はじめに
Xの投稿に下記の内容について、流れてきました。
Intel Gaudi 2 Accelerator Up To 55% Faster Than NVIDIA H100 In Stable Diffusion, 3x Faster Than A100 In AI Benchmark Showdown https://t.co/5X0qXq7nzQ https://t.co/5X0qXq7nzQ
— Hassan Mujtaba (@hms1193) 2024年3月11日
wccftech の記事は、こちら。
stability.ai の元記事
元記事は、stability.ai のブログです
というか、Intel Habana Gaudi2 を積極的に導入しています。Intel が協力しているからですね。4000台の Gaudi2 を調達しています。
Gaudi2 と H100/80GB, A100/80GB の比較
Stable Diffusion 3 のケースでは、
下記の表は、上記の Stability.ai のブログから説明のために引用します。2ノードでの比較において、H100-80GB の 595 => 927、A100-80GB の 381 => 927 ということです。
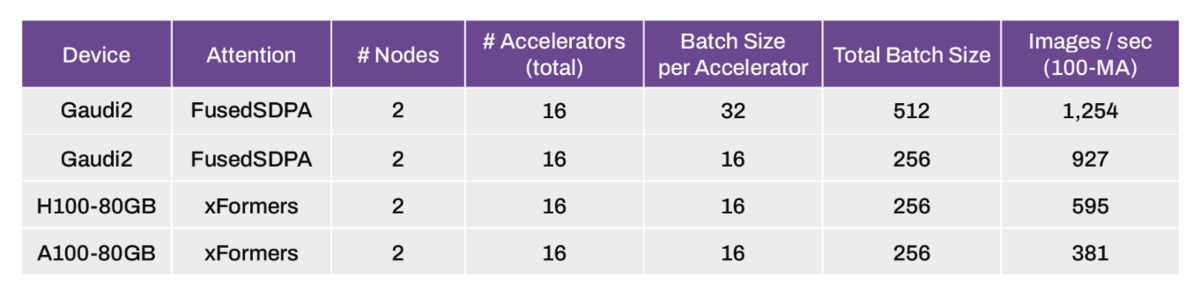
ノード数を増やした比較(32ノード)では、A100-80GB に対して、3倍以上になっています。

Stable Beluga 2.5 70Bのケース(our fine-tuned version of LLaMA 2 70B)のケースでは、
256 Gaudi 2 (PyTorch) : 116,777 tokens/secondで学習 (his involves using a FP16 datatype, a global batch size of 1024, gradient accumulation steps of 2, and micro batch size of 2)
Inference : Gaudi2 : 673 tokens/second per accelerator (using an input token size of 128 and output token size of 2048)
- Inference : A100 (TensorRT-LLM) : 525 tokens/second
A100より、25%速いと。。
おわりに
- Stable Diffusion 3 では、A100に対して3倍。
- Stable Beluga 2.5 70B is our fine-tuned version of LLaMA 2 70B では、A100に対して、25%速いと。H100よりは速くないからデータを出していないのね。
まー、Stabitily.ai は、Stable Diffusionの会社ですからね。。。
Gaudi2関連ブログ