はじめに
Intel が Gaudi 3 の詳細を「Intel Vision 2024」で発表しました。
www.intel.com
詳細が PC Watch の下記の記事にあります。そこに載っているスライドを引用します。
pc.watch.impress.co.jp
Gaudi 3
2023年5月には tape out
vengineer.hatenablog.com
Gaudi 3 の詳細
www.intel.com
Gaudi 3 の White Paper。Gaudi 2 の White Paper
White Paperによると、
双方向で 1200GB/s ですね。NVIDIA H100 の NVLINK v4 (100Gbps PAM4 x 2) x 18 の 双方向で 900GB/s を超えていますね。
White Paperより引用します。
- L2のメモリ帯域は、19.2 TB/s
- L3のメモリ帯域は、6.4TB/s
The Intel® Gaudi® 3 accelerator memory subsystem is equipped with L2 and L3 caches, which are coupled to each DCORE and HBM memory channels respectively.
HBM2e のチャネル (128bit x 8 channels)
下記に、Gaudi 2 (左)、Gaudi 3 (右) に並べてみました。基本的には同じですね。

- Gaudi : 16nm / TPC x 8 / MME x 1 / HBM2 32GB/1TB/s, SRAM 24MB, Ethernet 10 x 100Gb, TDP 350W
- Gaudi 2 : 7nm / TPC x 24 / MME x 2 / HBM2e 96(16)GB/2.45TB/s, SRAM 48MB, Ethernet 24 x 100Gb, TDP 600W
- Gaudi 3 : 5nm / TPC x 32 x 2 / MME x 4 x 2 / HBM2e 128(16x8)GB/3.7TB/s, SRAM 48MB x 2, Ethernet 24 x 200Gb, TDP 900W(OAM)/600W(PCIe)
Gaudi => Gaudie 2 : TPC が 3倍、MME が 2倍、メモリ容量が3倍、メモリ帯域が 2.45倍、Ethernetが 2.4 倍と。ざっくり 2 - 2.4 倍ぐらい性能が上がるっぽい
Gaudi 2 => Gaudi 3 : TPC が 2.66倍、MME が 4倍、メモリ容量が 1.3倍、メモリ帯域が 1.5倍、Ethernetが 2 倍、こちらはかなりバラけていますね。
Gaudi 2 => Gaudi 3 になって、MME が 4倍になったけど、メモリ帯域は 1.5倍、Ethernet が 2 倍。。。これって、まだまだ計算機の方が足らなかったのでしょうかね。。。
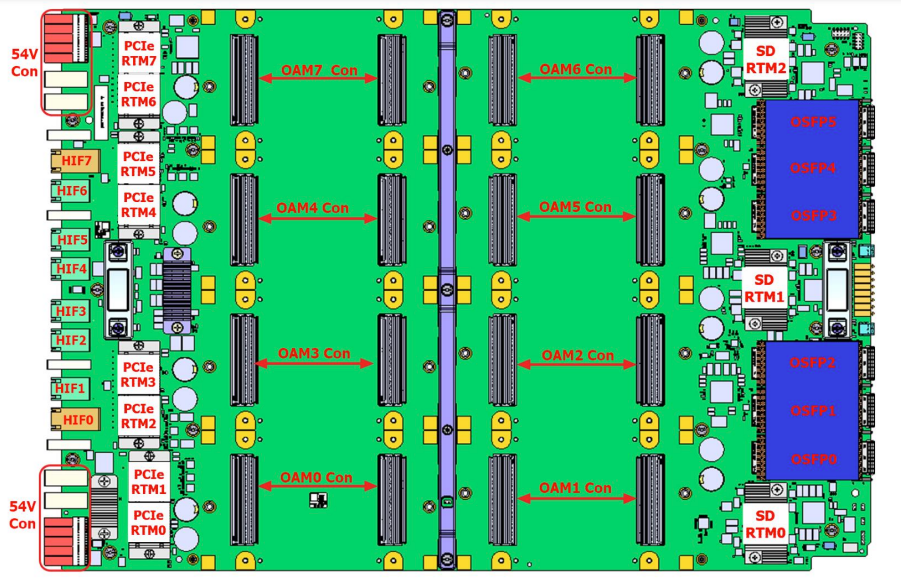
Node
Node数は、
- 1, 64, 512, 1024 まではサポートできるようですね。1024ノードだと、8192 x Gaudi 3 なので、Google TPU v5p ぐらいのクラスタは構築できるのですね。

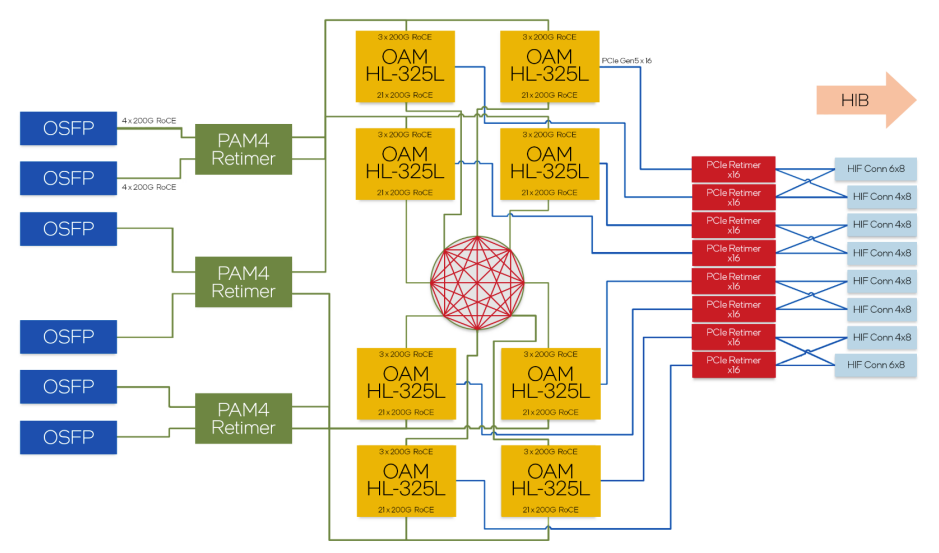
Node内の構成。各Gaudi 3 からは3組のEthernet(200Gb) が出ていて、Nodeからは 800GbE x 6 にして出していますね。
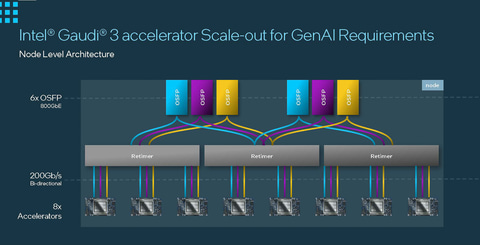
24 - 3 = 21 を使って、各 Gaudi 3 間を接続しています。どのように接続しているのでしょうか? 1つの Gaudi 3 が他の7個の Gaudi 3 と接続するのなら、3 x 200GbE で接続することになりますね。。。これは Node 外への 3 x 200GbE と同じですね。
Gaudi 2 の時は、24 x 100GbE だったので、3 x 100GbE であり、Gaudi の 時は、12 x 100GbE なので、Node内の各Gaudi は 1 x 100GbE で、Node 間では、各Gaudi から 3 x 100GbE が出ていました。
Training
- LIama2 7B : 1.5x
- LIama2 13B : 1.7x
- GPT3-175B : 1.4x
ということです。でも、H100 は メモリ容量が 80GB でメモリ帯域は 3TB/s。Gaudi 3は メモリ容量が128GB、メモリ帯域は 3.7TB/s。メモリ帯域が 1.23倍なのでこの部分を考慮しないと。
となると、
- LIama2 7B : 1.5x / 1.23 = 1.22x
- LIama2 13B : 1.7x = 1.38x
- GPT3-175B : 1.4x = 1.14x
です。
Inferenceでは、H200と比較しています。LIama とありますが、NVIDIA H200では LIama2 なので間違えだとおもいます。
- Llama2-7B : 0.8 - 1.0
- LIama2-70B : 0.8 - 1.1
- Falcon 180B : 1.1 - 3.8
LIama2 では、NVIDIA H200よりはちょっと遅いぐらいですね。H200のメモリ帯域は4.8TB/sなのでその分速い感じですね。Gaudi 3 も HBM2e ではなく、HBM3や HBM3e にすれば H200 を超えると思います。
おわりに
「Intel Vision 2024」に、Naveen Rao さんがいらっしゃいました。

Intel CEOの Pat さんとツーショット
Rao さん、Intelが買収した Nervana Systems の CEO さんです。。。
HBM3 ではなく、HBM2eな理由
"Our methodology was to use only IPs that were already proven in silicon before we tape out. At the time we taped out Gaudi3 there was simply no available physical layers that were validated to meet our standards," COO Eitan Medina told The Register