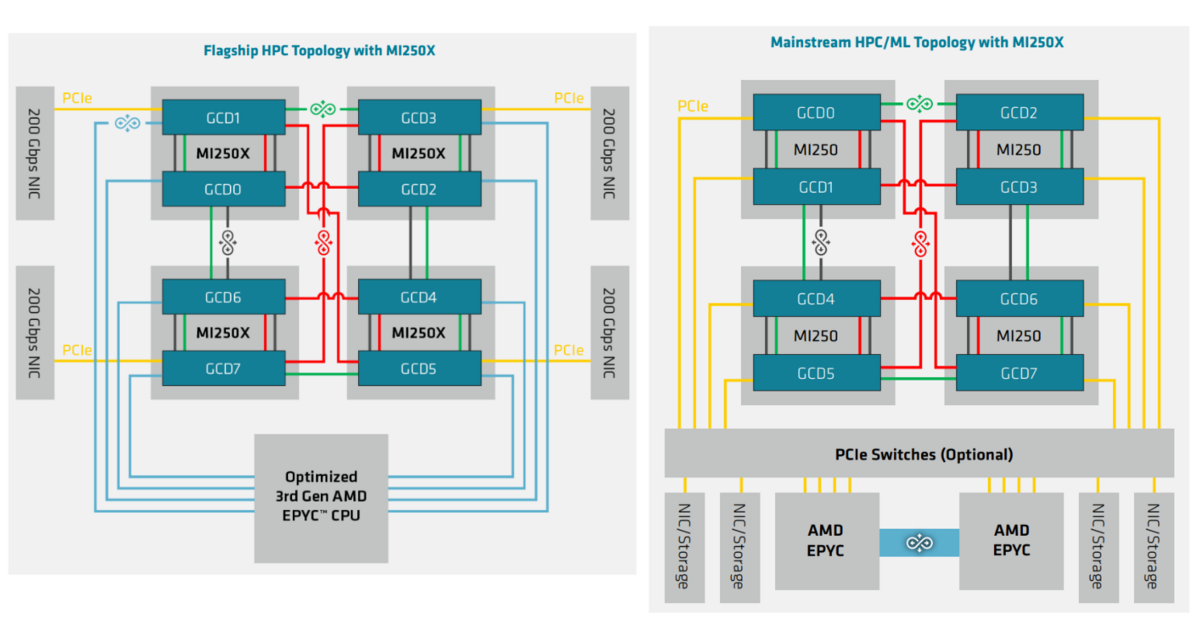
左側は、EPYC CPUと Infinity Fabric で MI250X の各die と接続するケースです。EPYC CPU からは 8 組の Infinity Fabric が出ているのでこのような構成ができます。NICは MI250X の PCIe x16 に接続します。
右側は、PCIe Gen4 x16 経由で EPYC CPUと接続するケースです。
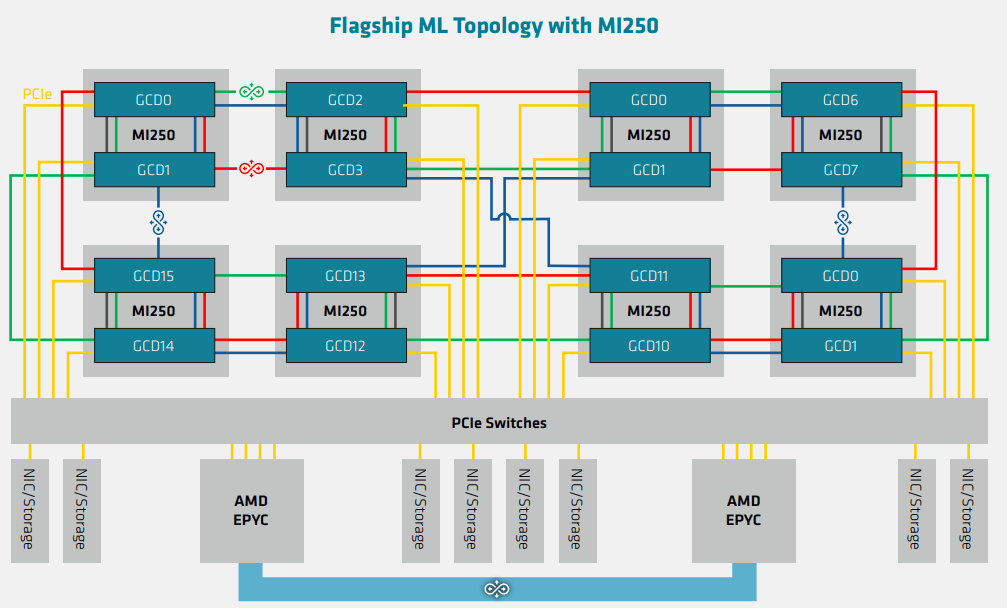
こちらは、8基のMI250Xを搭載するケースです。各MI250Xの各dieとEPYC CPUはPCIe Gen4 x16で接続しています。16組の PCIe Gen4 x16 が必要なので、PCIe Switches は必要になります。
MI300A
下記は、MI300A x 4基の構成です。
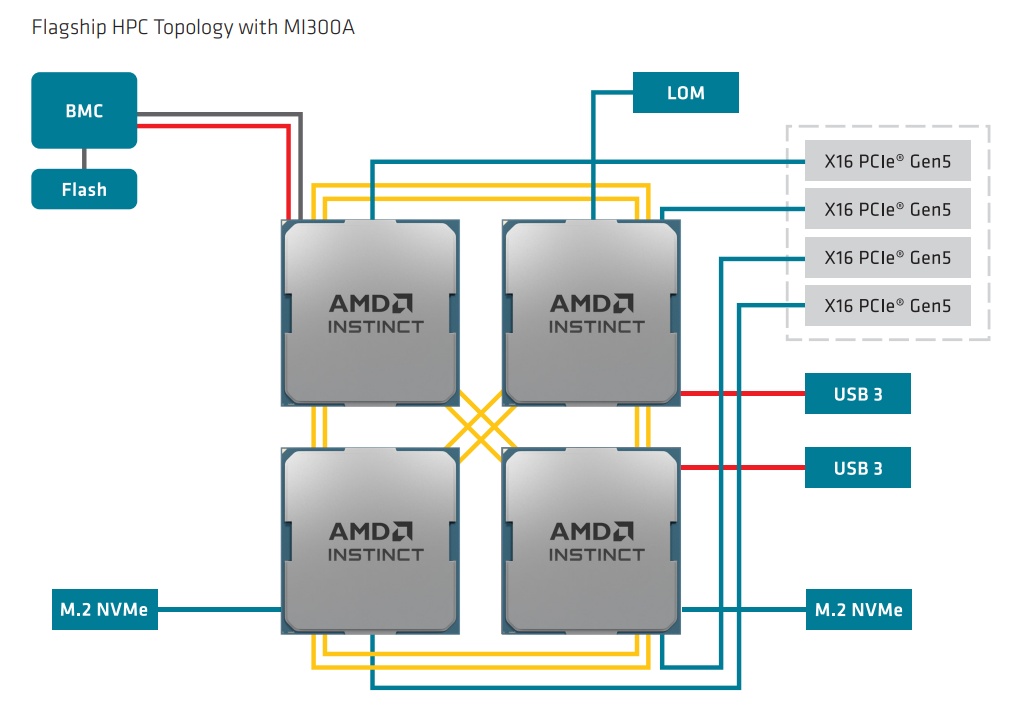
MI250Xとの比較のために並べてみました。
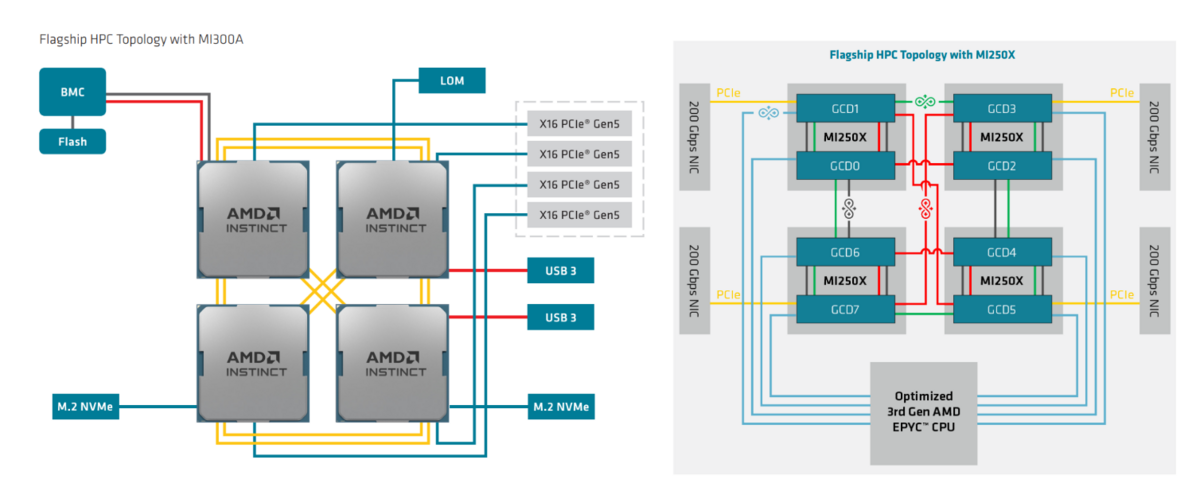
構成要素としては、
- MI250X のケース : EPYC CPU (CPU: 64コア)+ MI250X x 4 (GPU:204 x 4 = 816 CUs)
- MI300A のケース : MI300A x 4 (CPU:8x3x4 = 96コア), (GPU:76 x 3 x 4 = 912 CUs)
です。
CPUコア x 8 で、GPU die を 1個管理するようになっているのは、MI250X と MI300A では変わりません。
MI300X

MI300X の時は、MI250X と同様な構成になっています。
- MI250X : EPYC CPU x 2 (64 x 2 = 128コア)、MI250X x 8 (8コアで 1 GPU die)
- MI300X : EPYC CPU x 2 (96 x 2 = 192コア)、MI300X x 8 (6コアで 1 GPU die)
MI300A では、8コアで 1 GPU die でしたが、MI300X では、6コアで 1 GPU die になっちゃいますね。なんかバランス悪いですね。
おわりに
AMDの場合、
- MI100 (TSMC 7nm, 1 die, 120 CUs, Infinity Fabric x 4 + PCIe x16)
- MI250X (TSMC 6nm, 2 dies, 220 CUs, Infinity Fabric x 7 + PCIe x16)
- MI300X (TSMC 5nm/6nm, 13 dies, 304 CUs, Infinity Fabric x7 + PCIe x16)
MI250X => MI300X になって、一気に難易度が上がったと思います。各 die のサイズが小さくなったことで単価が下がり、数量が増えますが、1つのパッケージに13 die (3種類)も載っているのでそれなりのコストはかかっていると思います。CPU die は、EPYCやThreadRipper/Ryzenでも使われているのと、die sizeが小さいのでかなりコストがお安いとは思いますが。。。