はじめに
今回は、Intel、AMD、NVIDIAのデバイスを使うとき、どのようにプログラミングのかをみてみます。
Intel oneAPI
Intelは、oneAPI にて、CPU、GPU、FPGA、その他のアクセラレータをプログラムできるようにしています。
oneAPI は、ベース・ツールキットの上に、アドオンツールキットとして、
- oneAPI HPC ツールキット
- oneAPI IoT ツールキット
- oneAPI レンダリングツールキット
- AI アナリティクス・ツールキット
- OpenVINO ツールキット
などがあります。
ベースとなるものは、データ並列C++(DPC++) です。DPC++は、ISO C++ + Khronos SYCL です。
Khronos SYCL は、OpenCL を C++ にした感じです。1つのプログラムの中でCPUとアクセラレータ(GPU、FPGAなど)のプログラムを含めて書けるようにしています。
DPC++の書籍、Data Parallel C++ の PDF/EPUB 版は、Springer から無償でダウンロードできます。
DPC++コンパイラは、無償で利用できます。従来、Intelha Paralell Studio XE などのツールキットを有償で提供してきました。金額も1年間で10万円以上もします(ものによっては、数十万円にもなります)。ベースツールキットだけでなく、上記のアドオンツールキットも無償です。サポートが必要な時は、有償で受けることができます。
各ツールの詳細は、XLSOFTの下記のサイトを覗いてみてください。
では、SYCLのコードをみてみましょう。
下記のコードは、Intelの「Compiling SYCL* for Different GPUs」から説明のために引用しています。
C++のコードです。
#include <iostream>
#include <CL/sycl.hpp>
using namespace sycl;
class vector_addition;main(int, char**) {
float4 vec_a = { 2.0, 3.0, 7.0, 4.0 };
float4 vec_b = { 4.0, 6.0, 1.0, 3.0 };
float4 vec_c = { 0.0, 0.0, 0.0, 0.0 };
default_selector device_selector;
queue queue(device_selector);
std::cout << "Running on " << queue.get_device().get_info<info::device::name>() << "\n";
buffer<float4, 1> vec_a_sycl(&vec_a, range<1>(1));
buffer<float4, 1> vec_b_sycl(&vec_b, range<1>(1));
buffer<float4, 1> vec_c_sycl(&vec_c, range<1>(1));
queue.submit([&] (cl::sycl::handler& cgh) {
auto vec_a_acc = vec_a_sycl.get_access<access::mode::read>(cgh);
auto vec_b_acc = vec_b_sycl.get_access<access::mode::read>(cgh);
auto vec_c_acc = vec_c_sycl.get_access<access::mode::discard_write>(cgh);
cgh.single_task<class vector_addition>([=] () {
vec_c_acc[0] = vec_a_acc[0] + vec_b_acc[0];
});
});
}
std::cout << " Vec_A { " << vec_a.x() << ", " << vec_a.y() << ", " << vec_a.z() << ", " << vec_a.w() << " }\n"
<< "+ Vec_B { " << vec_b.x() << ", " << vec_b.y() << ", " << vec_b.z() << ", " << vec_b.w() << " }\n"
<< "----------------------\n"
<< "= Vec_C { " << vec_c.x() << ", " << vec_c.y() << ", " << vec_c.z() << ", " << vec_c.w() << " }"
<< std::endl;
return 0;
}
CL/sycl.hpp にある 以下のAPI を使っています。
- default_selector device_selector
- queue queue(device_selector)
- queue.get_device().get_info<info::device::name>()
- queue.submit([&] (cl::sycl::handler& cgh)
- vec_a_sycl.get_access<access::mode::read>(cgh)
- vec_c_sycl.get_access<access::mode::discard_write>(cgh)
- cgh.single_task
下記のbufferの部分は、ホスト側(CPU)のメモリとGPU側のメモリの対応を示しています。ホスト側のメモリ vec_a は、GPU側ではvec_a_syncになる感じです。
buffer<float4, 1> vec_a_sycl(&vec_a, range<1>(1)); buffer<float4, 1> vec_b_sycl(&vec_b, range<1>(1)); buffer<float4, 1> vec_c_sycl(&vec_c, range<1>(1));
queue.submit の {} n中のコードがGPUで実行されるコードです。auto の3行は、GPUで実行するときにホスト側(CPU側)のメモリとGPU側のメモリの関係を示しています。vec_a_acc と vec_b_acc は、GPUから見ると、リードデータで、vec_a_acc はGPUから見ると、ライトデータです。最初にGPU側では、ホスト側のデータのvec_aをvec_a_sync、vec_bをvec_b_syncにコピーし、最後に、vec_c_sync を vec_c にコピーします。
cgh.single_task の部分で、vec_a_acc[0] と vec_b_acc[0] の 加算結果を vec_c_acc[0] に書き込んでいます。
auto vec_a_acc = vec_a_sycl.get_access<access::mode::read>(cgh);
auto vec_b_acc = vec_b_sycl.get_access<access::mode::read>(cgh);
auto vec_c_acc = vec_c_sycl.get_access<access::mode::discard_write>(cgh);
cgh.single_task<class vector_addition>([=] () {
vec_c_acc[0] = vec_a_acc[0] + vec_b_acc[0];
});
SYCLでもOpenCLやCUDA(NVIDIAのプログラミング言語)と同じようにメモリに関しては、ホスト側とGPU側をちゃんと区別しないといけないです。
AMD ROCm
AMD は、ROCm がプログラミング環境です。
下図の上記のサイトから説明のために引用しています。
下図での注目すべき点は、下から2つ目の Programming Models です。以下の3つのProgramming Modelをサポートしています。
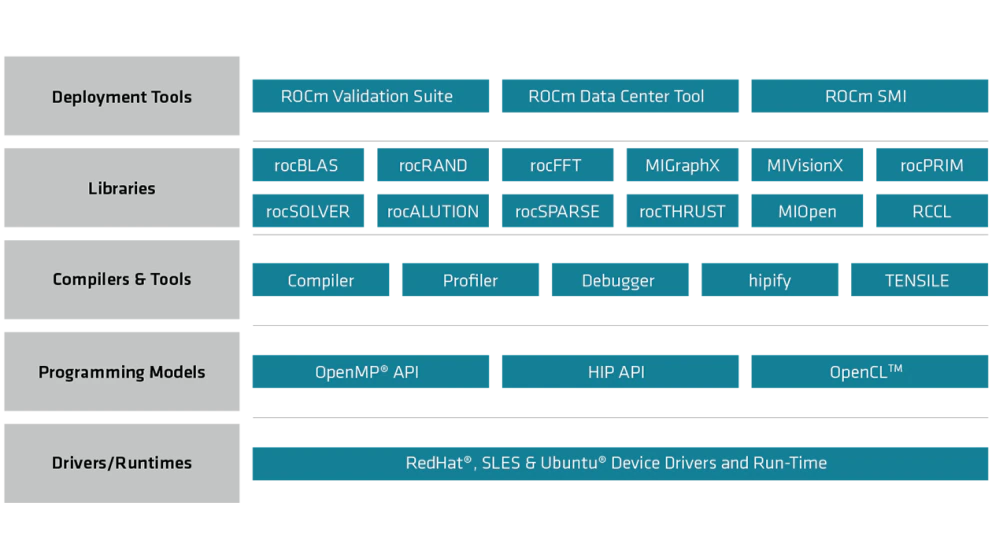
OpenMPは、基本的にはマルチコアのプログラムの時に使われてきましたが、アクセラレート(だいたいはGPU)に対するサポートも行われるようになり、#pragma を使って、CPUとGPUのコードをひとつのコードで記述できます。
HIP は、AMDのGPUだけでなく、NVIDIAのGPUのプログラミングできます。ただし、NVIDIAのGPUプログラムであるCUDAのコードをHIPの環境に移行するには、HIPIFYというものを使うことにはなります。
OpenCLは、Intelのところで説明したOpenCLです。NVIDIAのCUDAに対応するのが、AMDではOpenCLになります。
OpenMP => HIP => OpenCL の順により、GPU側を意識したプログラミングが必要になります。
NVIDIA CUDA
NVIDIAのGPUは、CUDAというC/C++っぽい言語を使ってプログラミングします。あたしがCUDAを最初に触ったのが確か、2009年ぐらいだと思います。NVIDIAのGPUが載っているMacbookにて、CUDAプログラムをしたんです。その頃のNVIDIAのGPUでは、CUDAだけでなく、OpenCLもサポートしていて、CUDAとOpenCLの両方のコードを書いて、どちらの方が速いかなどしていました。今思えば、幸せな時代でした。その後、PC + Linux で Geforce 200シリーズ (GTX 200) シリーズから GTX 600 ぐらいまでのGPUを使って、CUDAでいろいろプログラミングしました。
AMDで説明しましたOpenMPでは、アクセラレータであるGPUへのコードも#pragmaベースで書けるようになりましたが、当時はまだOpenMPでは書けなかったです。その代わりに、OpenACCなるもので #pragma を使って書いていました。
このブログでの、OpenACCに関することは非常に多く書いた記憶があります。
OpenACCについては、PGIとCAPS Enterpriseがいろいろとやっていましたが、CAPS Enterpriseは破綻。PGIはNVIDIAに買収されました。
おわりに
現時点では、
- oneAPI
- OpenMP
- HIP
- CUDA
でプログラミングすることになりますが、oneAPI (DPC++) では、AMD GPUやNVIDIA GPU も hipSYCL にてサポートできるといっています。