はじめに
NVIDIA A100にて、L2 Cacheの構成が変わったことは、下記のブログで書きました。
vengineer.hatenablog.com
今回は、L2 Cache のサイズが、P100の4MB、V100の6MBから A100 では 40MB (48MB)、H100 では 50MB (60MB) になって、その利用について調べてみました。
NVIDIA GA100 の L2 Cache
A100 の L2 Cache は、40MB (GA100では 48MB ですが、A100 としては 40MB しか使えません) と、V100 の 6MB から 大きく増えました。
前回のブログで書いたように、GA100 の L2 Cacheは2つのブロックに分割され、各ブロックは 20MB。20MB は、512KB x 40 個という構成になっています。
GA100は、6個のHBM2e が接続していて、各HBM2e で2個のメモリコントローラが付いています。合計で12個です。各メモリコントローラには、8個の512KBのL2 Cacheが付いているようです。
12 x 8 x 512KB = 48MBです。A100では、6個のHBM2eの内、5個のHBM2eが使えます。したがって、L2 Cache は 10 x 8 x 512KB = 40MB になります。
追記)、2024.02.11
20MB + 20MB になっているのではなく、24MB + 24MB になっていて、一方が24MB、もう一方が16MBになったいる感じ。何故なら、1つのHBM2e Memory Controllerが使われていないので、8MB x 3 MC + 8MB x 2 MC で 40MBとなっている。
NVIDIA GH100 の L2 Cache
H100 の L2 Cache は、50MB (GH100では 60MB ですが、H100 としては 50MB しか使えません) です。H100 の L2 Cache は GA100と同様に2つのブロックに分割され、各ブロックは 30MB。30MB は、512KB x 60 個という構成になっています。
GH100は、GA100と同様に、6個のHBM2e/HBM3 が接続していて、各HBM3 で2個のメモリコントローラが付いています。各メモリコントローラには、10個の512KBのL2 Cacheが付いているようです。
12 x 10 x 512KB = 60MBです。H100では、 6個のHBM2eの内、5個のHBM2eが使えます。したがって、L2 Cache は 10 x 10 x 512KB = 50MB になります。
L2 Cache にデータを常駐できる
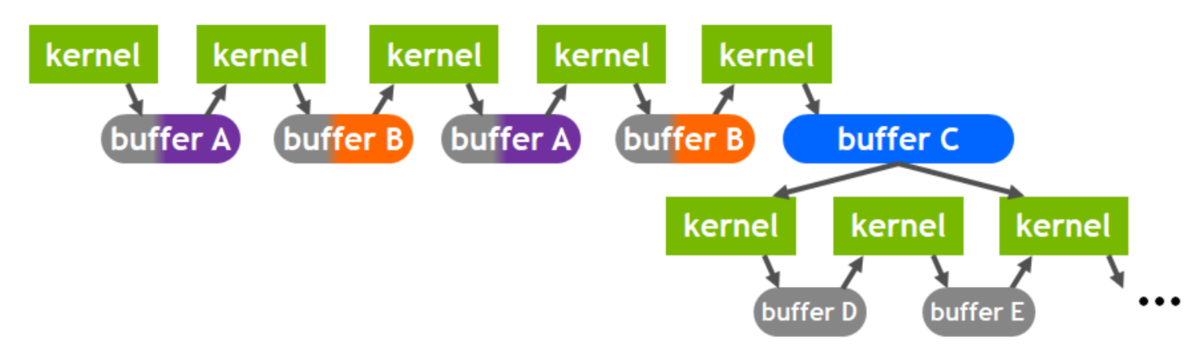
GA100 から L2 Cache には、データを常駐できるようになりました。データをL2 Cacheに常駐できると何が?お得かというと、下図 (NVIDIA A100 Tensor Core GPU Architectureの41ページから説明のために引用します)のように Kernel 間で使うデータを L2 Cache に常駐することで DRAMへのアクセス時間からL2 Cacheへのアクセス時間に短縮できるということです。
L2 Cache は、データを圧縮する
下図 (NVIDIA A100 Tensor Core GPU Architectureの41ページから説明のために引用します)のように L2 Cacheではデータを圧縮できるようです。

V100 と A100 の性能比較
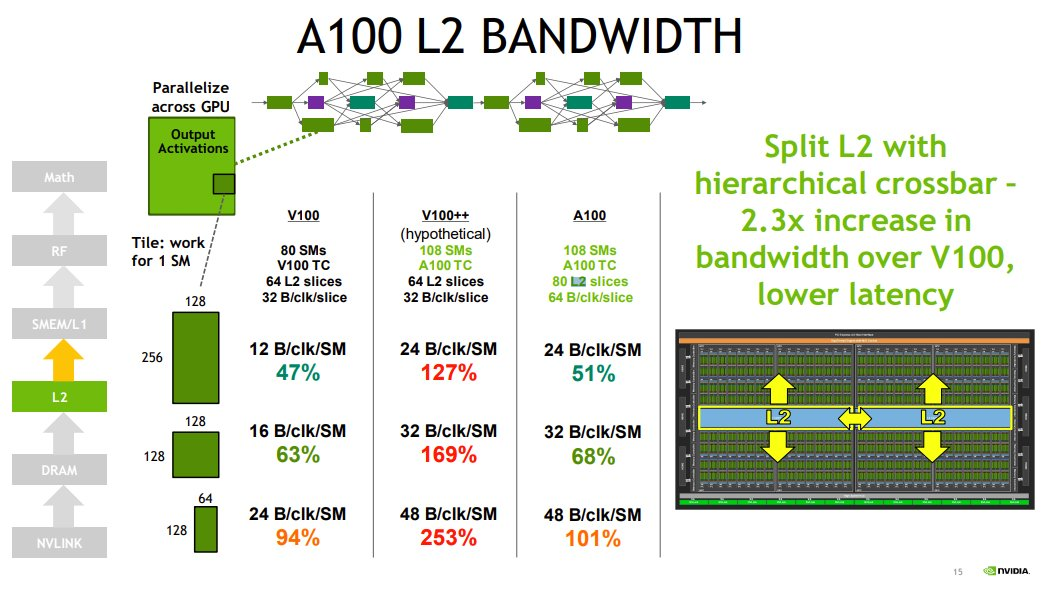
L2 Cacheの容量は、V100に対して、6.7 倍、L2 CacheへのBWは 2.3 倍
圧縮すると、容量は、13.3 倍、L2 CacheへのBW は 9.2倍

追記)、2024.02.11
H100の帯域は?
下記の記事に、H100の内部構成があります。
chipsandcheese.com
下図は上の記事から説明のために引用します。512KB が 10個あるのではなく、640KB が 8個あるようです。
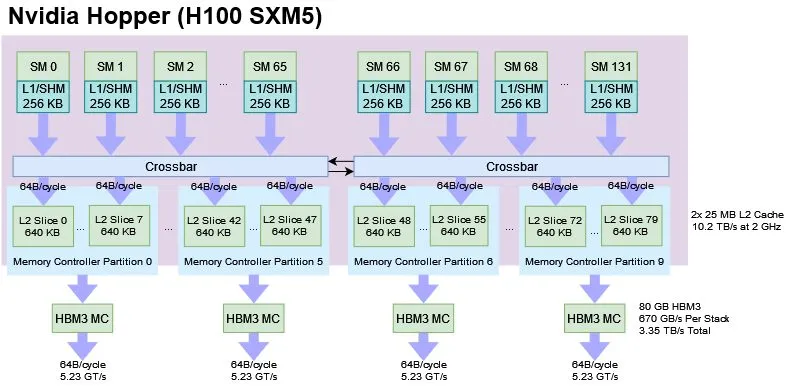
L2 Cacheには、64B/cycleでアクセス。64Bなのは、HBM3 Memory Controllerが512ビット(64バイト)だからでしょうか?
動作周波数は、PCIe版では Max 1.755GHz です。SMX版は分かりません。nvidia-smi を実行すれば、動作周波数は分かると思います。
64B x 1.755GHz = 112.32GB/s
HBM3は5.23Gbpsで動いている。1024bit x 5.23Gbps = 669.44GB/s
L2 Cache は8組あるので、112.32GB/s x 8 = 898.56 GB/s
H200になると、HBM3e@6.4Gbps になるようなので、819.2GB/s まで増えますね。
ここまで追記
L2 Cache の制御
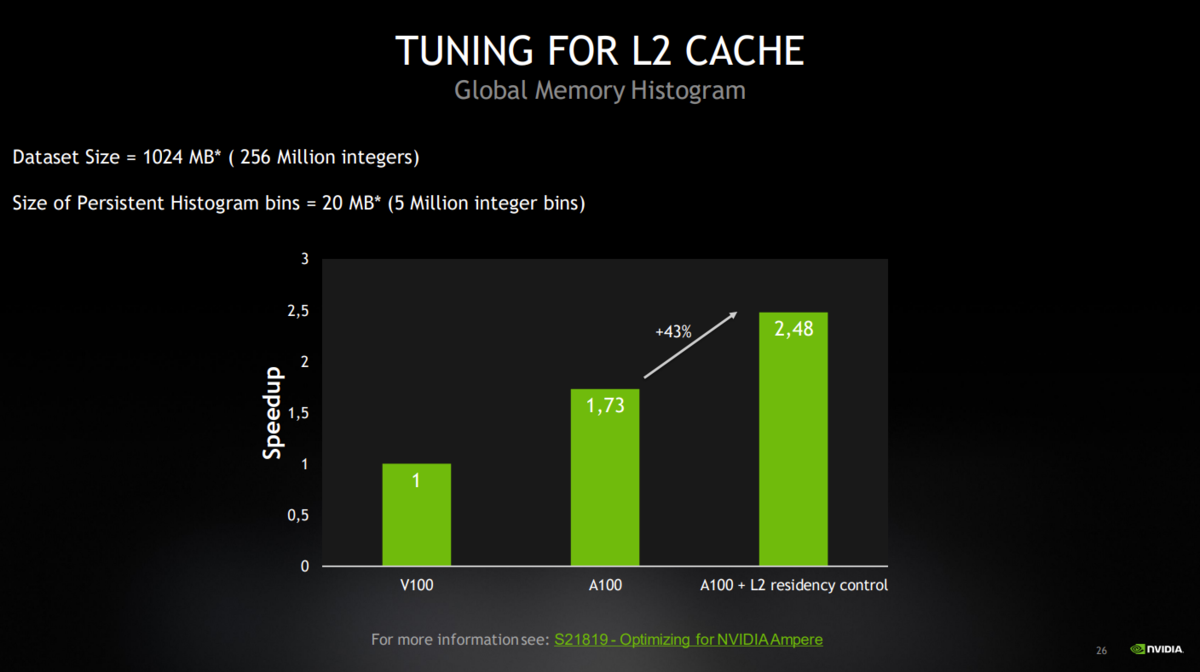
下図は、CUDA 11 AND A100 - WHAT'S NEW? の25ページ目のTUNING FOR L2 CACHE です。
accessPolicyWindow なる API を使って、L2 Cache のデータを常駐することができるようです。

num_bytes でサイズを指定できますが、上記に書いたように 1つのメモリコントローラには、GA100で8個、GH100で10個です。GA100 で 8 x 512KB = 4MB、GH100 で 10 x 512KB = 5MB です。
となると、このサイズを超えるように設定すると、どうなるんでしょうかね。。。
CUDAのドキュメントによると、
cudaGetDeviceProperties(&prop, device_id);
size_t size = min(int(prop.l2CacheSize * 0.75), prop.persistingL2CacheMaxSize);
cudaDeviceSetLimit(cudaLimitPersistingL2CacheSize, size); / set-aside 3/4 of L2 cache for persisting accesses or the max allowed/
のように、prop.l2CacheSize で L2 Cache Size を獲得できるんですね。そして、prop.persistingL2CacheMaxSize で常駐できる最大サイズも獲得できるんですね。
これによって、下記(同じ資料の 26ページ目)のように V100 より、2.48倍、速くなるようです。
こちらも
おわりに
A100のL2 Cacheについて、調べていたら、こんなことになりました。
関連ブログ
vengineer.hatenablog.com