@Vengineerの戯言 : Twitter SystemVerilogの世界へようこそ、すべては、SystemC v0.9公開から始まった
はじめに
TwitterのTLに流れてきたもの。
AMDのGPUのメモリが128GB。NVIDIAのA100は40GB/80GBなのでそれより1.5倍。
AMD
最初に観たツイートは、これ。説明のために引用します。
A high level diagram for AMD's upcoming CDNA2/Aldebaran product MI200.
— Locuza (@Locuza_) 2021年7月1日
Physically it's a hefty scaling, from 64 CUs on Vega20 to 128 on CDNA1 to now 2x128 on MI200(CDNA2).
Total interface width doubles from 4096b HBM2 to 8192b HBM2e.
Capacity quadruples from 32GB to 128GB. pic.twitter.com/a95o2JbYux
2 die で、1 die に 64GBのHBM2メモリが接続しています。4 チャネルなので1チャネル当たり16GBメモリ。 NVIDIA A100の80GB版は、6チャネルのHBM2の内、5チャネルを使うようになっているので1チャネル当たり16GBで同じ。 NVIDIA A100の場合は、1 die だけど、AMDのMI200は 2 die で 4 チャネルなので、2 x 4 x 16 = 128GB ということに。
NVIDIAの場合、チップ間は NVLink で接続しているけど、この AMD MI200 は Die-to-Die Crosslinks となっています。 実際にどのくらいの転送レートをサポートしているのでしょうか?
die には、この他に
- I/O Ports for PCIe & XGMI
- 2x SDMA + 3x XGMI Control
とあります。
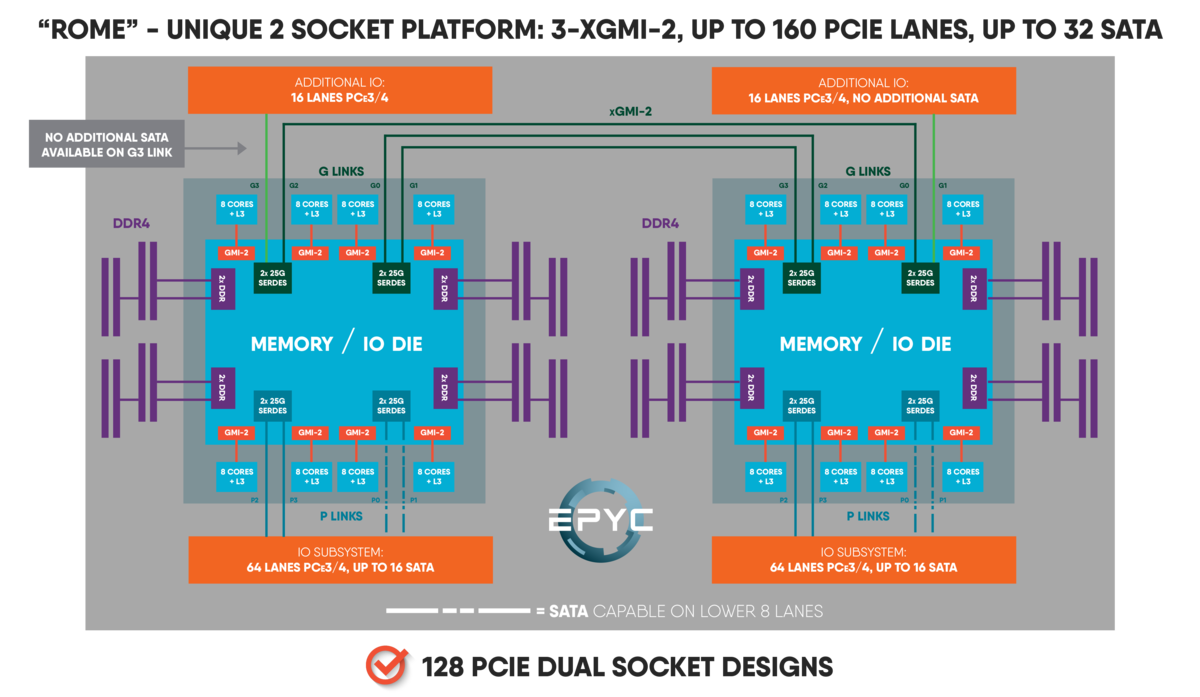
XGMI って、AMD EPYC のチップ間接続用に使っているものと同じなんでしょうか?
AMD EPYC ROMEの場合は、下記の記事の図にどんな感じに使っているのかが載っています。
記録のために、画像を引用します。