はじめに
Xの投稿に、NVIDIA RTX 5090 (GB202) の die shot が流れてきましたので、記録に残します。
GB202 の die shot
GB202 Dieshot/5090 Dieshot
— Kurnal (@Kurnalsalts) 2025年1月25日
Thanks By@ASUS Tony 俞元麟 by Chip
@万扯淡 by Dieshot@Kurnalsalts Layout
Photo1 GB202 Dieshot
Photo2 AD102 vs GB202
full Pixel Photo pls join in Kurnal’s Telegram teamhttps://t.co/MI6oCa2yOA pic.twitter.com/pny7bvCs5j
説明のために、AD102とGB202の比較画像を引用します。
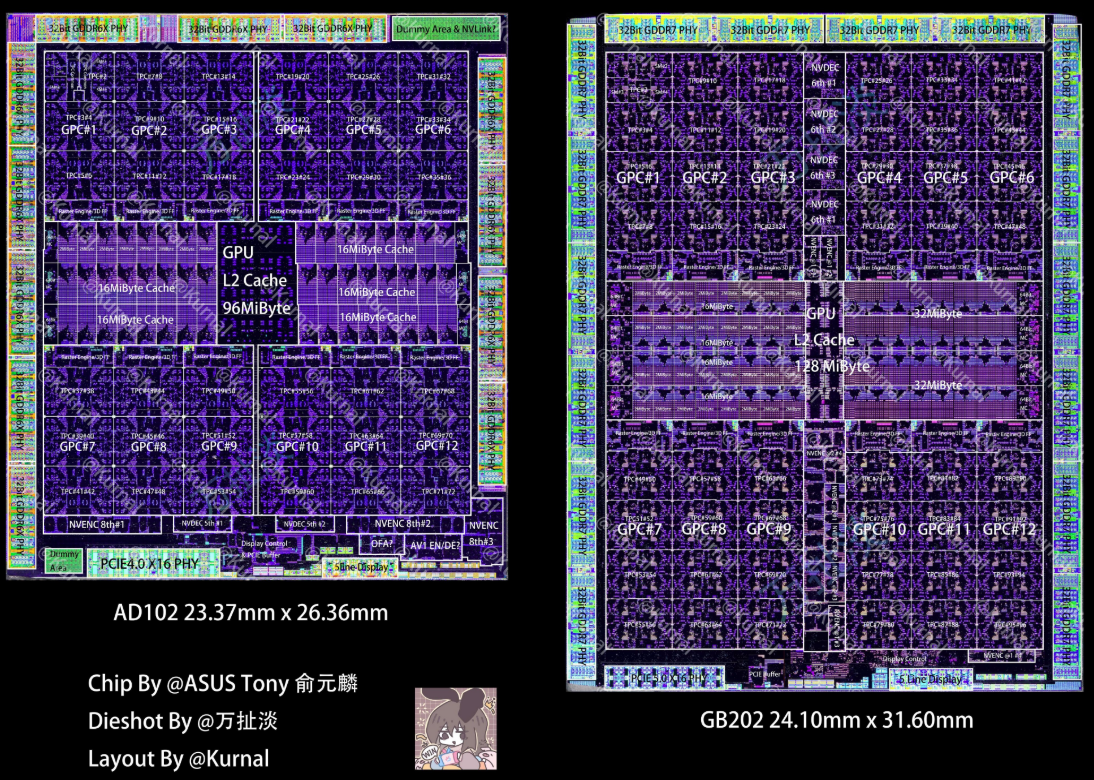
GPCの下図は、同じで 12 です。
- AD102 : TPC (72), SM (144), CUDA cores (18432), L2 Cache (96MB), Memory 384bit/GDDR6X, TSMC N4 (608.5mm2)
- GB202 : TPC (96), SM (192), CUDA cores (24576), L2 Cache (128MB), Memory 512bit/GDDR7, TSMC N4 (750mm2)
AD102 => GB202 になって、33% 増って感じですね。
- Memory Controller (32bit + 32bi) に対して、L2 Cache が 16MB
- 1つのMemory Controllerに対して、12個のTCP
RTコアスループットは、191 TFLOPS => 317.5 TFLOPS = 1.66倍、CUDA cores の数は 33%増なので、動作周波数は 1.25倍ぐらいになっているのでしょうか?
メモリ帯域は、1,008 GB/s => 1,800 GB/s は、1.7857倍なので、RTコアスループットの 1.66倍より上になっていますね。
RTX RTX 4090 は、Base Clock (2235MHz), Boost Clock (2520), Memory Clock (1313MHz)
RTX 5090 は、Base Clock (2017MHz), Boost Clock (2407MHz), Memory Clock (1750MHz)
- RTX 5090 D は、Base Clock (2017MHz), Boost Clock (2407MHz), Memory Clock (2209MHz)
Memory Clock は上がっていますが、動作周波数は逆に増えていませんね。
上記の横のサイズ、23.37 mm => 24.10 mm と 0.73 mm しか増えていないですが、真ん中に NVDEC や NVENC の回路が入っています。TCP 1個のサイズがちょっと小さくなっているんでしょうかね。
GA102 と比較
PC Watch の後藤さんの記事、NVIDIAの新アーキテクチャGPU「GeForce RTX 30」シリーズ に GA102 のブロック図があります。説明のために、下記のブロック図を引用します。
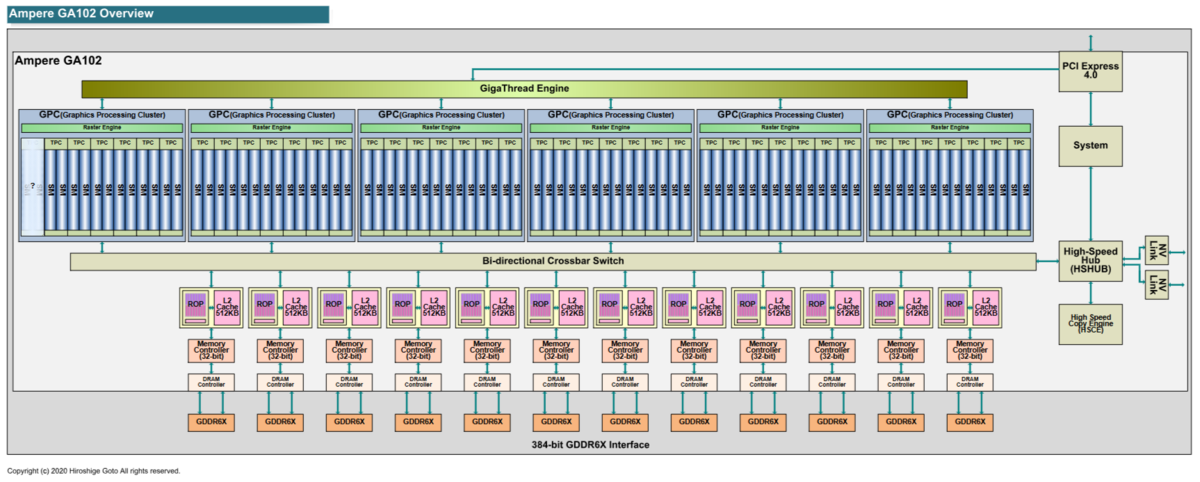
これによると、32 bit の Memory Controller に対して、512KB の L2 Cache が載っています。
Ada Lovelace や Blackwell では、64bit の Memory Controller に対して、16MB の L2 Cache が載っています。Ampere に対しては、32bit Memory Controller に対して、(16MB/2) / 512KB で、16倍になっています。
AD102 ぐらいなものは?
Blackwell では、AD102のような 384bit のメモリなものは無いですね。。。
AD103 と GB203 を比較してみると、
- AD103 : GPCs (7), TPCs (40), RT Cores (84), L2 Cache (64MB)
- GB203 : GPCs (7), TPCs (42), RT Cores (84), L2 Cache (64MB)
なので、ほぼ同じですね。。。違いは 計算器の動作周波数とメモリですかね。
つまり、AD103 を使っている人は、GB203 にする必要が無いということですね。
おわりに
AD102 と GB202 の比較では、かなり性能アップしていますね。
NVIDIA GB203 die size : 24.10mm x 31.60mm、32mm×26mm が Max なので、GDDRXのメモリは、もうこれ以上増やせそうもないね
となると、次の世代はどうやって、性能を上げるの?
あー、2 die かな?
追記)、2025.02.02
参考ブログ