はじめに
NVIDIA Grace-Hopper Superchipの間は、NVLINK C2C にて接続されています。
理論最大転送帯域は片側 450GB/s です。
実測は?
Google君に聞いたら、
に次のようなデータがありました。
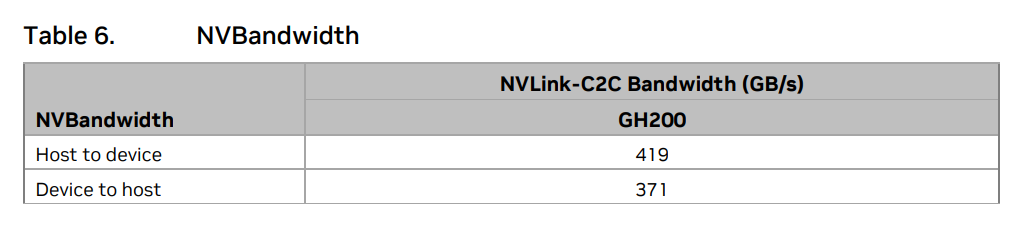
NVLINK C2C は、片側 450GB/s なので CPU => GPU に関してはイイ感じにでています。これは、Grace 内のL3 Cache => NVLINK C2C でデータをリードした時にここまで出ているのではないでしょうか? 何故なら、LPDDR5Xからの実測での転送帯域は昨日のブログの
- 120GB : 512GB/s
- 480GB : 384GB/s
です。
によると、GH200-120GB では、
です。
上記の測定値と比べると、CPU => GPU はほぼ同じで、CPU <= GPU は、371 GB/s と 295.47 GB/s になっています。
おわりに
最大転送帯域は、片側 450GB/s でしたが、
ということです。CPU => GPU に関しては、CPU内のL3 Cache (117MB) がありそれなりにヒットしている可能性が高い。一方、CPU <= GPUは、GPU側のメモリネックなんでしょうか? H100のメモリは HBM3 で 1個 600GB/s 程度 (5個で3TBなので、600GB/s)。メモリコントローラは 512bitなので、600GB/s の半分の 300GB/s 。L2 Cache (50MBだけど、10個のメモリコントローラに分散するので結果としては 5MB) にヒットする可能性があるのですが、ここはやはりボトルネックのひとつなんでしょうね。