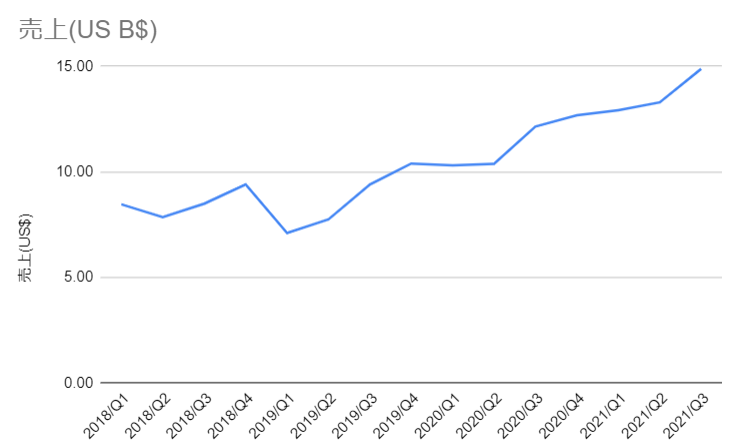
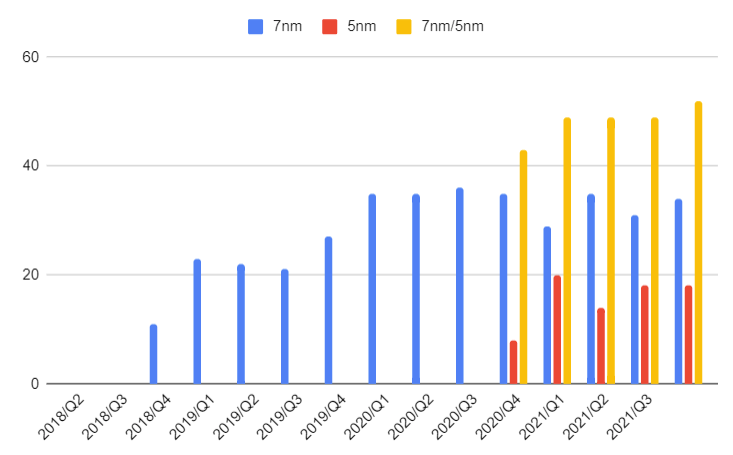
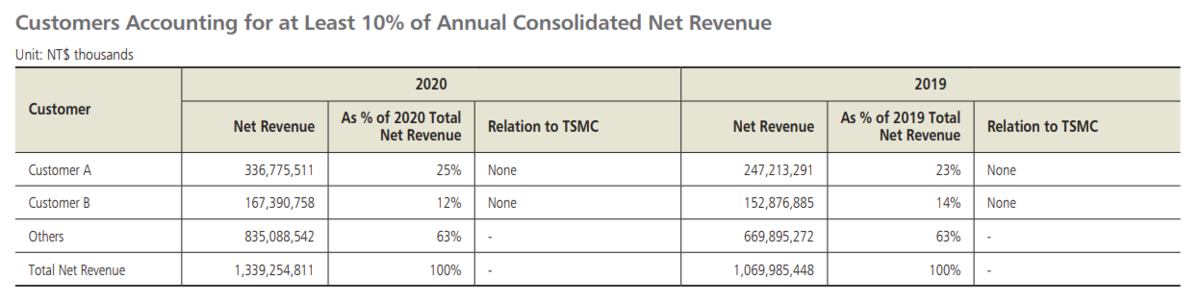
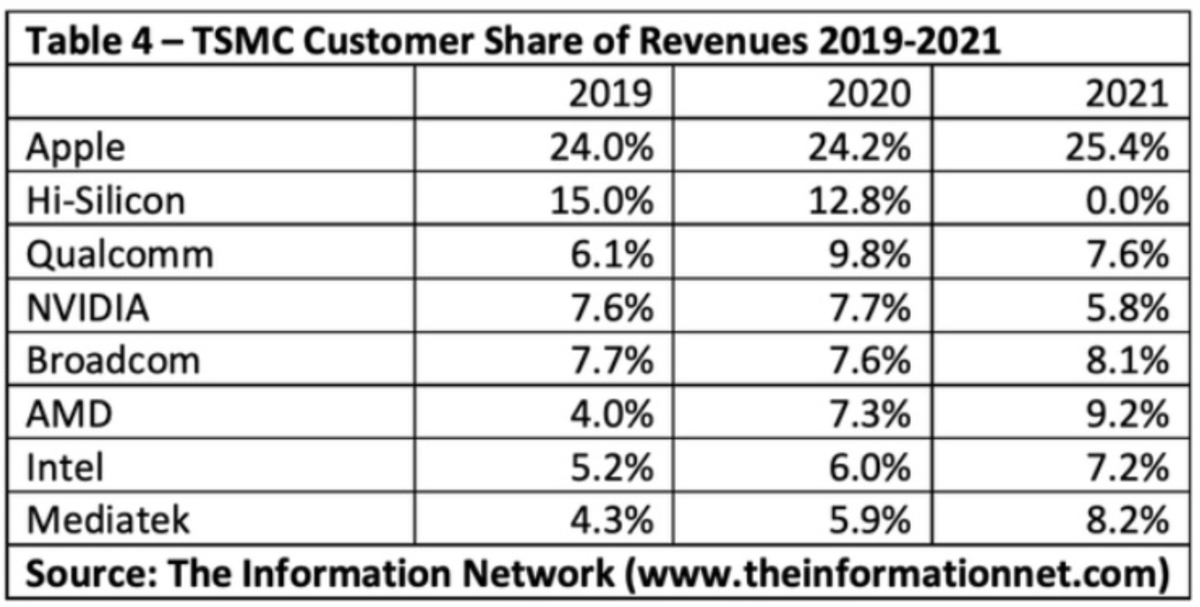
はじめに
2021年9月7日のこのブログに書いた「定年後の暇をどうするか?を考える (その1)」
の、「雑談、1on1」の続編です。
どのくらいやったのか?
38名の内容は、下記のように、雑談、1on1、だけでなく、相談もありました。 相談の方については、その後、1on1を行いました。
- 雑談、17名
- 1on1、21名 <= 11名
これ以外に相談、2名
1on1 の方が 雑談より多くなりました。この2週間で10名の方と 1on1 をやりました。
- 8月 (4名) : 雑談(4名)
- 9月 (16名) : 1on1 (4名)、雑談(12名)
- 10月 (18名) : 1on1 (16名)、雑談(2名)
多い週では、5名の方と、雑談、1on1 をやりました。
今月、あとは、雑談が1回、予定しています。
1on1 では、1時間じゃ足りないですー
1on1 をやってみて感じたことは、1時間じゃ足りません。最初の30分から45分ぐらいであたしからの5つの質問に対する答えをお聴きます。その後の時間は、あたしに対する質問等の時間になります。 最初の30分で5つの質問が終われれば、残り30分ありますが、時間が経ってしまいます。なので、1on1 をお願いする時に、1時間30分から最大2時間でお願いすることとしています。
不思議なんですが、変化があったタイミングの 1on1 が多かった
1on1 の 21名の方で 前後半年ぐらいでお仕事に変化があった・ある人が多かったです。確認したら、21名中11名が変化があった人でした。
なので、質問の「今のお仕事って何?」が今までのお仕事というのが多かったです。
在宅勤務
この1年半で通勤という概念が無くなり、在宅勤務でも仕事ができることがわかってしまいました。定年になったら絶対に通勤はしたくないです(今もできれば通勤したくないです)。
1on1の中でも在宅でお仕事するのはごく当たり前になり、多くの人が在宅を希望している人がいるのを知りました。(会社に行って仕事をするのが好きという人もいるので全員が在宅勤務を望んでいるわけではないです)。
在宅勤務で仕事ができるということがOKなら、距離を気にすることはなくなります。どこに居ても、ネットワークの状態が良ければどこでも仕事ができるわけです。
おわりに
50名と、雑談、1on1 をするか? 25名と、1on1 を行うのが当面の目標です。既に 1on1 を 21 名を行っているので、11月中旬ぐらいには達成できそうです。
そしたら、何をやるの? と言われることがあるんですが、
第2フェーズとしては、雑談、1on1 をやった人と、2回目をやろうと思っています。2回目のお題(内容)はまだ決めていませんが、同じ内容のことについて聴いてみたいと思っています。
たとえば、
- 今、何をやっているときが楽しいですか?
- 1年間好きなことができるようになったら、何をしたいですか?
- 制約が無くなったら、何をしたいですか?
とかです。