はじめに
NVIDIA A100 から L2 Cache の構成が変わったようです。
L2 Cache の構成
NVIDIA GV100(Volta) の L2 Cache は、下記のようになっています。Volta Architecture WhitepaperのPage 17 から説明のために引用します。
下記のように、6つの GPC に対して、L2 Cache がつながっているような図になっています。

一方、GA100(Ampere) の L2 Cache は、下記のようになっています。Ampere Architecture WhitepaperのPage 16 から説明のために引用します。
下記のように、4つの GPC に対して、L2 Cache がつながっていて、L2 Cache 間に双方向の接続があります。
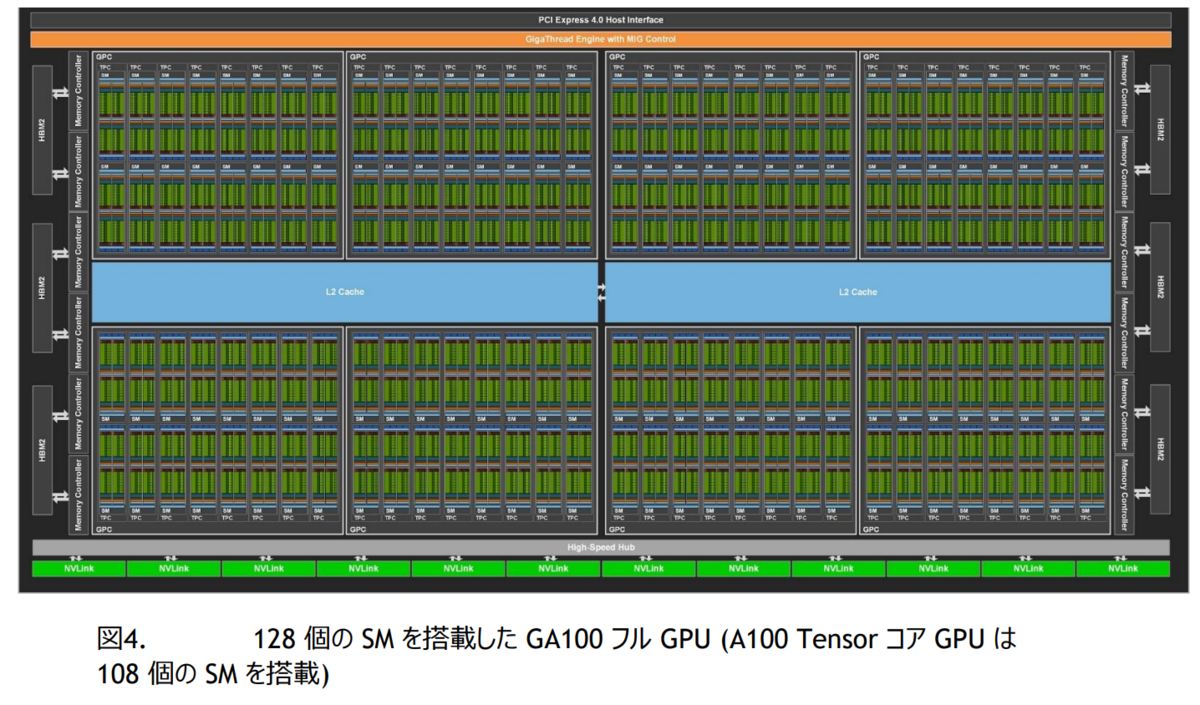
GV100のSMは、84、GA100のSMは128です。
GH100 (Hopper)は、どうでしょうか?
下記のようになっています。 Hopper Architecture Whitepaper のPage 19ら説明のために引用します。
下記のように、GA100と同じように、4つの GPC に対して、L2 Cache がつながっていて、L2 Cache 間に双方向の接続があります。
GH100のSMは、144です。

SMが84までは、1つの L2 Cache 構成。GA100のSM (128)、GH100のSM (144)では、2つの L2 Cache 構成。なのでしょうか?
INSIDE THE NVIDIA AMPERE A100 GPU IN THETAGPU AND PERLMUTTER, JULY 28, 2021から引用した図です。
V100に対して、L2 Cacheを2つに分離して、2.3 x の転送帯域を持っているようです。

#L2 Cache Size
GV100と GA100/GH100 の大きな違いは、L2 Cache のサイズです。GV100は6MBですが、GA100は48MB(内、A100では40MBを使用)、GH100は60MB(内、H100では50MBを使用)です。
GV100に対して、GA100/GH100 は8倍ぐらいです。
ちなみに、THE NEXTPLATFORM の DIVING DEEP INTO THE NVIDIA AMPERE GPU ARCHITECTURE では、L2 Cacheについて、下記のように分析しています。
If you compare the GV100 and GA100 block diagrams, you will see that the L2 cache on the Ampere chip is broken into two segments instead of the single L2 cache at the heart of the Volta chip. That L2 cache has been increased to 40 MB, which is a factor of 6.7X increase over the Volta chip. This is a big change, and we think that combined with the new partitioned crossbar structure that has 2.3X the L2 cache read bandwidth of the L2 cache on the Volta chip, this is a dominant factor in the raw performance improvements Ampere will shows over the Volta chip on raw performance on like-for-like FP32 and FP64 and INT8 units – without sparsity acceleration or new, more efficient numeric formats in the various units on the chip. And more precisely, what we are saying is that we think real applications will show a larger improvement than is expressed in the peak throughout figures for these base units, and then will get even more performance as they employ other numeric formats and move work from the FP32 or FP64 units to the Tensor Cores and accelerate even further.
そして、西川善司の3DGE:NVIDIAが投入する20 TFLOPS級の新GPU「A100」とはいったいどのようなGPUなのか? では、L2 Cacheが大幅に増えた理由についても説明しています。
一方,A100におけるL2キャッシュ容量は大幅に増えている。GV100では6MBだったのが,A100では約6.7倍にあたる40MBにまで増えたのだ。A100のL2キャッシュ増量は,単なるGPUアーキテクチャの世代が新しくなったからではなく,A100が採用したメモリアクセスモデルの刷新によるものである。 A100では,最新版のCUDAである「CUDA 11」で採用となった「Asynchronous Copy」(非同期コピー,以下 Async Copy)と呼ばれる新しいメモリアクセスモデルに対応しており,それに合わせてGPUのメモリアーキテクチャを大幅に変えてきたのだ。
NVIDIA A100 Tensor Core GPU Architectureの61頁のCUDA Asynchronous Copy Operationでは、Async copy の説明はありますが、NVIDIA AMPERE GA102 GPU ARCHITECTUREには Async copy の記載はありません。
CUDA 11: NEW FEATURES AND BEYOND
おわりに
GeForce用の die は、TU102のSMは 72、GA102のSMは、84.ここまでは、GV100のSMの84以下なのでいいのですが、AD102のSMは、144です。GH100と同じです。となると、L2 Cache構成は、どうなるんでしょうかね。
PC Watch の GA102 のブロック図では、L2 Cache は 32ビットのGDDRXメモリコントローラの入り口についています。TU102/GA102のL2 Cacheは6MBで、12個のメモリコントローラに各512KBのL2 Cacheが付いているような感じになります。AD102のL2 Cacheは96MBです。となると、各メモリコントローラのL2 Cacheは8MBになりますね。
また、上記の L2 Cacheの増加の理由から Ada Lovelace では、GA100 での Aync Copy が本格的に使えるようになるということでしょうかね。