はじめに
来年に NVIDIA B100 が発表およびリリースされるようなので、NVIDIA B100 について妄想したいと思います。
CB100については、9月30日にブログに書いています。
この時分かったことは、
- SM の数が 180 (GH100は、144)
- HBM のビット数が 8192ビット
ということでした。
TSMC CoWoS-S
TSMC CoWoS-S のスケジュールのスライドは、下記のようになっています。ここから図を説明のために引用します。
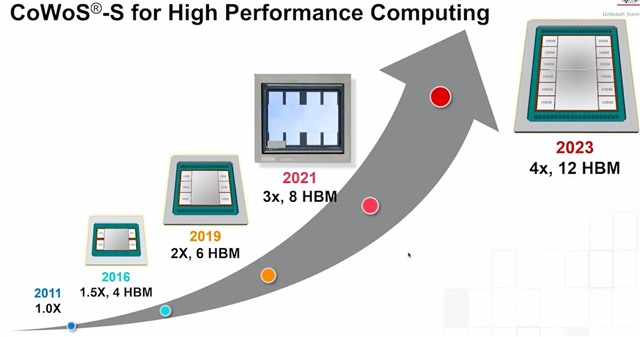
- x2 6 HBM (2019) : A100/H100
- x3 8 HBM (2021) : Intel Habana Gaudi3
- x4 12 HBM (2023)
という感じです。
HBMを8個搭載するとなると、x3 になりそうです。
GH100 の die shotから CB100を妄想する
下図は、「Nvidia's AD102 officially revealed, how close were the previous estimates?」から説明のために引用します。なお、AD102とGH100の両方が載っていますが、GH100側だけを切り出しています。
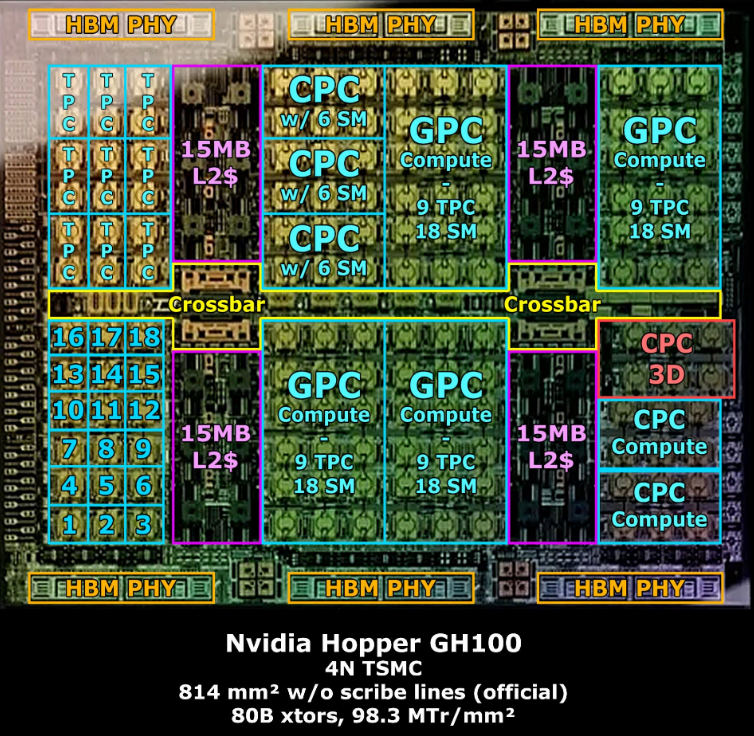
GH100のSMは144で、CB100は160ということで、2 die にしたと考えると、真ん中から分けて、NVLINK-C2C で接続すればいいのでは?と思っています。
で、SM が 144 から 160 にしても、1.11倍しか性能があがりません。HBMは 6個から8個になり、1.33倍です。となると、1.33/1.11=1.198倍、動作周波数をあげられそうです。H100のPCIe版はBoost で 1.755GHzで動くので、1.198倍だと 2.1GHz ぐらいになりそうです。SMX5版ではもうちょっと速いと思いますが。
die を 2つに分けたことで、1つのSMに割り当てられる面積を増やせるので、Tensor Coreの数を増やすか、構造を変えて、2倍にすることができれば、
GB100は、GH100 に対して、1.11 x 1.198 x 2 = 2.65 倍ぐらいの性能にはなりそうです。
おわりに
NVIDIAは、
- P100 (NVLink) => V100 (Tensor Core) => A100 (Transformer Engine) => H100 (NVLINK-C2C)
とそれぞれ、新しい技術を入れてきています。上記のB100だと、パッケージに 2 die ということになりますが、もうちょってと何かを仕込んでいるのでは?と思っています。
それは、下記のXの投稿にもあるように、「GPU Domain Specialization via Composable On-Package Architecture」に出てくる、2.5D ではなく、3D による、L3 Cache の導入があるのでは?と思います。
GPU Domain Specialization via Composable On-Package Architecturehttps://t.co/tAdYQjPS5Q
— Vengineer@ (@Vengineer) 2023年12月21日
の
3D と 2.5D で、あたし的には 2.5D だと思ったけど、
CB100は 8 x HBM となると、3D で CB100 としては、L2 を増強した 80 SMs な die x 2 + HBM x 8 の構成かな? pic.twitter.com/vhwbFARfpY
L3 Cache との接続は、下図を見る(左から2番目)と、L2 Cacheの部分っぽいですね。AMDのCCDのV-CacheやMI300のXCD/IODの接続と似た感じ。
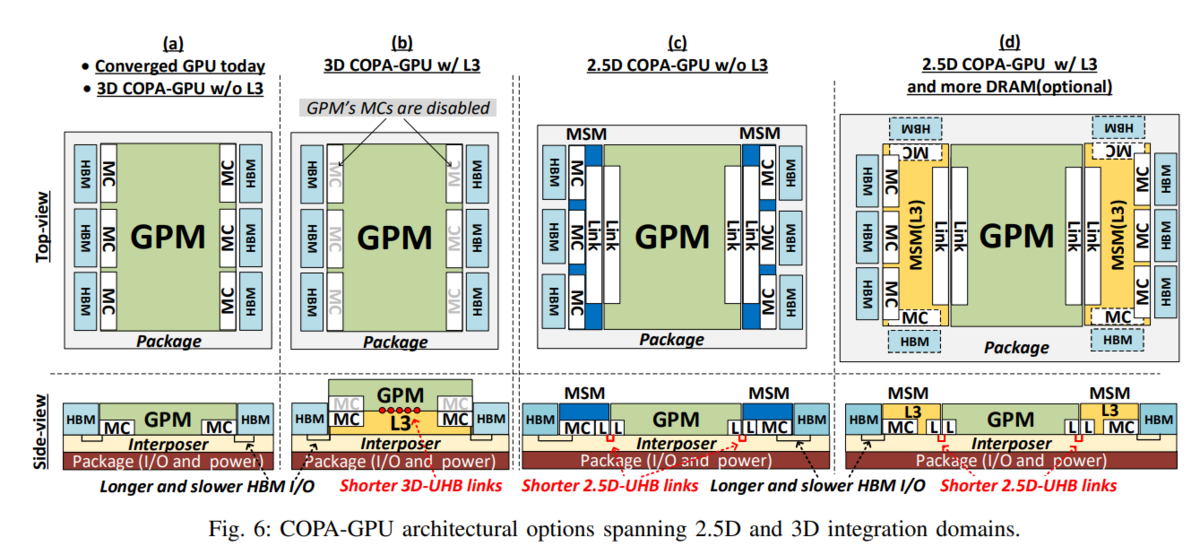
どうなるのでしょうかね。。。
追記)、2023.12.29
を考えて、192 SMs でも OK そう
NVIDIA
— Vengineer@ (@Vengineer) 2023年12月29日
GA100 (128 SMs), A100 (108 SMs) : 8 TPCs/GPC
GH100 (144 SMs), H100 (132 SMs) : 9 TPCs/GPC
GB100
- (160 SMs) : 10 TPCs/GPU
- (176 SMs) : 11 TPCs/GPU
- (192 SMs) : 12 TPCs/GPU
2 die を考えると、144*4/3 = 192 で、1 die (96 + HBM3e x 4) と考えるのがいいかな?
die (96 SMs) , 8 x MC (512bit)
— Vengineer@ (@Vengineer) 2023年12月29日
L2 Cache 768 x 8 x 8) = 48MB
A100 ベースで考えると、96 SMs + 48MB はOKっぽいhttps://t.co/dHK3Ets4ae pic.twitter.com/JCPuyucO2K