@Vengineerの戯言 : Twitter
SystemVerilogの世界へようこそ、すべては、SystemC v0.9公開から始まった
はじめに
この記事では、MITの Vivienne Sze さんの講演ビデオを観て、そこから得られたものをまとめたものです。
Vivienne Sze さんの研究室は、こちら。ENERGY-EFFICIENT MULTIMEDIA SYSTEMS GROUP
www.rle.mit.edu
Vivienne Sze さんの経歴は、
学士の時に、IC Design Engineerとして働き、博士後にTIで3年近く半導体エンジニアとして働いていたようです。その時にビデオコーデックとかをやっていたので、現在の研究室のタイトルに MULTIMEDIA が入っているのかもしれません。その後、過去の発表資料を眺めたら、最初が動画関連が多かったので、最初からMULTIMEDIAの研究をやっていて、今はDeep Learningを道具として使っているって感じなんだと思いました。
このビデオ「Energy-Efficient AI」を観れば、現在どんな研究をやっているかが分かるようだ。
- Energy-Efficient AI with Cross-Layer Design (Algorithms)
- Specialized Compute Hardware (Compute Architectures & Circuits : Eyeriss
- Robot Localization Under a tenth of a Watt (コラボ with Sertac Karaman), Navion chip
- Low Energy Robotics (Lighter than Air Vehicles), Miniature Satellites, Origami Robots
- Neuropsychological Testing (コラボ with Thomas Heldt), eye movement
EEMS Groupに出てくるYoutubeのビデオ
講演ビデオにも出てきますが、現在の研究対象は
- Energy-Efficient Deep Learning, Computer Vision, and Autonomous Navigation
- Mobile Health Monitoring
- Accelerating Super Resolution
- Next-Generation Video Coding
です。
Energy-Efficient Deep Learning に関係するビデオ
この記事では、Energy-Efficient Deep Learning に関するものを追っていきます。
Energy-Efficient Deep Learningに関しては、Efficient Processing of Deep Neural Networksという書籍が出ていて、このブログでも紹介しました。
vengineer.hatenablog.com
Youtubeのサイトは、
www.youtube.com
この他に、Youtubeで「Vivienne Sze」で検索すると、20以上の講演ビデオが出てきます。
Vivienne Sze さんの研究成果で特に有名なのは、Eyeriss Projects ですね。推論用アクセラレータです。
最初の論文が2016年3月なので、あたしが TensorFlow XLAに興味を持つ1年も前に出ています。
Eyeriss は名前は知っていましたが、詳しく調べることは今までありませんでした。この機会の一番最初の論文から読み返すことにしました。
最初の論文は、ISCA 2016。「Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks」
この時の著者は、Yu-Hsin Chen、Joel Emer、Vivienne Szeの3人。
Yu-Hsin Chen さんは MITで博士を取ってから、NVIDIA => Facebook です。
Joel Emer さんは、2005年からMITと関わっていますね。Compaq => Intel => NVIDIA です。なんと、Intelの時は、このブログでも紹介したLEAP FPGAにかかわっていたようです。Bluespec:MIT & Intelの事例(LEAP)
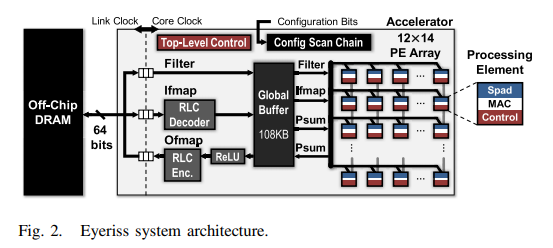
65nmで実際のInference用チップとして開発して Eyeriss 。12*14個のPE + 108KBのSRAM(バッファ) + DRAM I/F。
各PEは200MHzで動作し、0.5KBのレジスタファイルを持っている。
各PEの中に、input feature/weight/output feature のどれを保持すれば、電力効率が良くて、Latencyが短いのかをベンチマークして、Row Stationary (RS) が一番いいと。
この RS が一番いいというのは、最初に観た何本かのビデオに出てくるんです。どうして、RSが一番いいのかと。。。Eyeriss の論文とスライドを観てやっとわかりました。
ISCA 2016のスライド。に、その RS が一番いいという説明が丁寧に載っています。
Eyeriss (この論文)では、DRAMから・へのデータ移動時には圧縮・伸長を行っています。Run Lengthなのでリアルタイムに処理ができるし、回路規模もそんなにないです。これにより、DRAMへのアクセスを減らせることができます。
EyerissはCNN/FCの電力効率とLatencyをよくするためのものであったが、その後のMobile Device用のモデル(MobileNetなど)ではCNNのサイズが変わったため、Eyeriss の特徴を生かししきれなくなり、
Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices を発表。
著者は、Eyerissの3名 + 1名 Tien-Ju Yang さん です。(Yu-Hsin Chen さん の後輩っぽい)
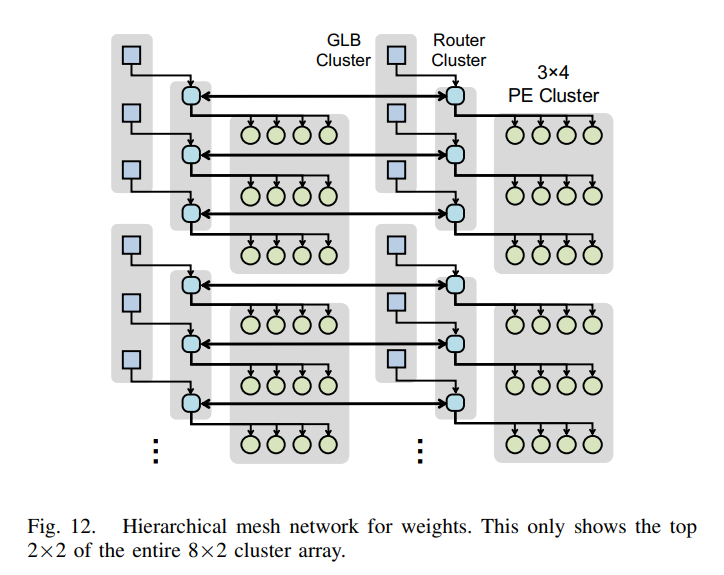
下図が Eyeriss と Eyeriss v2 の違いです。GLB(Global Buffer)が1つからGLB cluster として分散。2D Mesh Network にて、(GLB cluster + PE cluster + Router cluster) との接続を変えられるのが大きな違いです。また、各PEは SIMD (x2) になっています。
PE を cluster にして、4x3 の PE clusterに分散することで、MobileNetのようなモデルでも電力効率とLatencyをよくなるようです。
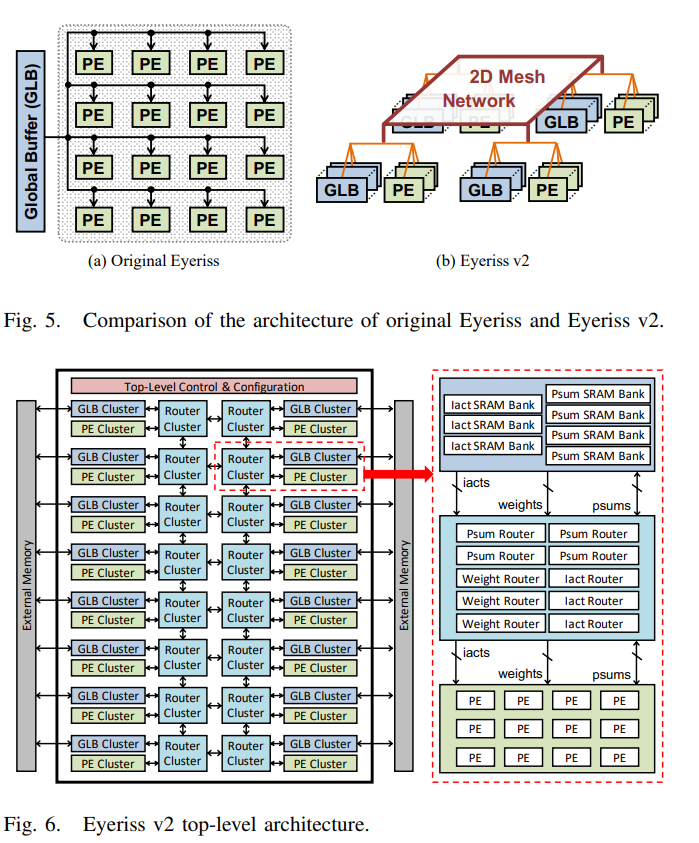
2D Mesh Networkにて、PE cluster 間のデータ移動がスムーズになっています。
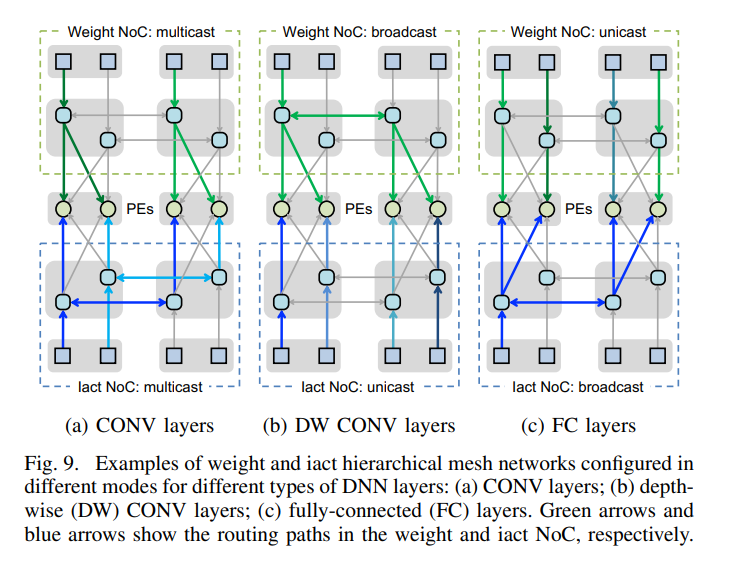
下図では、CONV、FC、だけでなく、DW CONV の対応できるようになっているのが分かります。
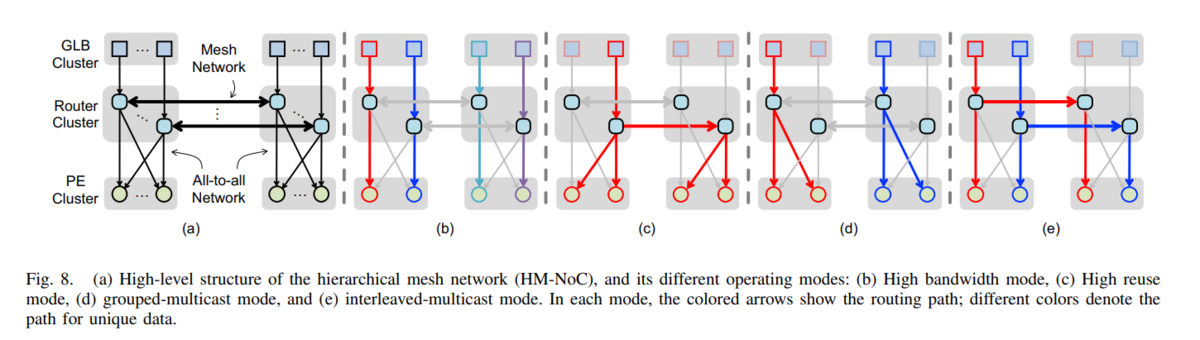
GLB cluster からRouter cluster 経由で PE cluster へのデータ移動の図がこちら
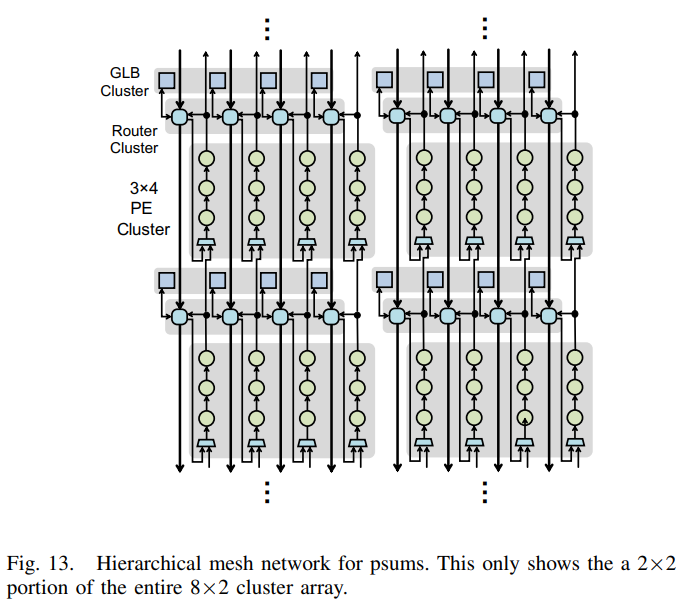
psums の PE cluster 間の接続図がこちら
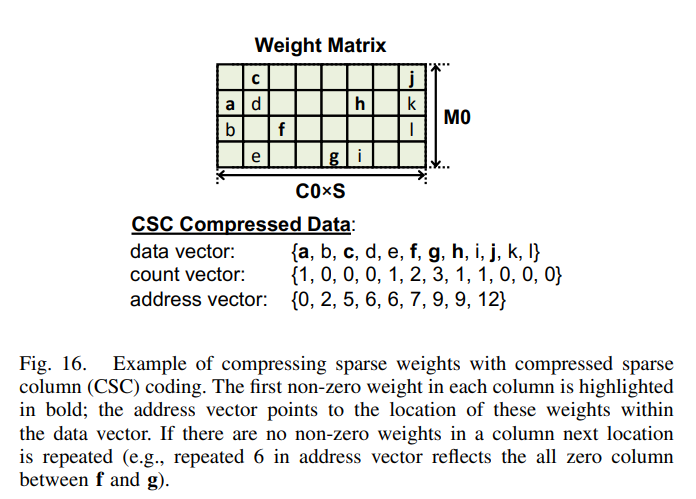
Eyerissの時はDRAMからGLBへの圧縮・伸長をしていますが、Eyeriss v2 では 各PEへの Weight も圧縮・伸長しています。つまり、Sparse 対応
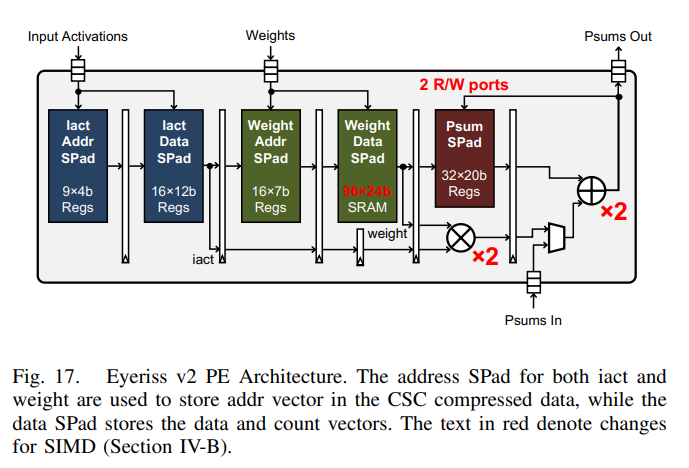
入力データに関しては、PEの中で伸長するようになっています。PEはSIMD (x2)なので、赤字 (x2) があります。
まとめとしての比較 (Eyeriss v1が最初のASIC、v1.5 は NoC を 2D Mesh Network にしたもので PE は v1 と同じ、v2 が PEを SIMD & Weight Sparse対応)
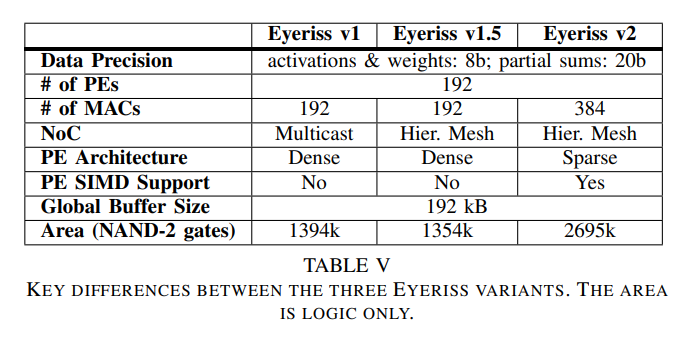
他のチップとの比較 (PEをSIMD x2にしたのがだ、演算精度が16bitから8bitになっているのを発見)
どのチップも200MHzで動作する。Eyeriss v1 に対して、Eyeriss v2 は、ALEXNETで10倍の性能で6倍の電力性能を達成。おまけに、MobileNetも対応している。
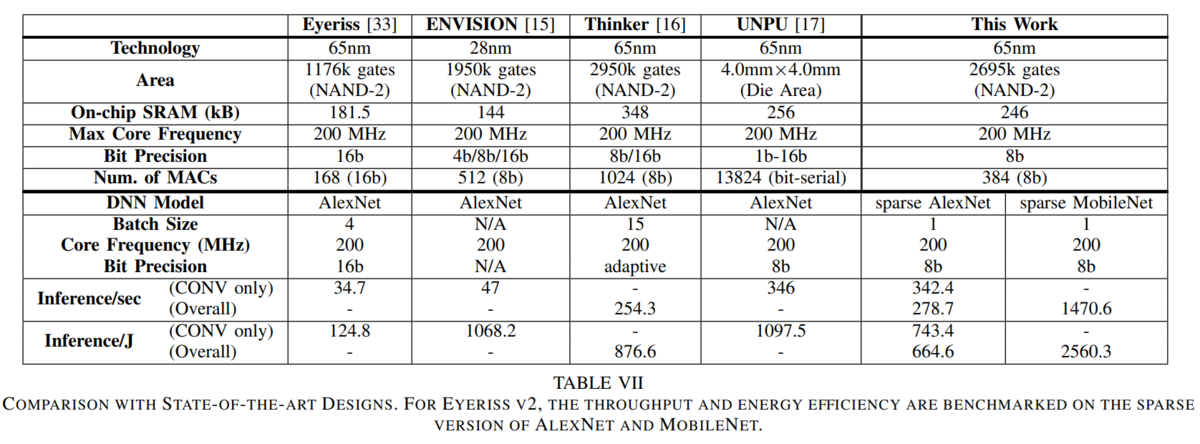
何故、16bit から 8bit になったのは、2016年から2018年の間に、Inference に関しては 8bit の精度があれば OK になったからであろうか?
ここまでで、Inferenceに関しては、RS、8bit、データおよびWeightは圧縮(伸長)、SIMD (x2)、2D Mesh Network で Mobile用ネットワークにも対応できるようになった。
2020年は、Timeloop & Accelergyについての2本のビデオ
- ISCA 2020 の Timeloop/Accelegry Tutorial (Part-1)
- ISCA 2020 の Timeloop/Accelergy Tutorial (Hands-on Sessiion) (Accelergy Exercises)
スライドは、こちら。
Timeloop の github は、こちら (NVLabs内にあるので、基本的にはNVIDIA)
Accelergy は、こちらは、MITで、基本的には、Eyeriss の DRAM <=> GLB <=> PE という構成で ハードウェアを決めていく感じですね。
左側のMAPPER部分が Timeloop 、右側のMODEL部分が Accelegry という感じ。
MAPPERである Timeloop で問題(Problem)とArchitecture、Constraintsにて、Mapspace を構築し、Mapspace に対して、Mapper parameters を入れて、Mapping したものを
Accelergy にて micro Architecture を Energy, Performace, Area を評価尺度にてて探索する感じ。
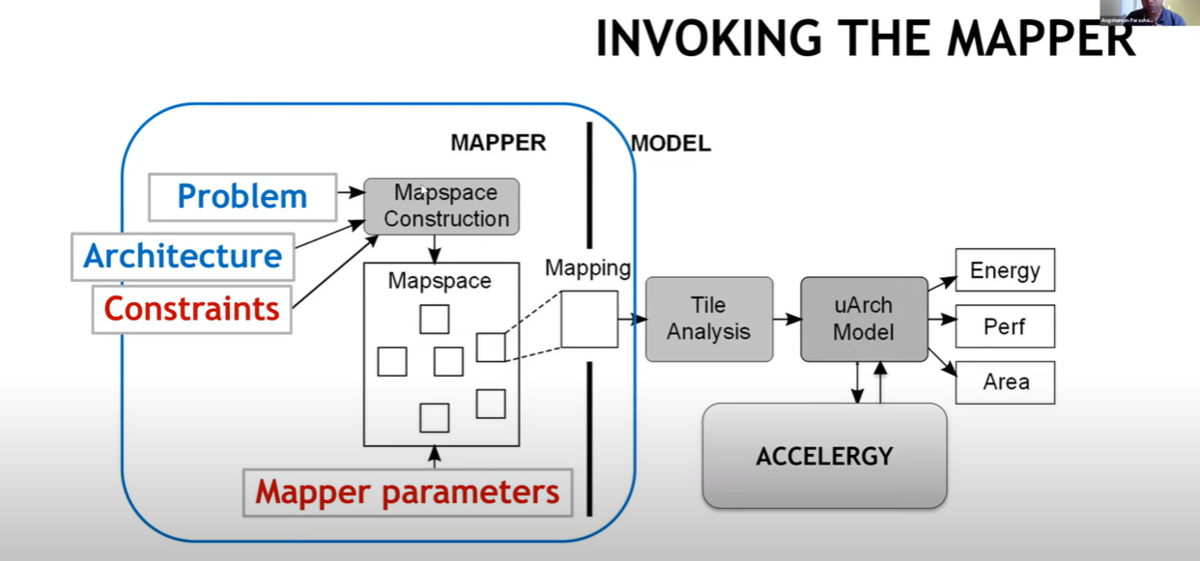
これって、1月2日にアップした「ハードウェアを意識したNASからハードウェアの構成も一緒に決めるNASに!」に書いたHASの部分なのかな?MAPPER の Problem が Network Model で Architecture と Constrains を合わせると、NAS なんでしょうね。