はじめに
Intel の Sapphire Rapids に、HBMが付いているものがあるのですが、なんで、かな?-とずーと思っていたのです。
HBMが付いている意味が分かった
とあることで調べ物をしていたら、Xeon Phi Knight Lighting がそっくりな構成だったということが分かったのです。
下記の記事は、2016年6月の ISC(International Supercomputing Conference) 2016 で発表された「Xeon Phi Knight Lighting」についてです。
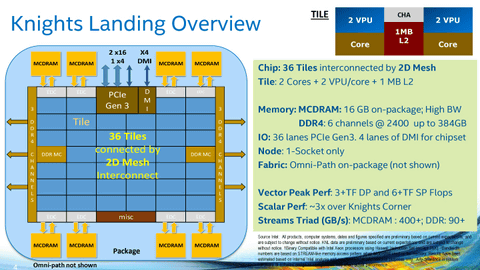
下図は上記の記事から説明のために引用します。Knights Landing は、DDR4 x 3 channel が2つで合計 6 channelの他に、MCDRAM が 8個で16GB接続しています。CPUコアに対応するものは、36 Ttiles
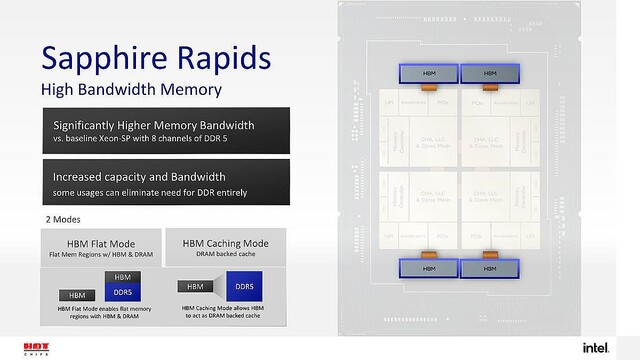
下図は、最初に引用した記事からです(説明のために引用します)。Sapphire Rapds は、DDR5 x 8 channel、HBM2e x 4 で 64GB接続しています。CPUコアは、最大 15 x 4 = 60 コア。下図には、HBMを
- Flat Mode
- Caching Mode
の2種類で使い分けできるようです。Caching Modeにすることで、64GBもの Cache になります。
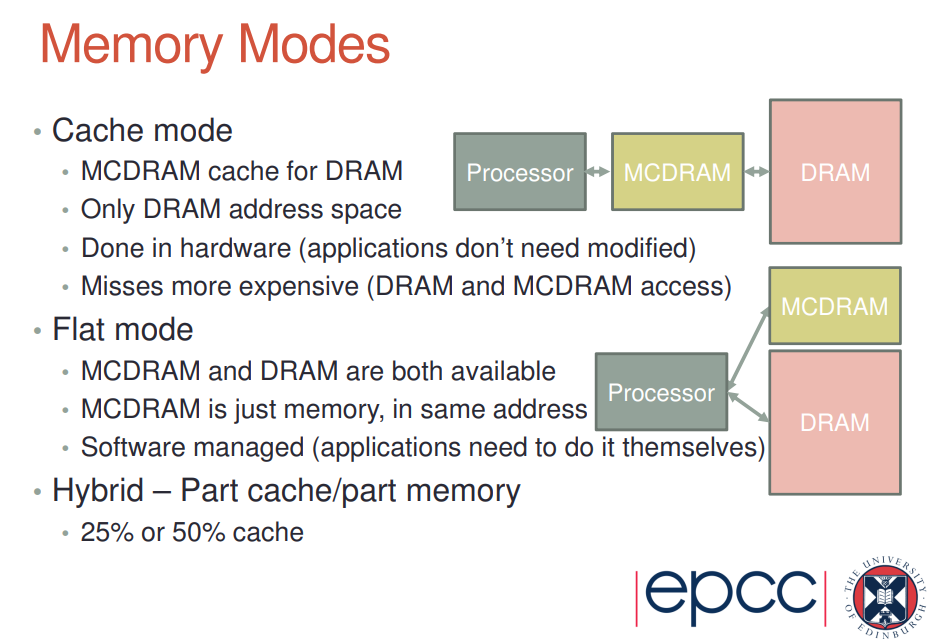
Xeon Phi Knight Landing についても、同じような使い方ができるようです。下図は、INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER から説明のために引用します。
- Cache Mode
- Flat Mode
と、Sapphire Rapids の HBM と同じですね。
もうちょっと、調べてみた
news.mynavi.jp の中の 図にある 2016年頃の Supercomputer は Intel Xeon/KNL になっています。
その図を説明のために引用します。
- Argonne : Theta
- CORI : LBNL
- Trinity : LANL/SNL
は、Cray/Intel Xeon/KNL です。KNLは、Knight Landingの略称です。

そして、その後の更新 (記事は2019年なので、それ以降についてわかる範囲で追記してます)では、
- Argonne (2021-2023) : A21 => Aurora (Intel Sapphire Rapids + Ponte Vecchiro)
- LBNL (2021) : Perlmutter (AMD Milan + NVIDIA A100)
- LANL/SNL (2023) : Crossroads (Cray : Intel Sapphire Rapids)
になっています。
Perlmutterは、AMD Milan + NVIDIA A100 の GPGPU ベースになりましたが、他の2つは Intel Sapphire Rapids を採用しています (ただし、Auroraはかなり遅れているようです)
Xeon Phi Knight Landings のノウハウが再利用できる?
となると、Xeon Phi Knight Landingsでの Cache mode / Flat mode でのノウハウの再利用できるのでは?
例えば、
- Knights Landing✝ プロセッサーにおける高帯域幅メモリー (HBM) としての MCDRAM:開発者ガイド
- Intel Xeon Phi (Knights Landing) のパフォーマンス評価の⼀例
- Introduction to Intel Xeon Phi (“Knights Landing”) on Cori
おわりに
いやー、Intel Sapphire Rapids の HBM の秘密がわかって、すっきりしました。