はじめに
2021年4月の GTC 2021にて発表があったGrace。そのGraceとAmpere NextベースのDGXは、DGX A100の10倍になるという発表がありました。
NVIDIAによれば、1兆パラメータという非常に複雑で巨大なAIモデルを利用すると、学習にかかる時間は、x86 CPU(AMD 第2世代EPYC×2)とNVIDIA GPU(A100×8)の組み合わせとなる現行製品のDGX A100では約1カ月となるが、Grace(×8)+NVIDIA GPU(A100 ×8)の組み合わせの場合は、わずか3日間で終わるという。性能はざっと10倍に向上するという計算になる。
なぜ?
DGX A100との違いは、ホスト側がAMD EPYC Rome x 2 に対して、Grace x 8。。この時は、Grace + Ampere のモジュールの発表があったんですね。説明のために、上記の記事からそのモジュールを引用します。

DGX A100の場合は、下記のようにx86側との接続は PCIe です。説明のために引用します。4個のGPUに対して、Romeと PCIe 経由で接続されています。x86とGPU間は直接接続されているのではなく、PCIe Switch経由で接続されています。
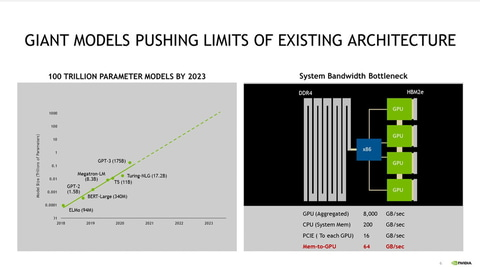
一方、Grace + GPU の場合は、下記のような構成になっています。説明のために引用します。GraceとGPU間は、NVLINKで500GB/s。。。あれ、500GB/s なので A100じゃない。。

ということは、
Grace (x8) + A100(x8) ではなく、Grace (x8) + H100(x8) ということなんだろうね。。。GTC 2021のビデオを見直したら、1:03:34のところで10倍と言っているのは、このスパコンが10倍ということ?
下記の記事では、
シニアディレクターParesh Kharya氏は述べた。同社によると、Graceベースのシステムは「NVIDIA DGX」ベースのシステムと比べて10倍高速だという。
とあるので、やっぱり、A100じゃないんだろうね。
おわりに
H100がA100に対して6倍速いので、x86 <=> A100 に対して、Grace <=> H100 が 1.7倍ぐらい速くなると。10倍になりそう。PCIe Gen4 x 16 x 4 = 64GB/s から 500GB/s x 4 = 2000GB/s なのでこちらはもの凄く速くなっている。500GB/sのために、18組のNVLINK v4の内、10組を使っているので残りの8組を使って、上下のH100と繋がる。つまり、H100間は4 x 50 = 200GB/s程度の転送レートになる。DGX H100では、各H100からは4つのNVLINK Switchと接続しているので、各NVLINK Switchとは4組の 4 x 50GB = 200GB/s。
Grace + H100の場合は、GPU間の転送レートは遅くなりが CPU <=> GPU 間の転送レートはめっちゃ速くなりので、いいという感じなのかな。。。
ポイントは、1T Parameter modelというGPU側のメモリには入りきらないモデルをホスト側のメモリにおいて使うというケースの時なんでしょうね。。そうじゃないときは、そんなに困らないと。。
とはいえ、Transformerベースのモデルだと巨大なパラメータを持ったモデルになっちゃんでしょうね。