その部分については、
今年のクリスマス(2017年12月25日)に発売予定の
インターフェース、2018年2月号の掲載されるであろう記事にちょこっと書いています。
今年のクリスマス(2017年12月25日)に発売予定の
インターフェース、2018年2月号の掲載されるであろう記事にちょこっと書いています。
あたしの記事は、TensorFlow XLA の JITに関するもので、TensorFlow r1.4に対応しています
原稿を書き終えてから、いろいろと整理してみて、感じたことは。。。
ということ。
SystemCが盛り上がった2000年頃は、日本の半導体開発は非常に盛り上がっていました。
どうしてなんでしょうか?
あたしが考えるには、
ハードウェアを作っても、その上のソフトウェアである ・デバイスドライバ ・ファームウェア(ランタイム) ・ライブラリ ・コンパイラセット が無いと現実的には使えない。ということ。つまり、ハードウェアはできるが、ソフトウェアというエコシステムの構築ができないから。
そういう意味で、TensorFlow XLAを見てみるとめっちゃ面白いんですよ。
そして、その対抗として出てきた、「NNVM + TVM」もめっちゃ面白くて、
TensorFlow 以外のフレームワークは、ONNX にて、NNVM + TVM へのパスを作っていますからね。
そして、その対抗として出てきた、「NNVM + TVM」もめっちゃ面白くて、
TensorFlow 以外のフレームワークは、ONNX にて、NNVM + TVM へのパスを作っていますからね。
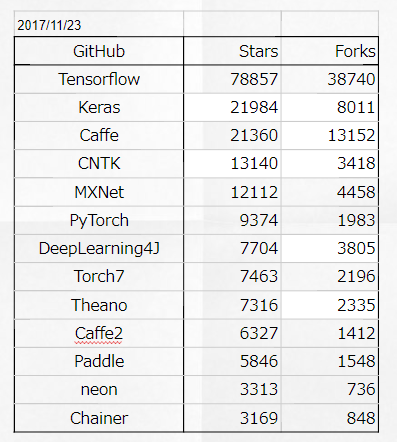
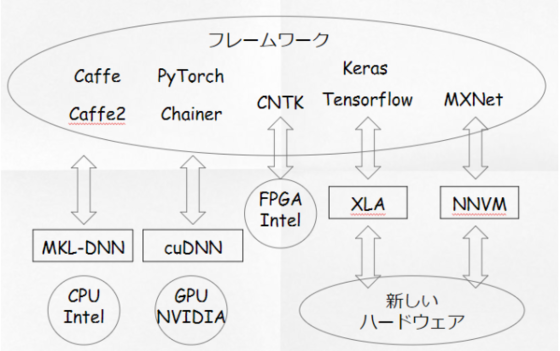
ちょっと面白いのは、Intel。ハードウェアを開発しているIntelは、どんなフレームワークでも使ってもらいたい。
なので、
Intel NNP(旧Crest)では、XLAやTVMをサポートしています。また、ONNXにも参加しているんですよね。。。
なので、
Intel NNP(旧Crest)では、XLAやTVMをサポートしています。また、ONNXにも参加しているんですよね。。。
あー、そうだ、Khronos groupのNNEF : Standards for Vision Processing and Neural Networksもありますが、
こちらはどちらかと言うとIPベンダーとそのIPを搭載した(する)SoC(ASSP)ベンダーの集まりって感じですかね。
こちらはどちらかと言うとIPベンダーとそのIPを搭載した(する)SoC(ASSP)ベンダーの集まりって感じですかね。