はじめに
半導体において、スケーリングで各世代で倍半分というのがずーと続いていましたが、7nm を超えて、5nm ぐらいからSRAMに関してはサイズが小さきならなくなってしまいました。
それがぱっと見わかる図がXの投稿に流れてきたので、記録に残します。
Why did SRAM scalling stall at th 3nm node ?
と書かれた下記のXの投稿に、各プロセスのSRAMのサイズが載っています。
Why did SRAM scaling stall at the 3nm node? pic.twitter.com/6AiWPUhJ10
— 🌿 lithos (@lithos_graphein) 2024年9月12日
投稿が無くなるともったいないので、図を説明のために引用します。
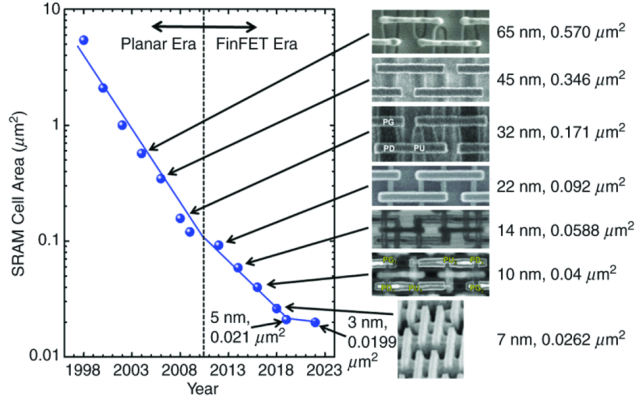
- 65 nm, 0.570 um2
- 45 nm, 0.346 um2
- 32 nm, 0.171 ums
- 22 nm, 0.092 um2
- 14 nm, 0.0588 um2
- 10 nm, 0.04 um2
- 7nm, 0.262 um2
- 5 nm, 0.21 um2
- 3nm, 0.0199 um2
です。
Planar Era と FinFET Era では、傾きが違いますね。
- Planar Era では、世代ごとに倍半分がなりたった。
- FinFET Era では、その傾きが小さくなった。ざっくり2世代で倍半分。しかし、7nm の 0.0262 => 5nm の 0.021 => 3nm の 0.0199 とほぼ変わなくなってしまった。
おわりに
FinFET => GAA になって、これが改善できるのでしょうか?
Backside Power もありますが、こちらも多少は良い方向になるのでしょうか?
AI Cloud Startup が 16nm => 7nm と進めてきて、次は 3nm か?と思いましたが、上記のようにSRAMのスケーリングが効かなくなってしまい、プロセスにお願いができなくなったのは非常に大きいと覆います。
例えば、Cerebras Systerms の WSE ですが、下記のようになっています。
- CS-1 : TSMC 16nm, トランジスタ数(1.2 Trillion), コア(400,000), SRAM(18GB)
- CS-2 : TSMC 7nm, トランジスタ数(2.6 Trillion), コア(850,000), SRAM(40GB)
- CS-3 : TSMC 5nm, トランジスタ数(4.0 Trillion), コア(900,000), SRAM(44GB)
CS-1からCS-2では、トランジスタ数は 2.166倍、SRAMが2.2倍になっています。
が
CS-2からCS-3では、トランジスタ数は 1.538倍、SRAMは1.1倍です。
つまり、SRAMをいっぱい入れる作戦は5nmで出来なくなってしまいました。
さあ、次はどうする?