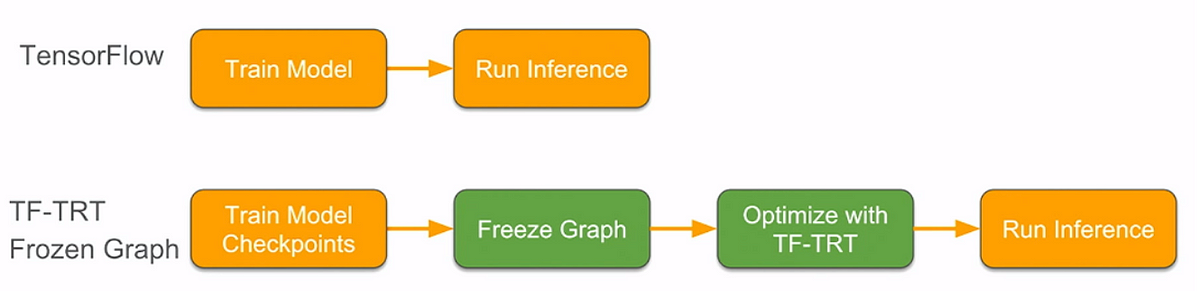
TensorFlowの学習済みモデルを使って、TensorFlow + TensorRT にて推論するといいよ、というお話。
下図にあるように、Saved Model を使って、

下記のようなコードで 読み込めばいい
import tensorflow.contrib.tensorrt as trt
trt.create_inference_graph(
input_saved_model_dir = input_saved_model_dir,
output_saved_model_dir = output_saved_model_dir)
また、Frozed Graph を読み込んで
import tensorflow.contrib.tensorrt as trt
converted _graph_def = trt.create_inference_graph(
input_graph_def = frozen_graph,
outputs-[‘logits’, ‘classes’])
TensorRT 19.2でサポートしているOpは、ここにあって、Transposeだけが未サポート。
モデルを読み込んだら、次の3つの最適化を行います。
・Graph partition : グラフをスキャンして、TensorRTでサポートしているOpをSubGraphとして分割する ・Layer conversion : TensorFlowのOpをTensorRTのOpに変換する ・Engine optimization : SubGraphを TensorRT engineの中で最適化する
元のグラフをSubGraphに分割するとき、あまりにも少ないOpだけで分割するとオーバーヘッドがあるので良くない。
そこで、create_inference_graphのパラメータとして、minimum_segment_sizeとして、3を設定し、
最低でも3つのOpを含むような場合のみSubGraphに分割するようにできます。
そこで、create_inference_graphのパラメータとして、minimum_segment_sizeとして、3を設定し、
最低でも3つのOpを含むような場合のみSubGraphに分割するようにできます。
converted_graph_def = create_inference_graph(
input_saved_model_dir=model_dir,
minimum_segment_size=3,
is_dynamic_op=True,
maximum_cached_engines=1)
import tensorflow.contrib.tensorrt as trt
calib_graph = trt.create_inference_graph(…
precision_mode=’INT8',
use_calibration=True)
with tf.session() as sess:
tf.import_graph_def(calib_graph)
for i in range(10):
sess.run(‘output:0’, {‘input:0’: my_next_data()})
# data from calibration dataset
converted_graph_def = trt.calib_graph_to_infer_graph(calib_graph)
量子化では、このスライドの7頁目にあります。
この資料の発表者:Pooya Davoodi (NVIDIA), Guangda Lai (Google), Trevor Morris (NVIDIA), Siddharth Sharma (NVIDIA)は、
ブログの人と同じです。
この資料の発表者:Pooya Davoodi (NVIDIA), Guangda Lai (Google), Trevor Morris (NVIDIA), Siddharth Sharma (NVIDIA)は、
ブログの人と同じです。
ResNet50 v1.5で9倍、MobileNet v1で10倍高速になったと。
その次の頁(8頁)には、Inceptionで8倍、VGGで7倍、NASNet L/Mで4倍、SSD MobileNet v1で3倍になったと。
9頁では精度について書いてあって、ほとんど劣化していないと。(INT16で0.1%、FP16で0.2%の劣化)
その次の頁(8頁)には、Inceptionで8倍、VGGで7倍、NASNet L/Mで4倍、SSD MobileNet v1で3倍になったと。
9頁では精度について書いてあって、ほとんど劣化していないと。(INT16で0.1%、FP16で0.2%の劣化)
12頁では、ResNet50 v1.5では741ノードが12ノードになり、その内、1つがTRT nodeである。
あー、ノード置き換えの時に、TRT node にするんじゃなくて、TensorRT内の複合ノードに置き換えちゃうのね。
ノード数が減れば、GPU起動のオーバーヘッドも減るからね。。。
各Opの実行時間が短ければ起動のオーバーヘッドは大きいからね。
ノード数が減れば、GPU起動のオーバーヘッドも減るからね。。。
各Opの実行時間が短ければ起動のオーバーヘッドは大きいからね。
TensorCoreは、precision_mode を INT8 or FP16 にすれば、自動的に使われるのね(22頁)
33頁、trtGraphConverterの引数で precision_mode = 'INT8' で use_calibrationをFalse にしてコンバートすると、
Quantization-Aware Training として、Op間にFakeQuant Op を追加するしちゃうようです。
Quantization-Aware Training として、Op間にFakeQuant Op を追加するしちゃうようです。