@Vengineerの戯言 : Twitter
SystemVerilogの世界へようこそ、すべては、SystemC v0.9公開から始まった
- TensorFlow
- PyTorch
の2大勢力になり、次はどこで盛り上がるのかな?と。
NAS : Network Architecture Search
なのかな?と思ってはいたのですが、モデルの膨大の探索空間に対して、Cloud環境にてTrainingをするという環境は富豪以外には無理。
そんなこと、おしごとでやるのは不可能なので、放置プレイしていましたが、
エッジ側のハードウェアを意識した NAS というのがあるのを知り、なんかいいじゃんと思い始めました。
ということで。Google君の AutoML が作り出した NASNetから、MnasNet、FBnet、Efficent-EdgeTPU、最後にまだ公式には発表されていない NAHAS をざっくり眺めてみました。
NASNet
NASNet「Learning Transferable Architectures for Scalable Image Recognition」 から
Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le
NASNetについては、日本語の解説がここにありました。
shiropen.com
NASの概要はこんな感じ。
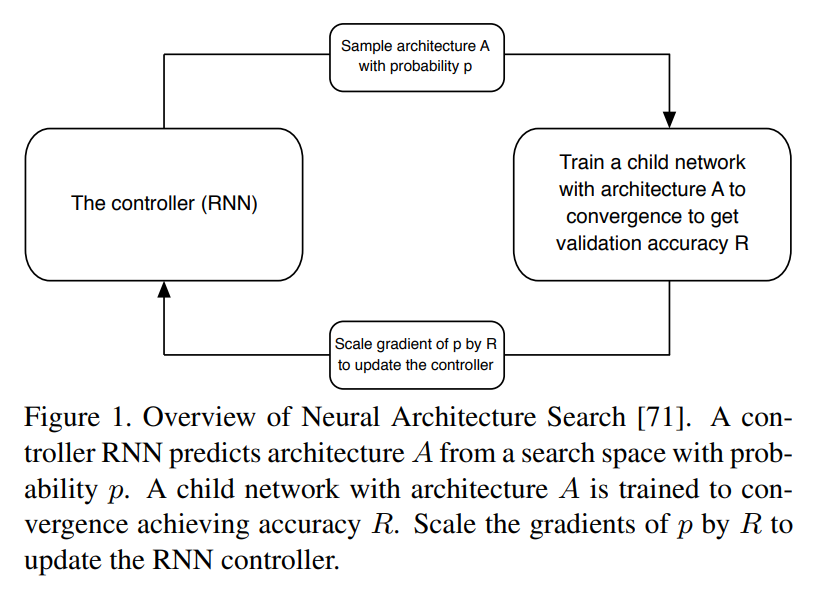
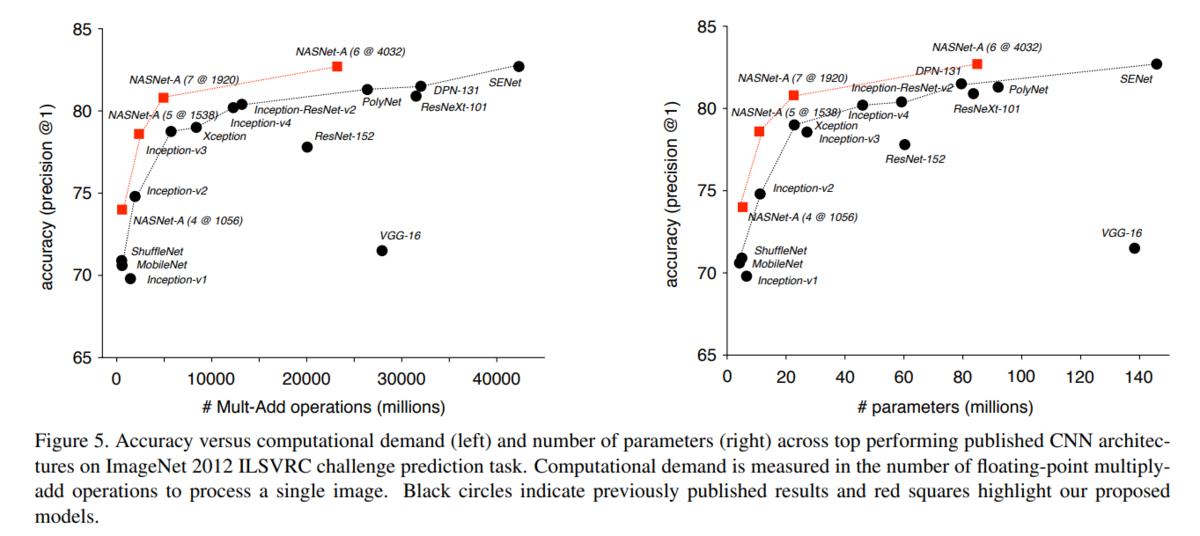
NASNetの精度のMulti-Add operations (millions)
MnasNet
MnasNet「MnasNet: Platform-Aware Neural Architecture Search for Mobile」、31 Jul 2018
Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, Quoc V. Le
日本語の説明がここにありました。
webbigdata.jp
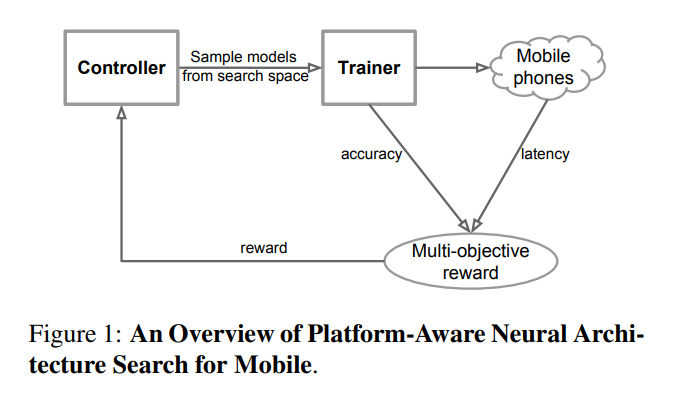
一般的なNASに対して、Mobile phone の実行Latencyを評価尺度に追加。
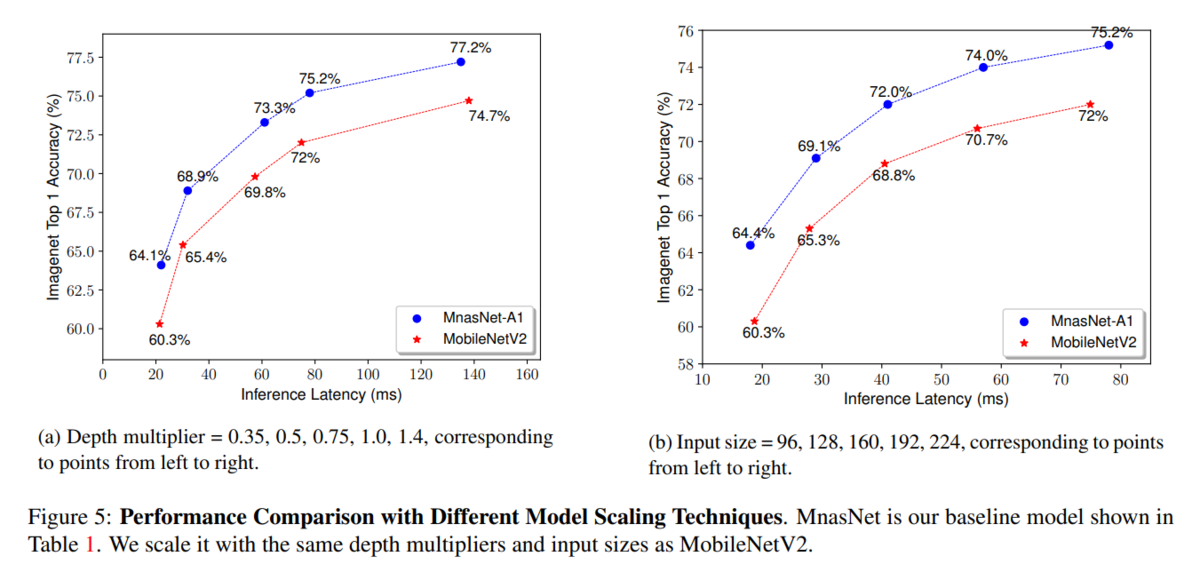
Mobile Phone用のMobileNetV2に対する、MnasNetの精度とLatency比較。Latencyの大小はネットワークの段数に関係する?同じLatencyに対しては、MobileNetV2に対してMnasNetはざっくり3%以上向上。
FBnet
Mobile Phone用というのなら、Facebookでも同じことをやるでしょうということで、出てきたのが
FBnet「FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search」、9 Dec 2018
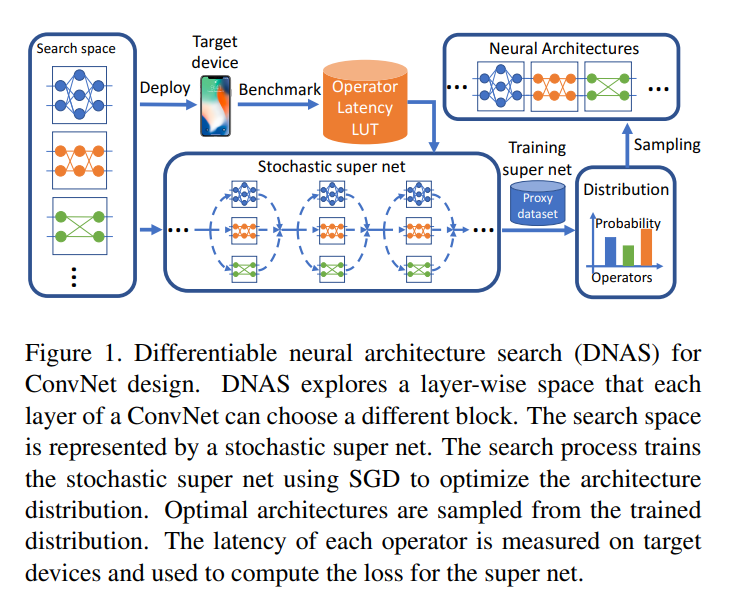
Googleの図とは違うのでちょっとわかりにくいと思っていたら、後に出てきたのがこの図
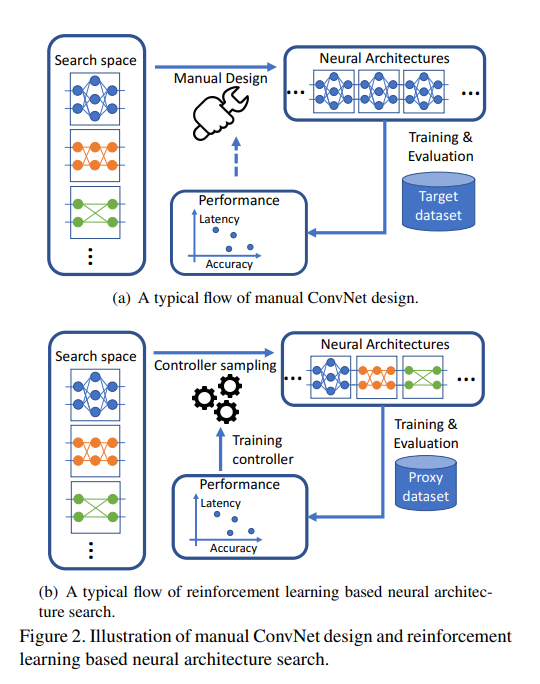
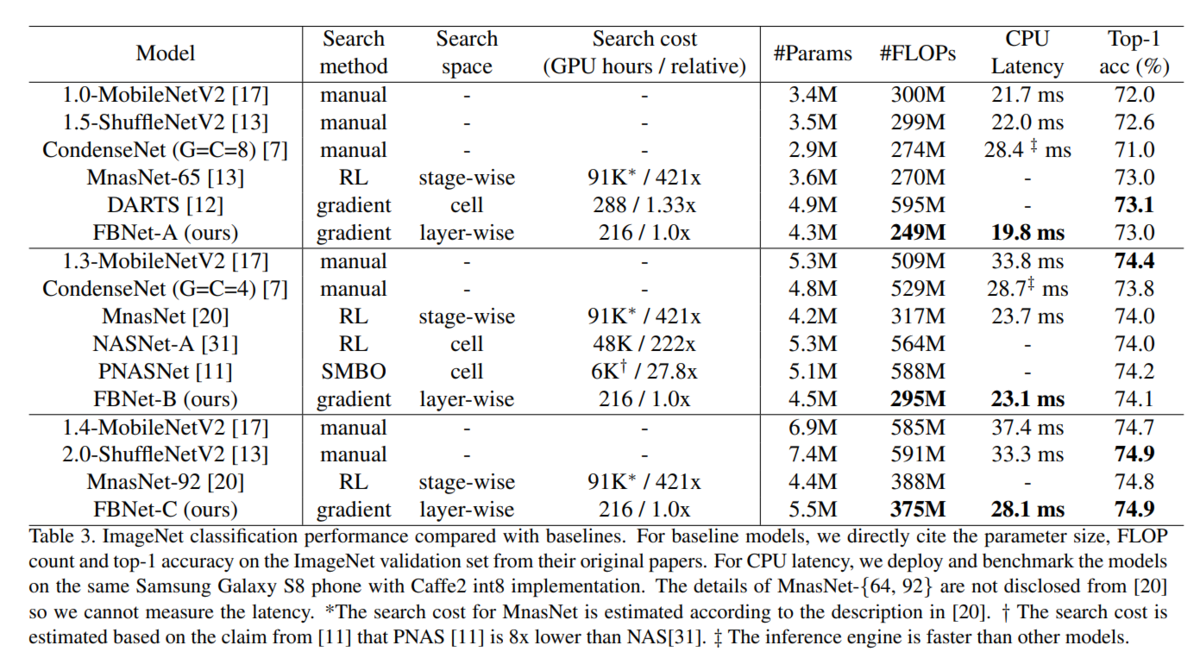
ここでも MnasNet と同じように 精度とLatency の図になっています。MnasNet との比較がグラフではなく表なのでぱっと見わかりにくいですが、精度は向上しています。
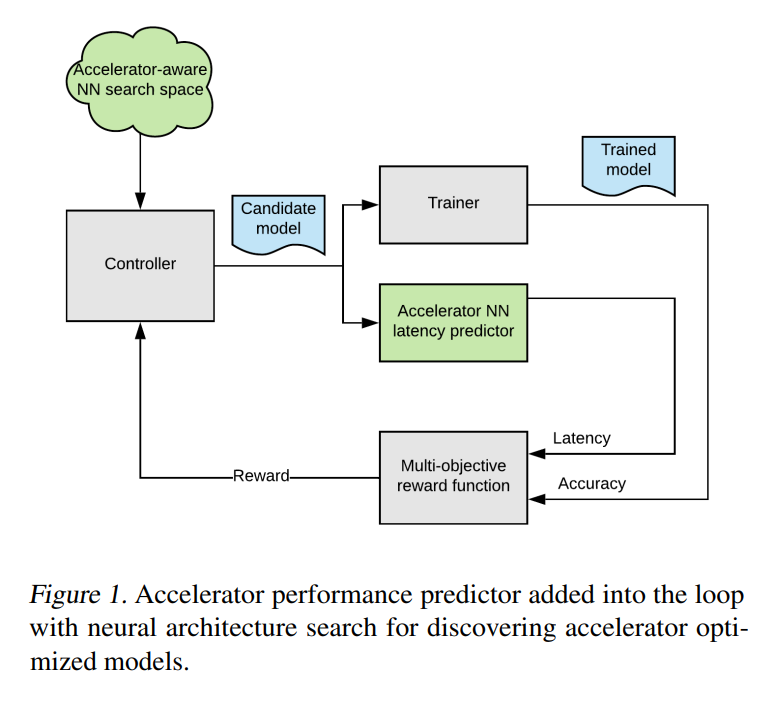
EfficentNet-EdgeTPU
Mobile Phoneではなく、エッジデバイスに特化したモデルをNASで生成したものが Google のEfficientNet-EdgeTPU
Googleのブログ「EEfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML」
そして論文は、こちら、「Accelerator-aware Neural Network Design using AutoML」、Suyog Gupta, Berkin Akin
EfficientNet-EdgeTPUの日本語の解説がこちら。
webbigdata.jp
Latencyを Google Edge TPU を使って測定している。
ベースとなっている EfficientNetの日本語の解説はこちら。
qiita.com
論文は、こちら。「EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks」
Mingxing Tan, Quoc V. Le
NASnet, MnasNet, EfficientNet、3つの論文には、Quoc V. Le さんの名前が。。。しかしながら、EfficientNet-EdgeTPUの論文にはない。
ここまでは、既にあるハードウェア (Mobile Phone、Google Edge TPU) に対して、NAS にてモデル探索をやったお話。
追記)、2021.01.03
(MobileNetV2とMobileNetV3って、何が違うのかな?と思い、Google君に聞いたら、
に詳しく書いてあって、V3はAutoMLにて生成したということを知ったので追記した。
NAHAS
まだ、https://arxiv.org/ にはアップされていない下記の論文
「NAHAS: Neural Architecture and Hardware Accelerator Search」、
NAHAS: Neural Architecture and Hardware Accelerator Search | OpenReview
ICLR 2021(2021年5月に開催される)に投稿された論文のレビュー中のもの。
こちらは、NASとハードウェアの構成を同時に行うという論文。中身を読むと、Google の人の論文でかつ、Google Edge TPU の改善版ハードウェアをNASで見つけるというもの。
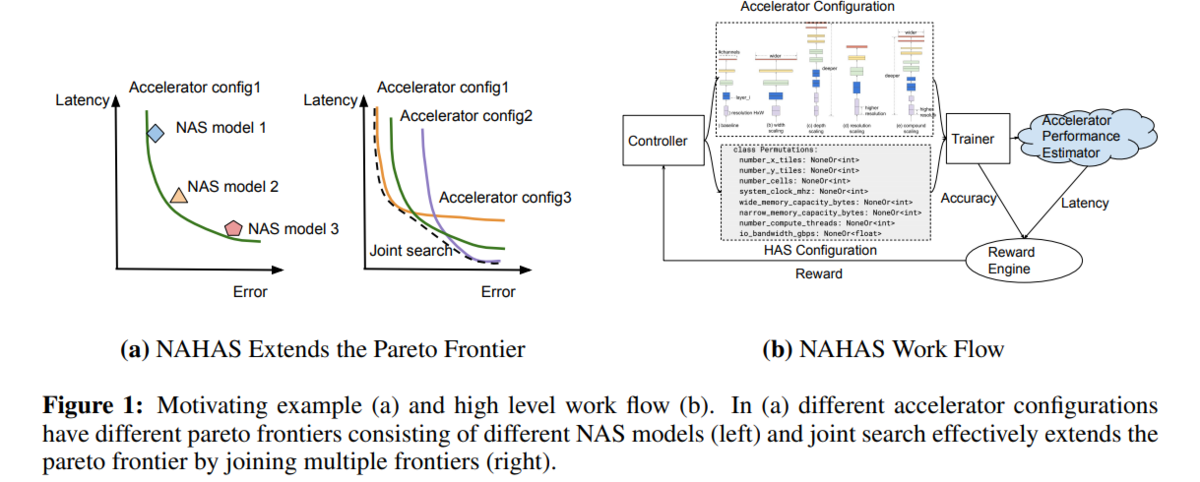
ControllerとTrainerの間に、Accelerator ConfigurationとHAS Configurationが入っているのが 「EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML」との違い。
まだ存在しないハードウェアをこのシステムで作る感じ。
ハードウェア側のConfigurationは下表のようなもの。PEの数(x方向、y方向)、SIMD units、レジスタファイルサイズ、ローカルメモリサイズ、compute lanes、I/Oバンド幅
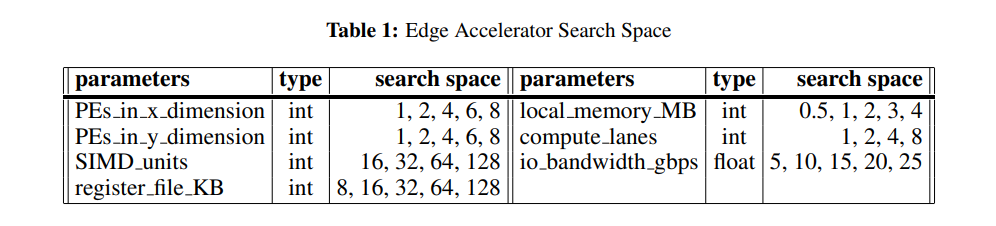
baseline の性能が「26 TOPS/s at 0.8 GHz.」なので、Google Edge TPUの 4 TOPSの7.5倍です。。。そこがスタート。
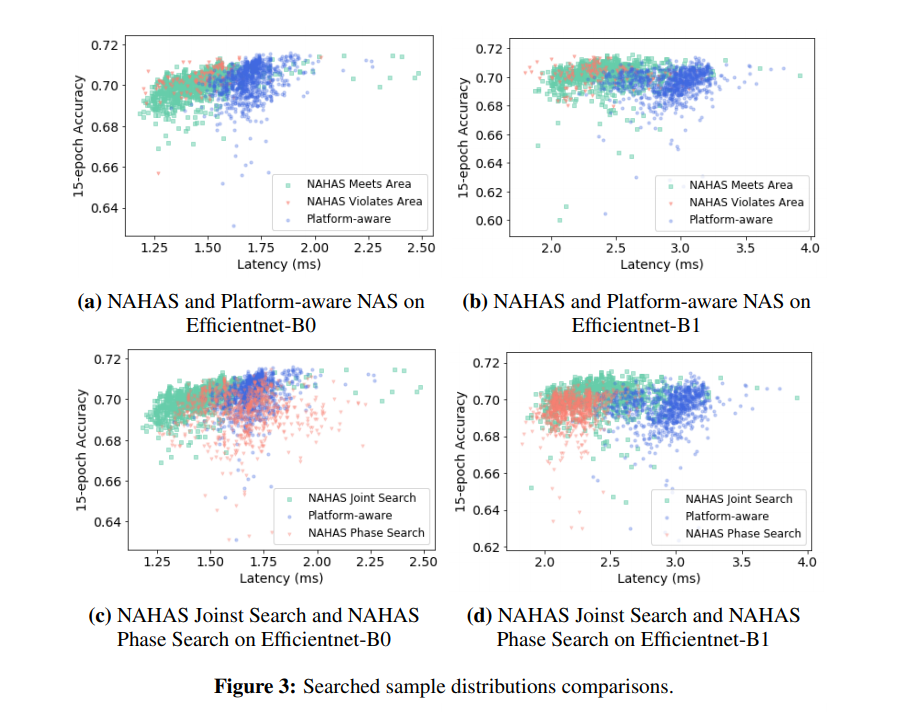
Platform awareって、MnasNetの論文のタイトル。そして、EfficientNetとあるので、「EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML」との比較。
そして、こちらのグラフ。EfficientNet、Fixed-Hardware (NAHAS with default accelerator configuration)
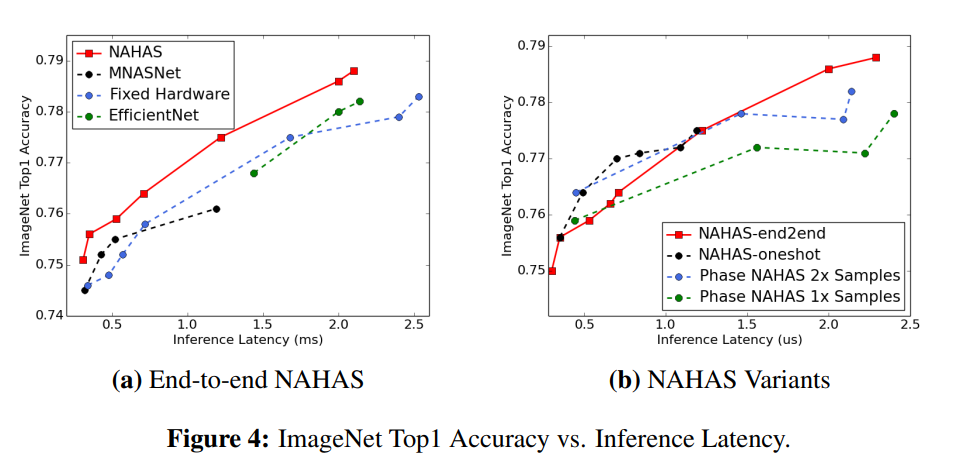
既にあるハードウェアに対して、HASにてConfiguraionを決めたら、Latencyが変わらずに0.5-1.0%ぐらい精度が上がった。
おまけとして、
「Oneshot NAHAS reduces the search cost from 32 TPU-days to 1 TPU-day for a MobileNetV2 search space. However, oneshot is not suitable for large models such as models in EfficientNet search spaces.」
とあった。32 TPU-days が 1 TPU-day になるのはすごい。ただし、EfficientNetのような大きなモデルには適応できないっぽい。
NAS => NASnet => MnasNet => EfficientNet (EfficentNet-EdgeTPU) => NAHAS
最後に、
このようにハードウェアのConfigurationをNASで探索するなんて、富豪以外できないと思うので、これができるのはGoogleぐらいなのかな?
P.S
論文の最後に、「Moreover, it enables more rapid evolution of hardware along with the software stack.」と書いてあった。これは、次のステップへの予感。
追記)、2021.03.14
Rethinking Co-design of Neural Architectures and Hardware Accelerators なる論文が、2021.02.17 にアップされていました。
arxiv.org