はじめに
今回の TT-Metalium の例題は、DRAMからTensixへのデータ移動の例です。
- DRAM loopbackが説明です
サンプルプログラムの内容
下記のように、
- CommandQueue
- Program
- CoreCoord
のおまじないをします。
int main(int argc, char **argv) {
if (getenv("TT_METAL_SLOW_DISPATCH_MODE") != nullptr) {
TT_THROW("Test not supported w/ slow dispatch, exiting");
}
bool pass = true;
try {
/*
* Silicon accelerator setup
*/
constexpr int device_id = 0;
Device *device =
CreateDevice(device_id);
/*
* Setup program and command queue to execute along with its buffers and kernels to use
*/
CommandQueue& cq = device->command_queue();
Program program = CreateProgram();
constexpr CoreCoord core = {0, 0};
カーネル
下記の部分でカーネルを生成しています。プログラムは、"loopback_dram_copy.cpp" です。
KernelHandle dram_copy_kernel_id = CreateKernel(
program,
"tt_metal/programming_examples/loopback/kernels/loopback_dram_copy.cpp",
core,
DataMovementConfig{.processor = DataMovementProcessor::RISCV_0, .noc = NOC::RISCV_0_default}
);
ここでのポイントは、下記のところです。上記のプログラム、"loopback_dram_copy.cpp" が動くのは、RISCV_0 です。RISCV_0をDRAMからのデータをL1 Memoryし、その後、L1 MemoryからDRAMにデータを移動するために使います。
DataMovementConfig{.processor = DataMovementProcessor::RISCV_0, .noc = NOC::RISCV_0_default}
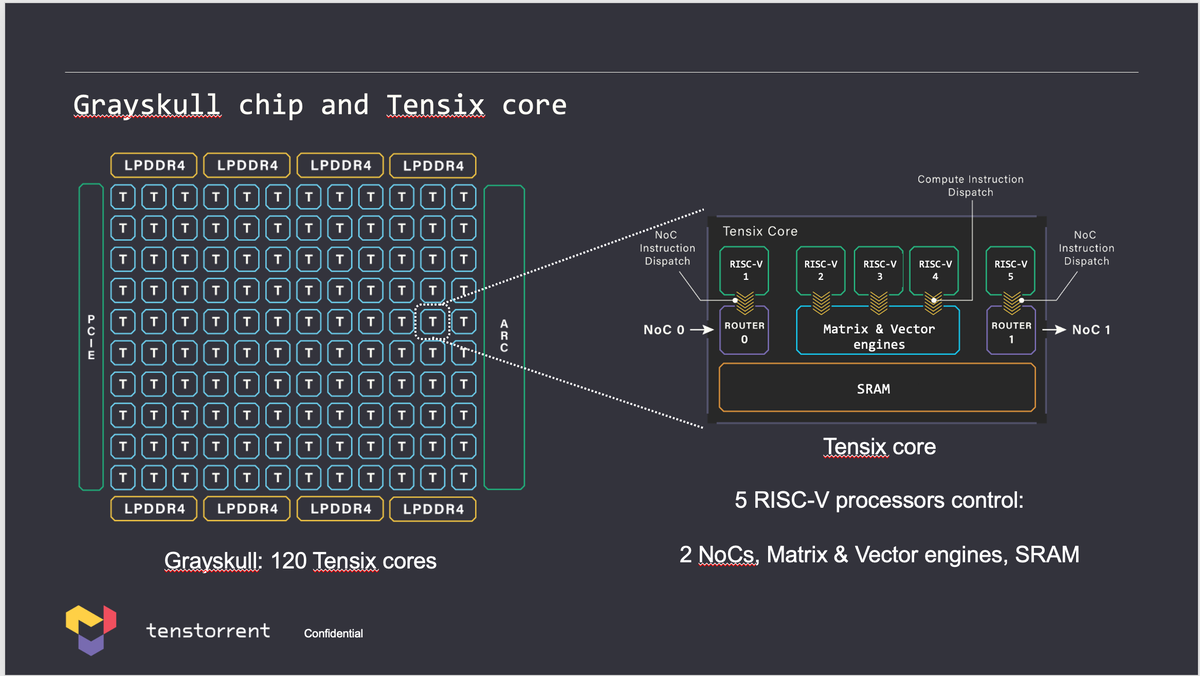
具体的には、下図の右側にある Tensix core の中の RISC-V 1 が RISCV_0 になります。
下記がカーネルプログラムの "loopback_dram_copy.cpp" です。
#include <cstdint>
void kernel_main() {
std::uint32_t l1_buffer_addr = get_arg_val<uint32_t>(0);
std::uint32_t dram_buffer_src_addr = get_arg_val<uint32_t>(1);
std::uint32_t dram_src_noc_x = get_arg_val<uint32_t>(2);
std::uint32_t dram_src_noc_y = get_arg_val<uint32_t>(3);
std::uint32_t dram_buffer_dst_addr = get_arg_val<uint32_t>(4);
std::uint32_t dram_dst_noc_x = get_arg_val<uint32_t>(5);
std::uint32_t dram_dst_noc_y = get_arg_val<uint32_t>(6);
std::uint32_t dram_buffer_size = get_arg_val<uint32_t>(7);
std::uint64_t dram_buffer_src_noc_addr = get_noc_addr(dram_src_noc_x, dram_src_noc_y, dram_buffer_src_addr);
noc_async_read(dram_buffer_src_noc_addr, l1_buffer_addr, dram_buffer_size);
noc_async_read_barrier();
std::uint64_t dram_buffer_dst_noc_addr = get_noc_addr(dram_dst_noc_x, dram_dst_noc_y, dram_buffer_dst_addr);
noc_async_write(l1_buffer_addr, dram_buffer_dst_noc_addr, dram_buffer_size);
noc_async_write_barrier();
}
下記の部分で、DRAMのアドレスを dram_buffer_src_noc_addr に設定し、noc_async_read API で DRAM (dram_buffer_src_noc_addr ) => L1 Memory (l1_buffer_addr) にデータを移動します。noc_async_read_barrier API でデータ移動が完了するのを待ちます。
std::uint64_t dram_buffer_src_noc_addr = get_noc_addr(dram_src_noc_x, dram_src_noc_y, dram_buffer_src_addr);
noc_async_read(dram_buffer_src_noc_addr, l1_buffer_addr, dram_buffer_size);
noc_async_read_barrier();
下記の部分が逆で、L1 Memory (l1_buffer_addr) => DRAM (dram_buffer_dst_noc_add) へのデータ移動です。noc_async_write API で DRAM へのデータ移動をし、noc_async_write_barrier API でデータ移動が終了するのを待ちます。
std::uint64_t dram_buffer_dst_noc_addr = get_noc_addr(dram_dst_noc_x, dram_dst_noc_y, dram_buffer_dst_addr);
noc_async_write(l1_buffer_addr, dram_buffer_dst_noc_addr, dram_buffer_size);
noc_async_write_barrier();
バッファ
メインのプログラムに戻って、カーネルに接続するバッファのタイプを決めています。
constexpr uint32_t single_tile_size = 2 * (32 * 32);
constexpr uint32_t num_tiles = 50;
constexpr uint32_t dram_buffer_size = single_tile_size * num_tiles;
tt::tt_metal::InterleavedBufferConfig dram_config{
.device= device,
.size = dram_buffer_size,
.page_size = dram_buffer_size,
.buffer_type = tt::tt_metal::BufferType::DRAM
};
tt::tt_metal::InterleavedBufferConfig l1_config{
.device= device,
.size = dram_buffer_size,
.page_size = dram_buffer_size,
.buffer_type = tt::tt_metal::BufferType::L1
};
DRAM 側が dram_config, L1 Memory 側が l1_config になります。違いは、.buffer_type で、tt:tt_metal::BufferType::DRAM と tt::tt_metal::BufferType::L1 の違いです。
この dram_conig と l1_config を使って、CreateBuffer API にて実際のバッファを生成します。
auto l1_buffer = CreateBuffer(l1_config);
auto input_dram_buffer = CreateBuffer(dram_config);
const uint32_t input_dram_buffer_addr = input_dram_buffer->address();
auto output_dram_buffer = CreateBuffer(dram_config);
const uint32_t output_dram_buffer_addr = output_dram_buffer->address();
- l1_buffer : L1 Memory内のバッファ
- input_dram_buffer : DRAM から L1 Memoryに移動するためのバッファ
- output_dram_buffer : L1 Memory から DRAM に移動するためのバッファ
です。
DRAM => L1 Memory に移動するためのデータの生成と、そのデータをDRAMに書き込むための部分が下記になります。
std::vector<uint32_t> input_vec = create_random_vector_of_bfloat16(
dram_buffer_size, 100, std::chrono::system_clock::now().time_since_epoch().count());
EnqueueWriteBuffer(cq, input_dram_buffer, input_vec, false);
create_random_vector_if_bfloat16 API にて、BF16なランダムなデータを100個生成します。そのデータを input_dram_buffer に移動するのが EnqueueWriteBuffer API です。
カーネルの実行
下記の部分がカーネルの実行部分です。
const std::vector<uint32_t> runtime_args = {
l1_buffer->address(),
input_dram_buffer->address(),
static_cast<uint32_t>(input_dram_buffer->noc_coordinates().x),
static_cast<uint32_t>(input_dram_buffer->noc_coordinates().y),
output_dram_buffer->address(),
static_cast<uint32_t>(output_dram_buffer->noc_coordinates().x),
static_cast<uint32_t>(output_dram_buffer->noc_coordinates().y),
l1_buffer->size()
};
SetRuntimeArgs(
program,
dram_copy_kernel_id,
core,
runtime_args
);
EnqueueProgram(cq, program, false);
Finish(cq);
runtime_args がカーネルへの引数で、SetRuntimeArgs API にて、dram_copy_kernel_id の引数として紐づけます(実際は、カーネルを実行するコアに引数を渡しています)
EnqueueProgram API にて、カーネルを実行し、Finish APIにてカーネルの実行終了を待ちます。
期待値比較
EnqueueReadBuffer APIにて、カーネルによって書き込まれたDRAMからデータを result_vec に読み込み、input_vec と比較します。そして、CloseDevice API のおまじないをします。
std::vector<uint32_t> result_vec;
EnqueueReadBuffer(cq, output_dram_buffer, result_vec, true);
pass &= input_vec == result_vec;
pass &= CloseDevice(device);
おわりに
この部分も、OpenCL と同じ感じですね。
次回は、カーネル内で処理をする例を見てみます。