Vengineerの戯言 : Twitter
SystemVerilogの世界へようこそ、すべては、SystemC v0.9公開から始まった
はじめに、
昨日、「Sima.ai の MLSoC (AI Edge デバイス)って、どんなものだろうか?」にて、SiMa.ai について調べていたら、ディープラーニングフレームワークにTVMを使っていました。
vengineer.hatenablog.com
SiMa.aiのMLAは TVM にとっては新しいアクセラレータなので、どのような仕組みで取り込んでいったのか気になりました。
そこで、今日は、TVMではどのようにして、新しいアクセラレータに対応しているのかについて探っていきます。
TVMについて、復習
学習側のディープラーニングは、
- TensorFlow / Kera
- PyToch
の2大フレームワークに決まりました。
一方、推論(Deploy)側も TensorFlow / Kera や PyToch でも OK ならいいのですが、組み込みの世界なので Python 使えない、C/C++のシステムに組み込みたい、ということがあります。
また、ハードウェア(アクセラレータ)の環境が C/C++ 前提ということもあります。
TVMは Python だけでなく、C/C++ や Rust にも対応しています。
また、TVMはモデルを .so ファイルに export でき、推論時には この .so ファイルを import することができるので、モデルの内容が簡単には分からないだけでなく、実行可能なイメージになっているのも特徴です。
TVMが対応しているハードウェアは、以下のように、主要なものはほぼサポートしています。
この他に、下記のようなライブラリにも対応しています。
- ARM Compute Library
- CBLAS
- CoreML
- CuDNN
- DNNL
- EdgeTPU (Google TensorFlow Lite)
- ARM NPU:Ethon-N
- AMD MIOpen
- NNPACK
- ONNX
- ROCLABS
- Google TensorFlow Lite
- NVIDIA TensorRT
- Thust
- Xilinx Vitis AI
これだけいっぱいあれば、通常使う分には全く困ることはないのです。
しかしながら、独自に新しいアクセラレータを開発した時には、そのアクセラレータを TVM に対応させるにはどうしたらいいのか?
TVMには新しいアクセラレータを対応するための仕組みが用意されていて、ドキュメントもそろっているようです。
(TensorFlowやPyTorchでも新しいアクセラレータをサポートすることはできるが、その仕組みが明確になっていなかったり、ドキュメントがそろっていないようです。
いやいや、TensorFlowでは、XLAがあるではないか?。
あんた、いろいろと調べて、勉強会で発表したり、インターフェースに記事を書いたりしていたんじゃないか?と言われるかもしれません。
TensorFlow XLには仕組みはありますが、その仕組みを利用するための API がバージョン毎によく変わってしまいます。また、ドキュメントは全くありません)
TVM : BYOC (Bring Your Own Codegen)
BYOC (Bring Your Own Codegen) は、TVM に 新しいアクセラレータを対応するための仕組み です。あたしがこの仕組みを知ったのは、SiMa.ai の MLSoC について調べた昨日です。
この BYOC は、2020年7月15日に、以下のTVMのブログ (How to Bring Your Own Codegen to TVM) にて発表されていました。
tvm.apache.org
また、2020年12月2日-4日に開催された TVM Conference 2020 では、「Tutorials - Bring Your Own Codegen to TVM」という Tutorials があり、その時のビデオは下記のように Youtube にアップされています。www.youtube.com
通常、利用する学習済みのモデルの中にあるオペレータすべてを新しいアクセラレータがサポートしていることはありません。そのため、サポートしていないオペレータはCPUで実行する必要があります。そこで、モデルを新しいアクセラレータで実行するオペレータからなるサブグラフとCPUで実行するオペレータからなるサブグラフに分割する必要があります。分割したサブグラフは、新しいアクセラレータ用に1つ、CPU用に1つ、というわけではなく、それぞれ2つ以上の場合もあります。
GoogleのEdge TPUでは、TensorFlow Liteのモデルをコンパイラにて、CPUで実行、Edge TPUで実行するサブブラフに分割しますが、現時点では Edge TPU で実行できるのは1つのサブグラフだけで、CPU => Edge TPU => CPU のような感じで実行されます。なお、最初と最後の CPU の部分は必要がなければ実行されません。
TVMのBYOCでは、CPUおよび新しいアクセラレータで実行するサブグラフの数には制限が無いようです。つまり、CPU => 新しいアクセラレータ => CPU => 新しいアクセラレータ => CPU のように CPU と 新しいアクセラレータ 間を行ったり来たりすることも可能です。とはいっても、CPU と 新しいアクセラレータの切り替え時には、データの移動が必要です。データの移動の時間が CPUで実行するより新しいアクセラレータで実行した方が速くなった時間より多い場合は切り替えるのはあんまり意味はありませんが。
また、分割したサブグラフの中ではオペレータの融合(Fusion)するという最適化も必要です。
このように、モデルを CPU と 新しいアクセラレータで実行するサブグラフに分割し、その後、Runtime にて CPU と 新しいアクセラレータで 分割したサブグラフを実行する仕組みが TVM の BYOC にて提供されるようになったようです。
そのBYOC の仕組みは、上記のブログには、次のようなステップで実現していると明記されています。
1. Graph Annotation
2. Graph Transformation
2.1: Merge compiler region
2.2: Partition Graph
3. Code Generation
4. Runtime
ブログにある下記のモデルの図を引用しながら、上記のステップがどのように実行されるかを見ていきます。
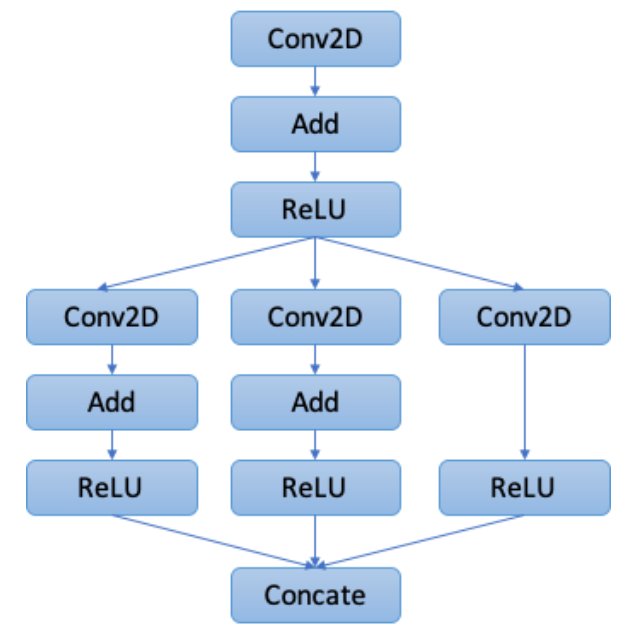
1. Graph Annotation
Graph Annotation では、モデル内の各オペレータが新しいアクセラレータで実行できるかどうか、ラベルを付ける作業です。これは、TensorFlow XLAでも同じようなことをしています。
最初のモデルの各オペレータの内、Conv2D + Add + ReLU の 3つのオペレータが Conv2D_Add_ReLU の1つのオペレータに変換されています。これは新しいアクセラレータでは、Conv2D => Add => ReLU という順番になっている場合は、Conv2D_Add_ReLU という1つのオペレータに置き換えらえるようになっているためです。右側の Conv2D => ReLU の部分は 途中に Add が入っていないので、Conv2D_Add_ReLU オペレータには変換されていません。Concate オペレータは 新しいアクセラレータではサポートしていないので オレンジになって、CPUで実行することになります。
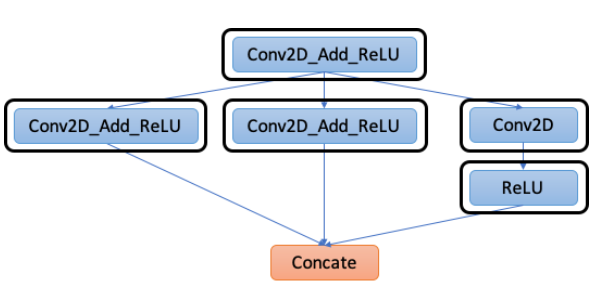
2. Graph Transformation
Graph Transformationでは、2つのステップ、2.1 Merge compiler region と 2.2 Partition Graph で行われます。
2.1 Merge compiler region では 新しいアクセラレータで実行できるオペレータをまとめる作業です。各オペレータ毎に新しいアクセラレータを起動すると、その度にデータ移動と新しいアクセラレータでの起動時のオーバーヘッドが伴うので新しいアクセラレータで連続実行できる部分をまとめる必要があるからです。下図では水色のオペレータ全部が1つのサブグラフになっています。
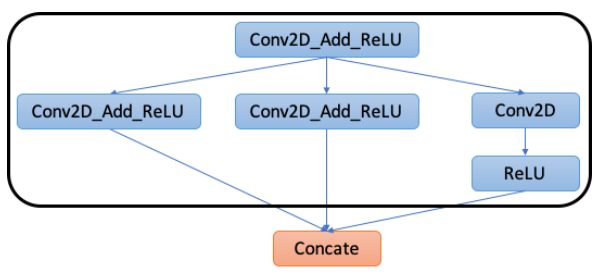
2.2 Partition Graph にて、新しいアクセラレータで連続実行できる部分をサブグラフとして分割します。このサブグラフを1つの新しいオペレータに置き換えしまいます。
下図では、Fn1というオペレータにして、Compilerとして、your_acelerator を指定しています。この Fn1 のオペレータは新しいアクセラレータで実行されます。ソフトウェア的には新しいアクセラレータのRuntime上で実行されることになります。
TensorFlow XLAでも同じようにサブブラフを1つのオペレータに置き換え、置き換えたサブグラフをアクセラレータで実行するようになっています。
また、Googe Edge TPUの場合は、Edge TPUで実行される部分のサブグラフは、edgetpu-custom-op というオペレータになっています。
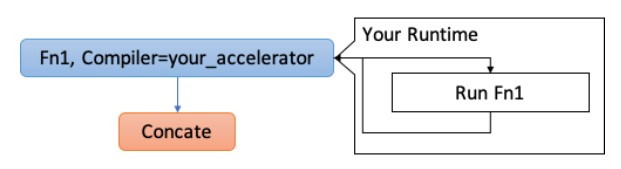
3. Code Generation
Code Generationでは、新しいアクセラレータで実行されるサブグラフの部分のコードを生成します。
最終的に、新しいアクセラレータで実行されない部分のコードと一緒に、TVM の Python API である export_library にて1つの .so ファイルに出力します。
ここで生成した .so ファイルは、Runtime 時に使うことになります。.so ファイルなので簡単には中身を知ることができなくなっています。
4. Runtime
推論する場合は、3. Code Generationで生成した .so ファイルを TVM の runtime で読み込み、入力データと出力データの設定をして、実行 (run) するだけです。
実行時に、新しいアクセラレータで実行する必要があるサブグラフになったら、内部で勝手に新しいアクセラレータ側で実行できるようになります。
(3. Code Generationにて、新しいアクセラレータ側でサブグラフを実行するコードを生成する必要があるので、TVMが内部やってくれているというわけではありません)
BYOC に対応するためには?
上記ブログにて、DNNL(Intel Deep Neural Network Library)をBYOCにて対応していくステップが説明されているので見ていきましょう!
1. Graph Annotation のために、Annotation Rules を決めます。TVMのオペレータ(実際にはRelayのオペレータ)の内、DNNLでサポートしているオペレータを対応付けていきます。
下記のコードは、nn.conv2d オペレータが DNNL でサポート("target.dnnl")していることを示します。
@tvm.ir.register_op_attr("nn.conv2d", "target.dnnl") def _dnnl_conv2d_wrapper(attrs, args): return True
このようにして対応するオペレータに対して、Pythonコードを書いていくのですが、オペレータが多いと非常に煩雑になるので、下記のような helper 関数( _register_external_op_helper)を定義することで煩雑さを無くしています。
def _register_external_op_helper(op_name, supported=True): @tvm.ir.register_op_attr(op_name, "target.dnnl") def _func_wrapper(attrs, args): return supported return _func_wrapper _register_external_op_helper("nn.batch_norm") _register_external_op_helper("nn.conv2d") _register_external_op_helper("nn.dense") _register_external_op_helper("nn.relu") _register_external_op_helper("add") _register_external_op_helper("subtract") _register_external_op_helper("multiply")
nn.batch_norm, nn.conv2d, nn.dense, nn.relu, add, subtract, multiiply が DNNL でサポートしているオペレータになります。
2. Graph Transformation のために、graph pattern のルールを書いていきます。DNNLで複数のオペレータが融合(Fuse)しているものに対して、graph pattern のルールを書きます。
DNNLConv2d(const bool has_bias = false, const bool has_relu = false) { // ... skip ... auto conv_desc = dnnl::convolution_forward::desc( dnnl::prop_kind::forward_inference, dnnl::algorithm::convolution_direct, conv_src_md, conv_weights_md, conv_bias_md, conv_dst_md, strides_dims, padding_dims_l, padding_dims_r); // Attach ReLU dnnl::primitive_attr attr; if (has_relu) { dnnl::post_ops ops; ops.append_eltwise(1.f, dnnl::algorithm::eltwise_relu, 0.f, 0.f); attr.set_post_ops(ops); } auto conv2d_prim_desc = dnnl::convolution_forward::primitive_desc( conv_desc, attr, engine_); // ... skip ...
を使って、covn2d+relu を DNNLConv2D(false, true) に、conv2d+add+relu を DNNLConv2d(true,true) に変換できるようにします。
その時のコードは、以下のようになります。conv2d+add+relu が dnnl.conv2d_bias_relu に、conv2d+relu が dnn.conv2d.relu になります。
def make_pattern(with_bias=True): data = wildcard() weight = wildcard() bias = wildcard() conv = is_op('nn.conv2d')(data, weight) if with_bias: conv_out = is_op('add')(conv, bias) else: conv_out = conv return is_op('nn.relu')(conv_out) @register_pattern_table("dnnl") def pattern_table(): conv2d_bias_relu_pat = ("dnnl.conv2d_bias_relu", make_pattern(with_bias=True)) conv2d_relu_pat = ("dnnl.conv2d_relu", make_pattern(with_bias=False)) dnnl_patterns = [conv2d_bias_relu_pat, conv2d_relu_pat] return dnnl_patterns
この graph pattern を使って、次のようなコードにて、Graph Transformation を行います。
mod = create_relay_module_from_model() # Output: Figure 1 mod = transform.MergeComposite(pattern_table)(mod) mod = transform.AnnotateTarget(["dnnl"])(mod) # Output: Figure 2 mod = transform.MergeCompilerRegions()(mod) # Output: Figure 3 mod = transform.PartitionGraph()(mod) # Output: Figure 4
create_relay_module_from_model() にて、モデルからRelayモジュールに変換します。transform. から始まるコードが、Graph Transformation になります。
transform.MergeComposite で、pattern_table で定義した graph pattern を登録し、transform.Annotate.Target にて pattern_table を使って、dnnl の Annotation を行います。
transform.MergeCompilerRegions にて、2.1 のMerge compiler region を行い、transform.PartitionGraph にて 2.2 Partition Graph を行っています。
BYOCのステップと各関数の対応ができているので非常にわかりやすいですね。
DNNL対応の CodegenとRuntimeについては、ハードウェア(ライブラリ)依存になっているのでここでは深堀しません。
TVMが対応している Runtime については、ここ (src/runtime/contrib) にあるので、興味がある方はここを覗いてみてはどうでしょうか?
Google Edge TPU の runtime を覗いてみましたが、Edget TPU を C++ で使う時のコードと同じ感じでした。
最後のCodegen の部分は、次のようになっています。tvm.transform.PassContext を使います。最終的には、lib.export_library にて .so ファイルを生成します。この生成した .so ファイルを runtime ( runtime.module.loadbinary_dnnl_json )で呼び出すことになります。
def update_lib(lib): # Include the path of src/runtime/contrib/dnnl/dnnl.cc test_dir = os.path.dirname(os.path.realpath(os.path.expanduser(__file__))) source_dir = os.path.join(test_dir, "..", "..", "..") contrib_path = os.path.join(source_dir, "src", "runtime", "contrib") # Setup the gcc flag to compile DNNL code. kwargs = {} kwargs["options"] = ["-O2", "-std=c++14", "-I" + contrib_path] tmp_path = util.tempdir() lib_name = 'lib.so' lib_path = tmp_path.relpath(lib_name) # The generated C code with DNNL APIs is compiled to a binary lib.so. lib.export_library(lib_path, fcompile=False, **kwargs) # Load the lib.so back to a runtime module. lib = runtime.load_module(lib_path) return lib with tvm.transform.PassContext(opt_level=3): json, lib, param = relay.build(mod, target=target, params=params) lib = update_lib(lib) rt_mod = tvm.contrib.graph_runtime.create(json, lib, ctx)
update_lib のところは、DNNL用になっていますが、tvm.transform.PassContext 以降は共通部分だと思います(DNNLの場合は、json を使っているようですが)
SiMa.ai の TVM対応を振り返る
SiMa.ai の TVM対応のビデオを振り返ってみます。
youtu.be
下図(1:38頃)に、TVM対応の図があります。

SiMa.ai Frontend と SiMa.ai Backend に分かれています。SiMa.ai Frontendにて、TVMを使って、
- Graph Import & Transform
- Framework modules to Relay IR
- Relay graph transformation
をやっています。これは、上記のBYOCの最初の部分に対応するところです。
- Optimization
- Calibration
- Quantization
- SiMa custom graph transformation
- Weight compression
のところで Optimization を行っています。CalibrationとQuantizationはTVMの中でできる最適化、SiMa custom graph translationとWeight compressionはTVMの外でやる最適化のようです。
終わりに、
昨日、SiMa.aiのMLSoC について調べていたら出てきた TVM の BYOC。BYOCは、新しいアクセラレータを TVM に対応させるための仕組みで、非常によくできたものだと思いました。
TVM側での Graph Partition はどんなアクセラレータでも同じステップを行えばいいのはいいですね。また、Codegen の部分については新しいアクセラレータ毎に違いますが、Codegenを呼ぶところは基本的には同じコードというのもいいですね。
TVMのBYOCを知って、新しいアクセラレータを動かすためのコンパイラやランタイムは開発する必要はありますが、世の中に提供する場合は、TVM でいいんじゃないかと思いました。
追記)、
よく考えてみたら、TensorFlow/KerasやPyTorchに対して、新しいアクセラレータ対応をサポートする会社ってないんですよね。
TVMの場合は、TVMを立ち上げたメンバーが中心となって創業した OctoML が サポートサービスをやっているんですよね。
TVM Conf - Day 1 - Keynote and Community Update の OctoML の部分(下図は51:44頃)での OctoML のカスタマーは、
その他に、2社。こういうサービスがないと対応が独自になっちゃうからね。

おわり。
P.S
Amazon SageMaker も BYOC 対応しているようです。
aws.amazon.com
関連記事:
www.nextplatform.com