いろいろ記事が出ているけど、
まずは、現場からのレポート。Microsoft Reseach Blog
Microsoft unveils Project Brainwave for real-time AI
プロジェクトリーダーのDoug Burger, Distinguished Engineer, Microsoftさんから。
まずは、現場からのレポート。Microsoft Reseach Blog
Microsoft unveils Project Brainwave for real-time AI
プロジェクトリーダーのDoug Burger, Distinguished Engineer, Microsoftさんから。
それからNextPlatformの記事:
First In-Depth View of Wave Computing’s DPU Architecture, Systems
Drilling Into Microsoft’s BrainWave Soft Deep Learning Chip
First In-Depth View of Wave Computing’s DPU Architecture, Systems
Drilling Into Microsoft’s BrainWave Soft Deep Learning Chip
この3つを読めばいいんじゃないかな。
SlideShareにもアップされていた。
NextPlatformの記事はどれ読んでも内容がしっかりしているからね。
その他の記事はだいたいプレスや発表の内容のコピーだから。。。
その他の記事はだいたいプレスや発表の内容のコピーだから。。。
NextPlatformの2番目の記事。特にこの図(引用です)
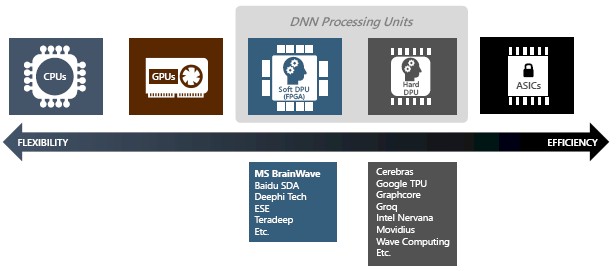
この中でまだ詳細が分かっていないのは、Groqかな。XilinxからCOOを迎えたようだが、いつ頃発表するのかな。
本題に戻ります。
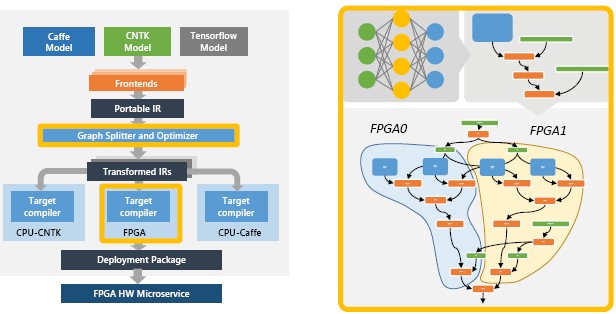
の図(引用)、左側に、Caffe Model, CNTK Model, TensorFlow ModelからFrontends経由で、Portable IRにする。
その後に、グラフを分割し、最適化して、各テクノロジに対応したフローになる。
その後に、グラフを分割し、最適化して、各テクノロジに対応したフローになる。
Graph Splitterで大きなグラフを複数に分割して、複数のCPUやFPGAにマッピングするのかな。。。
右側にFPGA0とFPGA1になっているので、分割されるんでしょうね。
ということは、TensorFlow XLA や NNVM-TVM よりも進んでいるわ。。。
右側にFPGA0とFPGA1になっているので、分割されるんでしょうね。
ということは、TensorFlow XLA や NNVM-TVM よりも進んでいるわ。。。
Stratix 10だけでなく、Stratix VやArria 10でも動くのね。
推論用なので、バッチサイズは、1 のようです。