はじめに
NVIDIA H100関連については、既に4回、ブログに書きました。
今回は、H100の次を妄想します。
Ampere Next Next は、2024年
下図は、NVIDIA Confirms Ampere GPU Successor Arrives in 2022 & Next-Gen After That In 2024 In Its Latest Roadmapから説明のために引用します。2023年のGrace、2024年のBluefield-4、Ampere Next Next、2025年の Grace Next

H100
下記は、H100のWhitePaperからの抜粋です。A100とH100の比較の部分です。
- TSMC N7 : 4N customized for NVIDIA
- 826mm2 : 814mm2
- 54.2B : 80B
- 400 Watts : 700 Watts
- L2 Cache : 40MB : 50MB
- HBM (5120-bit) : HBM2 40GB : HBM3 80GB
- SM : 108 : 132
- TPCs : 64 : 66
- FP32 Cores / SM : 64 : 128
- FP64 : 3456 : 8448
- Tensor Cores : 432 : 528
- FP32 : 6912 : 16896
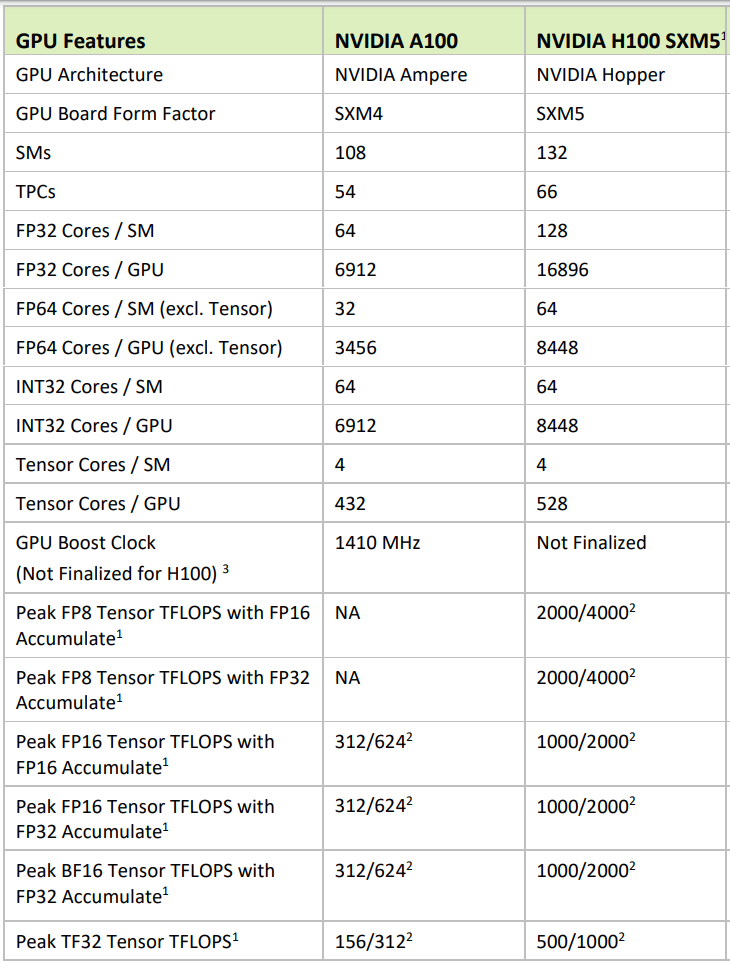
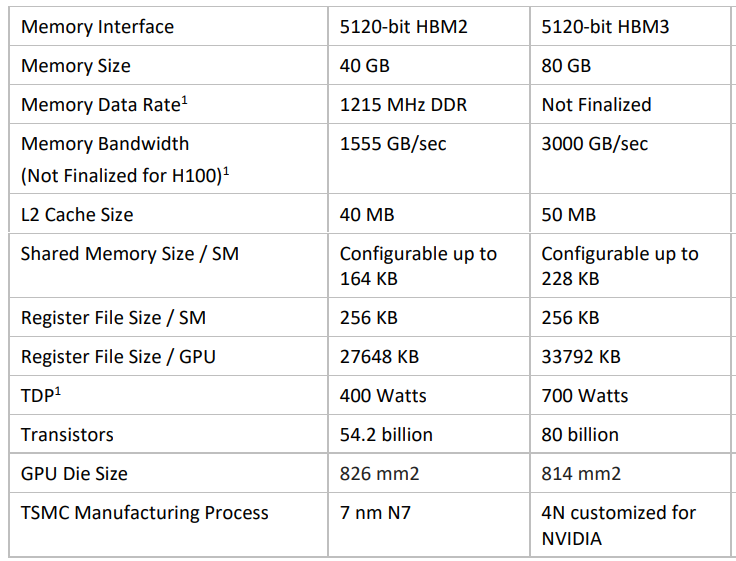
Silicon die の面積はA100に比べて、ちょっと小さいですが、トランジスタ数は1.5倍。FP32とFP64は倍増以上(SMとTPCの数が増えたので、2倍以上になっている)
全体の性能向上は、下図で分かります。
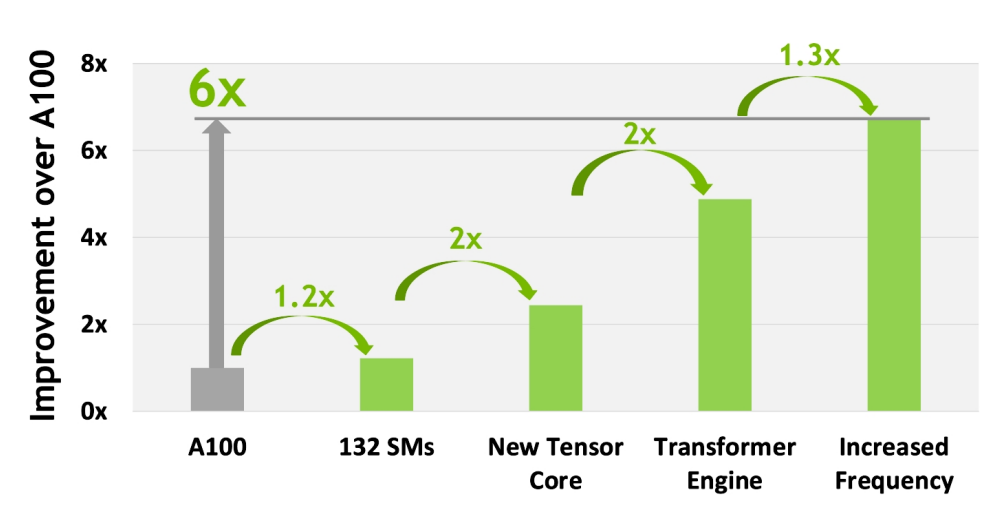
- SMs : 108 => 132 で 1.2x
- New Tensor Core : 2x
- Transformer Engine : 2x
Incresed Frequency : 1.3x
SM数が 1.2x だけど、FP32/FP64は SM単位で2倍になっているが、こちらはあまり性能には寄与しない?
- Tensor Cores 数は、432 => 528 なので1.2倍で、2倍の性能になるの?
Table 2.によると、Tensor Coreの性能そのものが向上したようですね。A100に対して、3倍以上なのに、上記の図では2倍になっているのは何故だろうか?
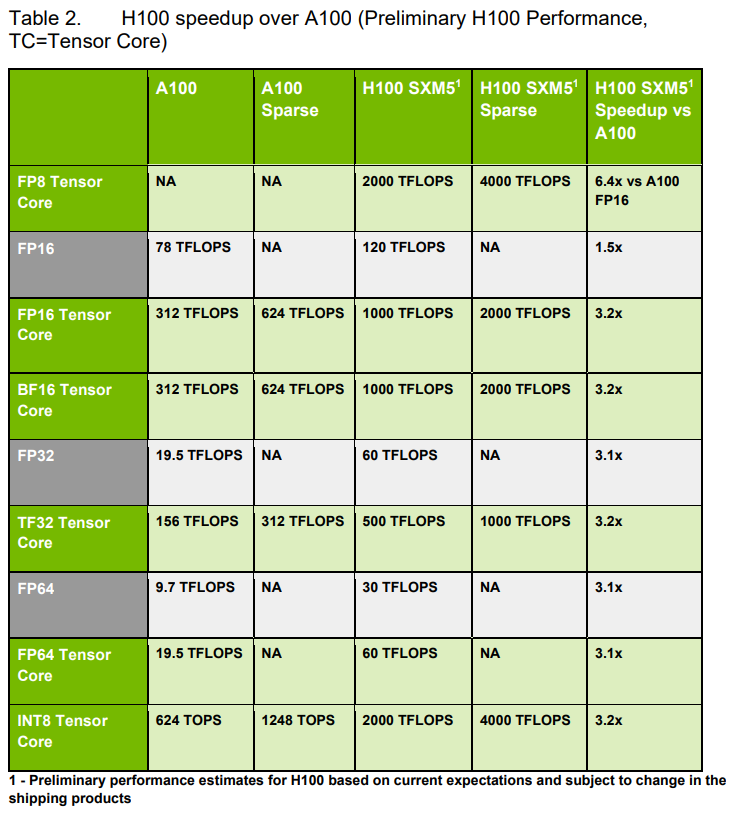
ここまでで、H100 は A100 に対して、いろいろと改善していることがわかりました。メモリも HBM2からHBM3になり転送レートが2倍になっています。SMやTensor Coreの性能向上でもメモリの転送レートは2倍でOKだったんでしょうかね。
White Paperでは、メモリ容量は A100は40GB、H100は80GBになっています。DGX A100のデータシートによると、GPU Memoryは、320GB total となっているので、1つのA100は40GBですね。あれ、40GBなんだ。。。
NVIDIA A100のデータシートには、40GBと80GBがあるとありました。
説明のために引用します。40GB版に対して、80GB版はメモリ帯域大きいです。。ということは動作周波数は高いと。。。だから、40GB品と比較しているんですね。
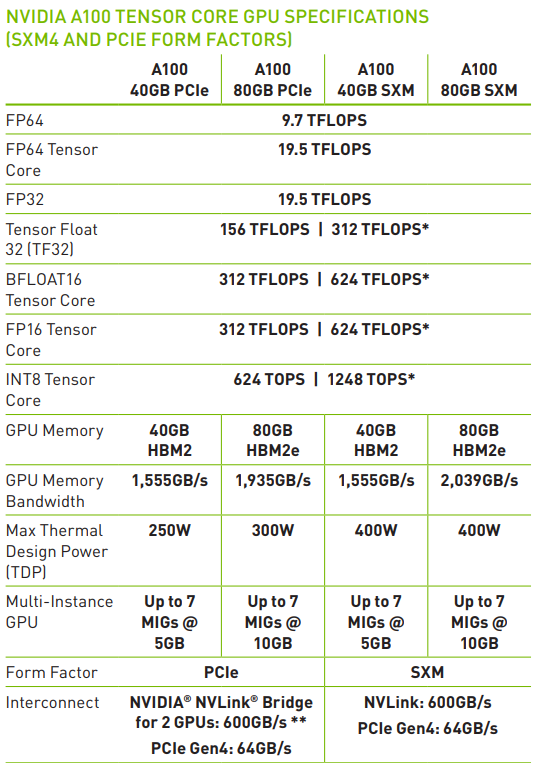
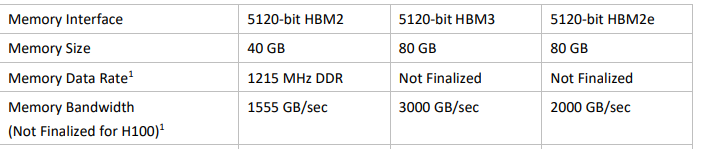
再度、H100のWhitePaperからDRAMの部分を切り出しました。HBM2 の場合は、A100の80GB版と同じメモリ転送レートですね。そうなると、A100/80GB版とH100(HBM3)/80GB版のメモリ帯域は、2倍ではなく、1.5倍なんですね。
A100の(HBM2)80GB(PCIe) は1935GB/s で、H100の(HBM2)80GB(PCIe) は、2000GB/s なのでほとんど変わらない。
L2 Cache は、White Paperでは A100は40MB、H100は50MBとなっています。6個のメモリの内、5個のみ使うということ。各メモリに対して、L2は 8MB (A100)、10MB (H100) になっているんですね。
さて、妄想
HBM3の積層メモリは、4層、8層、12層に対応。将来は16層。1層当たりのメモリ容量は8Gbitから32Gbitです。 H100の80GB = 16Gb x 8 = 16GB x 5の構成です。
16Gb品だと、
- 16Gb x12 = 24GB x 5/120GB
- 16Gb x16 = 32GB x 5/160GB
32Gb品だと、 - 32Gb x8 = 32GB x 5/160GB - 32Gb x12 = 48GB x 5/240GB - 32Gb x16 = 64GB x 5/320GB
まで可能です。320GBになると、8個のGPUで、2560GB = 2.5TB です。。これは、H100のホスト側のメモリの2TBより多いです。
メモリ容量は、320GBまでいけるということ
2021年4月5日の論文、GPU Domain Specialization via Composable On-Package Architectureでは、Packageについて書いてあります。IntelやAMDでもマルチダイですが、NVIDIAはまだSingle die + HBM Memory です。この論文では、HPC用のGPUとDL用のGPUをPackageで変える作戦についてです。
説明のために下記の図を引用します。GPU Moduleとメモリ部を分離し、DL用にはL3 Cache die を2つ追加すると。
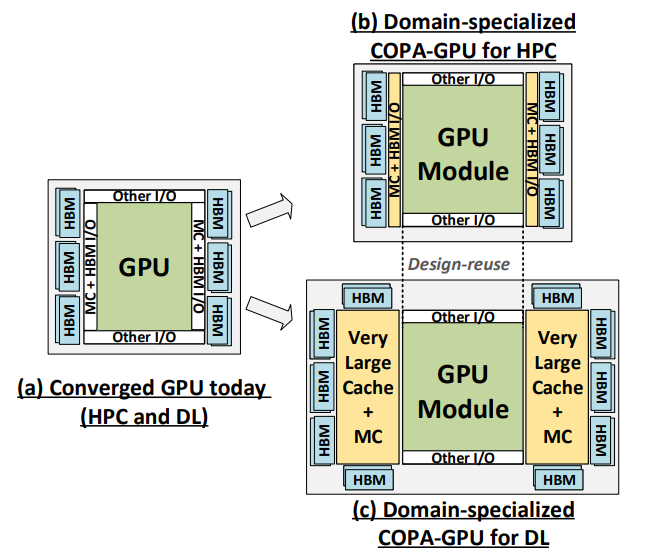
この図を見ると、HPC用はL3 Cacheは必要無いようですね。そのために L3 Cache を別 die にして、HPC/DL のコンフィギュレーションを Package にて変更すると。DL用は メモリを 6個から10個にもできます。
HBM3 x 10 だと、現状のH100だと、160GB、8個使いでも128GB。8個のGPUで1TBになります。HBM3メモリが16GBから24GBなら、1.5倍の 1.5TB、32GBなら 2倍の 2TB、48GBなら、3倍の4TB、64GBなら4倍の4TBです。10個のメモリ全部使うと、640GB x 8 = 5120GB/5TB にもなり、ホスト側のメモリよりも多くなっちゃいます。
おわりに
H100の次を妄想しました。計算機をいっぱい入れると、その計算機で使うデータを置くためのメモリが必要です。そのための作戦として、計算機の部分とメモリ(L3 Cache含む)を分ける感じですね。 Intelの Ponte Vecchio も同じように計算機用 die( Compute die)、Cache die (Rambo die)を組み合わせていますね。これと同じ作戦に近いですね。