はじめに
先週発表があった Microsoft Cobalt 100 については、このブログでも 11月17日に 取り上げました。
今回は、Cobalt 100 について、もう少し深堀したいと思います。
Arm Compute Subsystems N2 (CSS N2) の振り返り
Arm CCS N2 については、下記の記事に詳しく書いてあります。8月に開催された Hotchips の資料ベースのようです。
下図は上記の記事から説明のために引用します。
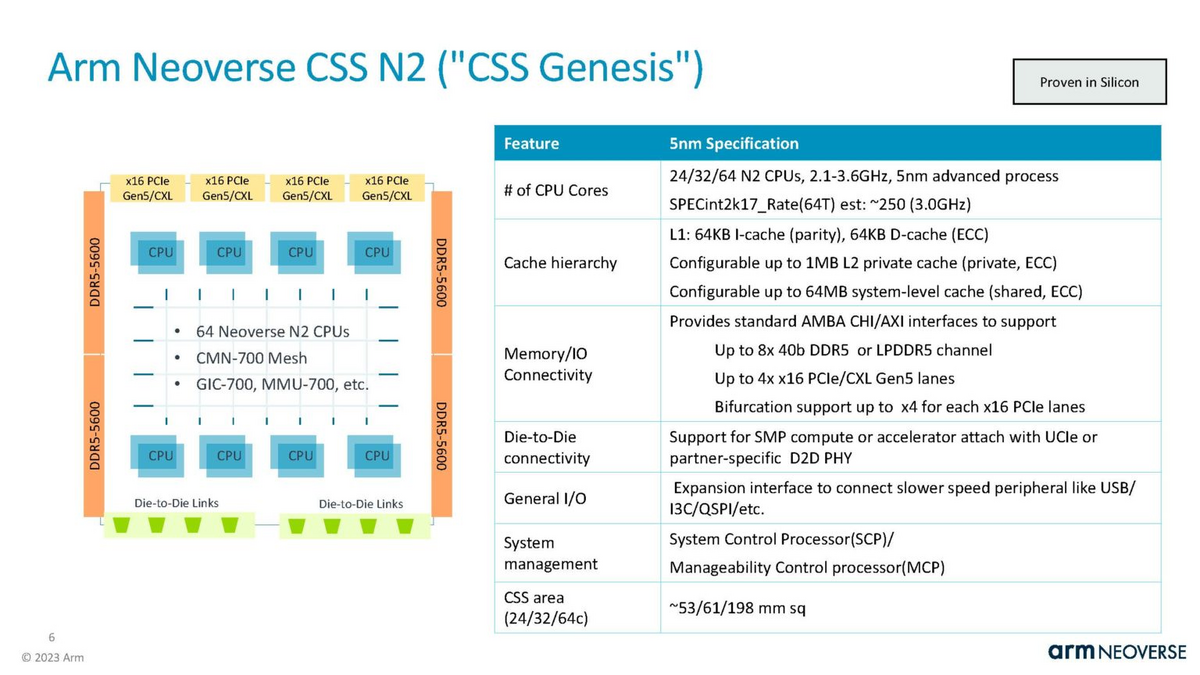
この中で、Die-to-Die connectivity のところに、
Support for SMP compute or accelerator attch with UCIe or partner-specific D2D PHY
とあります。この部分はArmではなく、Partner になるようですね。
下図も上記の記事から説明のために引用します。Socket は 2 die 構成で、Socket 間は CXL で接続しています。x16 の CXL を使えば、片側 32Gbps x 16 = 64GB/s です。

下図も上記の記事から説明のために引用します。Die 間の接続の図です。
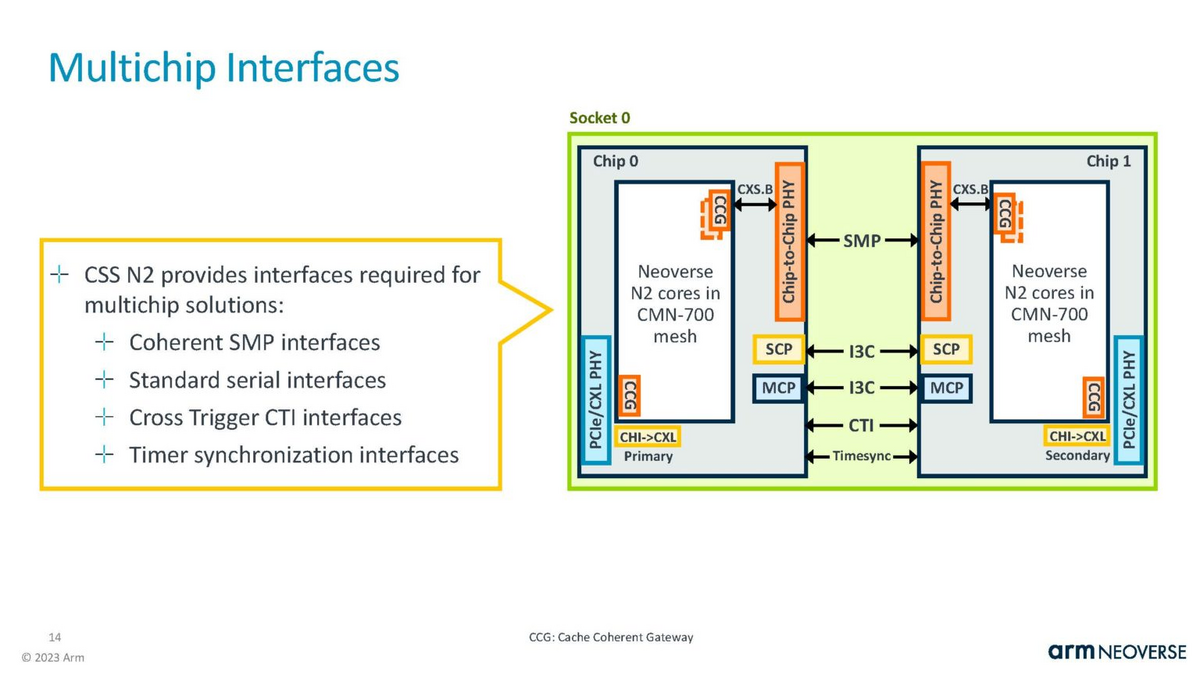
どこと一緒に開発した?
下記のXの投稿によると、Maia 100 の開発では、Global Unichip (GUC) が関わっているようです。
Microsoft worked with Taiwan contract chip designer Global Unichip on the Maia 100, media report, adding Global Unichip has order visibility through mid-2024, though it is expected to benefit from continued development over the life and subsequent generations of Maia. Alchip,…
— Dan Nystedt (@dnystedt) 2023年11月17日
となると、Cobalt 100 も GUC が関わっている可能性があるので、GUC の D2D を調べてみました。
GUC の D2D
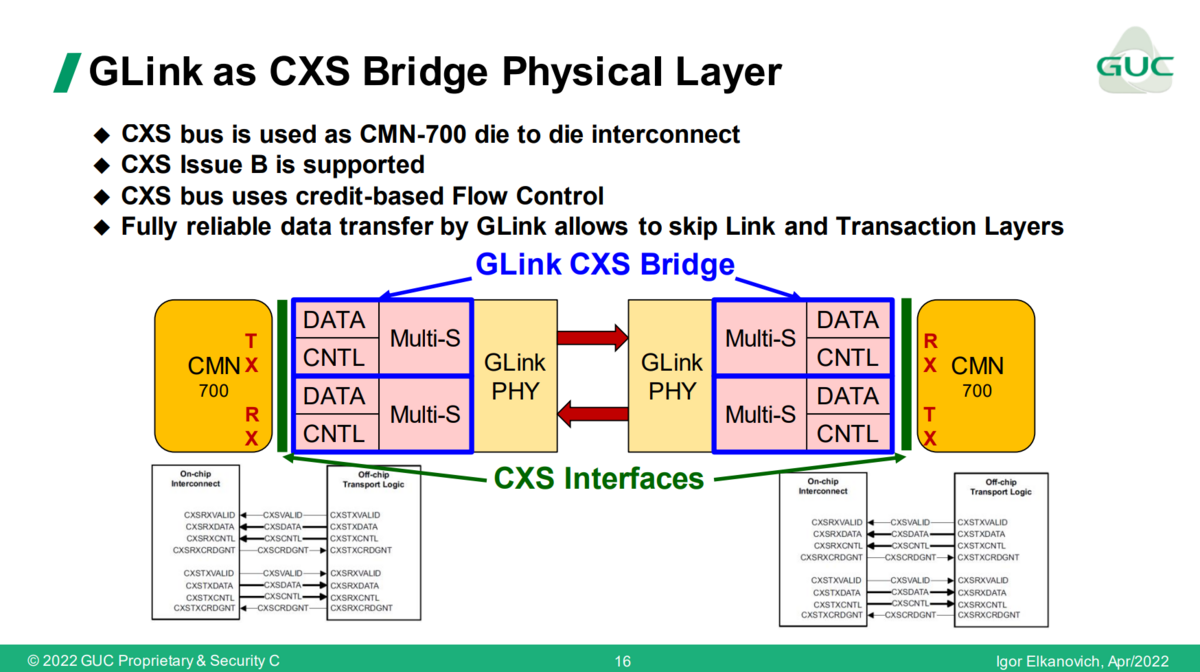
GUCのこのスライドからの引用です。Arm CCS N2 では、AMBA CXS経由でD2Dになっています。GUCのGLinkでは、GLink CXS Bridge なるようなものがあり、これを使って、AMBA-CXS <=> GLink CXS Bridge <=> GLink PHY <=> GLink PHY <=? GLink CXS Bridge <=> AMBA-CXS で接続できるようです。
下図では、CCG (CMN Gateway) <=> CXS <=> GLink 2.2LL での接続図のようです。これを使うと、CCG <=> CCG 間の Latency は 5ns のようです。

下図は、複数のCXSを使った事例です。この構成だと、チップ内のMeshの数と同じだけCXS経由で die 間を接続できるようですね。この時でも、Latency は 5nm のようです。
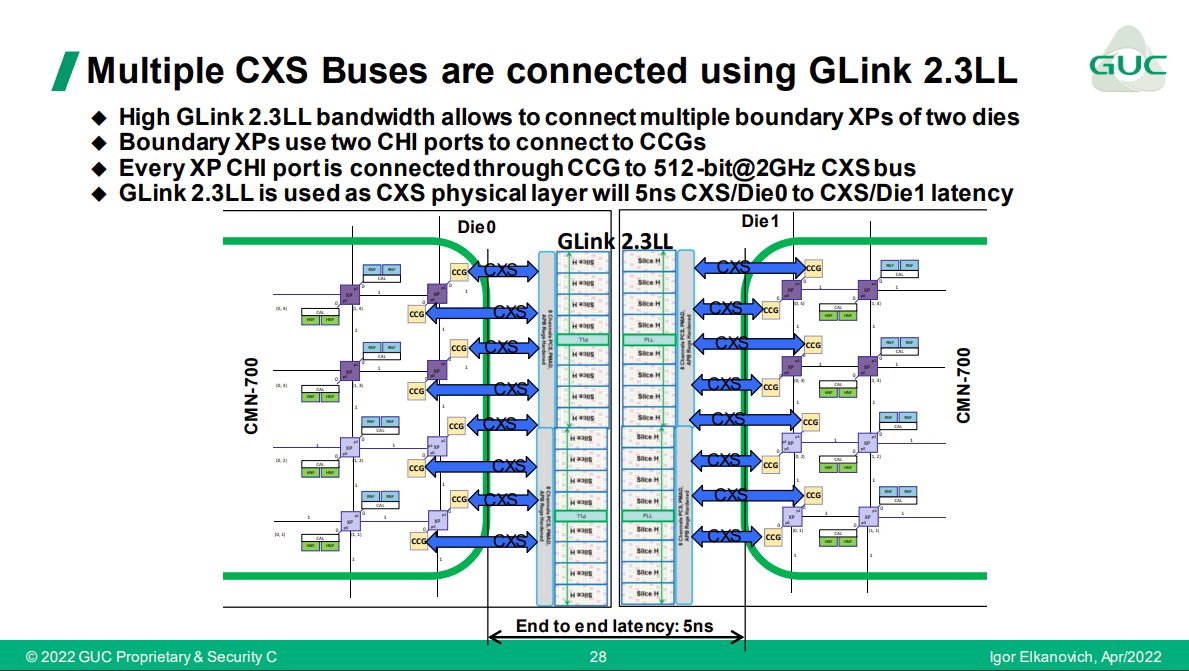
おわりに
Microsoft の Cobalt 100 をちょっと深堀しました。
もうちょっと、詳しい情報が公開されたら、確認したいと思います。
関連ブログ