はじめに
AWSがTrainium 2を発表したのは、昨年の11月、re:invent 2023 にて発表しました。その時のブログが
です。
この時は、
1 die に2個の NeuronCore-v2 が載っています。2個の HBM2E が載っています。HBM2E から HBM3 になれば転送レートが倍になるので、NeuronCore-v2を2倍の4個でもOKのようです。 HBMの容量は、3倍です。1 die で 1.5倍ということは、16GB x 2 => 24GB x 2 で、2 die なので96GBとなる模様。 16個の Trainium2 チップが載ったものが EC2 Trn2インスタンスになるということだと、上記の Trainium2 の Package が 8個で、チップは16個。 EC2 Trnインスタンスに対して、EC2 Trn2インスタンスは4倍の性能ですね。
と書いていました。
さあ、実際はどうだったかを確認しましょう!
Trainium 2
プレス
公式 Youtube は、こちら

AWSの公式ブログは、こちら
Each Trainium2 chip is home to eight NeuronCores and 96 GiB of High Bandwidth Memory (HBM), and supports 2.9 TB/second of HBM bandwidth
HBM関連は、当たっていますね。
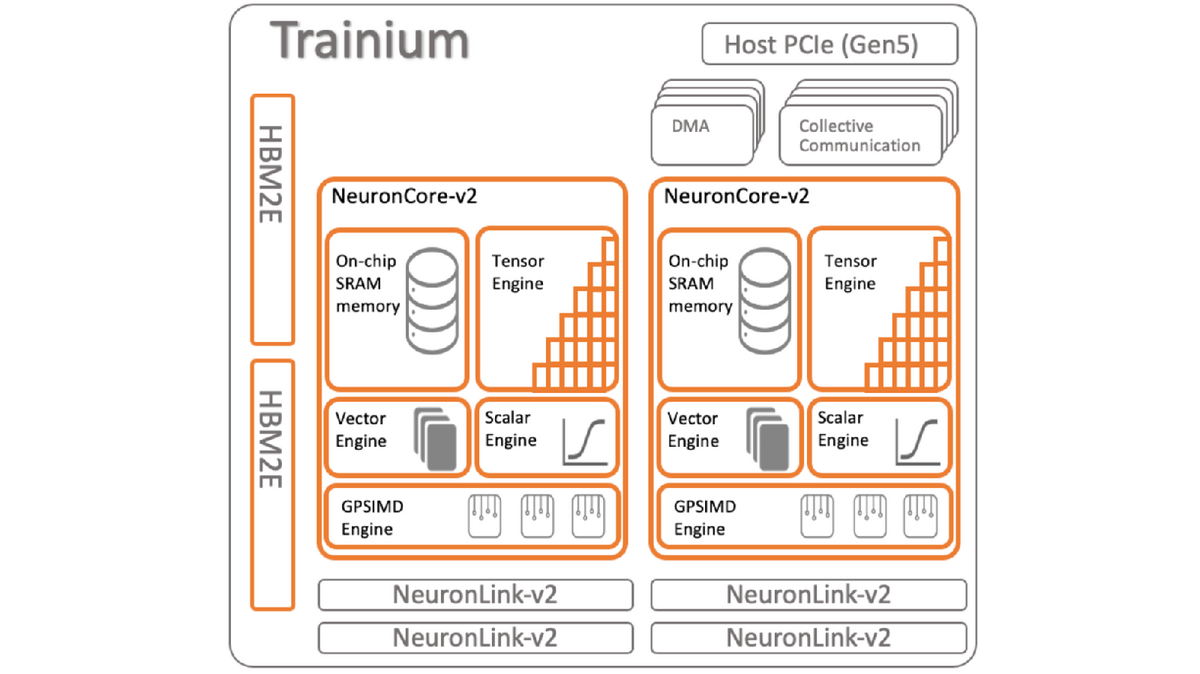
内部を見てみましょう。下記は上記のブログから説明のために引用します。
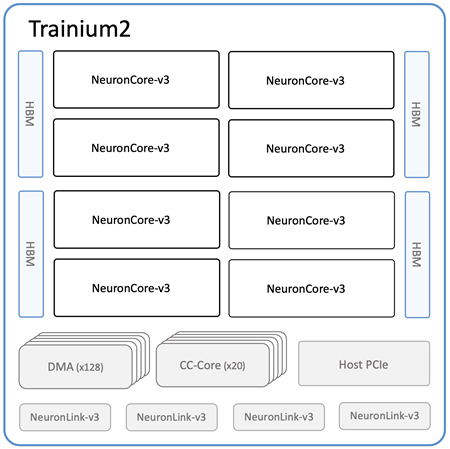
2 die で各 die に 2個の HBMを付いています。こちらも当たっています。
各 die には、NeuronCore-v3 が4個載っています。Trainium は NeuronCore-v2 が2個なので 2倍、こちらも当たっています。
NeuronLink-v3 は、4個。各 die では、2個なので Trainium と同じです。
違いは、
- DMA :
- CC-Core
ですね。
下記の Trainium と比べると、
- DMA : 4 => 128 (各die だと、4 => 64で、爆増)
- Collective Comminucation : 4 => 20 (各die だと、4 => 10 で、結構増えた)
です。
追記)、2025.05.01
AWSのTrainium/Inferentia2 Architecture Guide for NKIによると、
- 32 DMA (Direct Memory Access) engines to move data within and across devices.
6 CC-Cores for collective communication.
DMAは、4個ではなく、32個ある
- Collective Communication は、4 個ではなく、6個
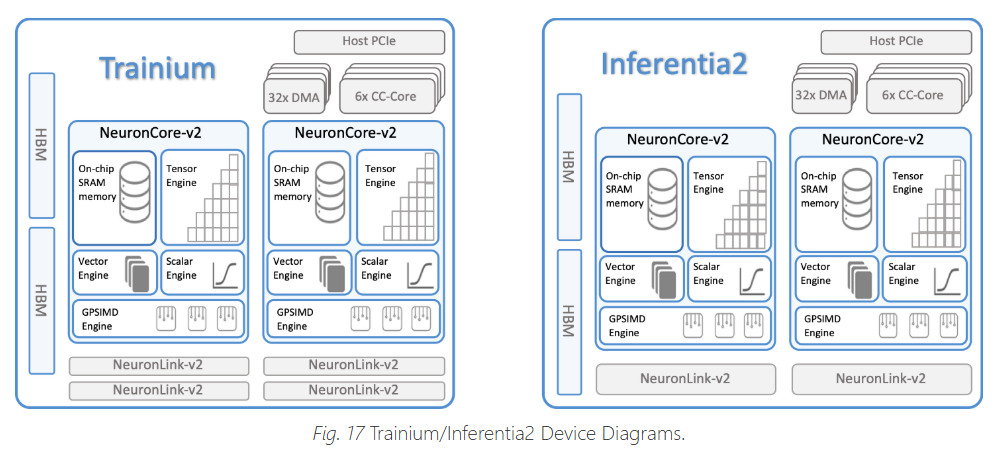
Trainium => Trainium 2 の die 当たりだと、
- DMA : 32 => 64
- CC : 6 => 10
になっていますね。
awsdocs-neuron.readthedocs-hosted.com
Inter-chip Interconnect (GB/sec/device)
- Trainiun : 384 => 384/4 = 96GB/s = 96 x 8 = 768 Gbps
- Trainium 2 : 1280 => 1280 / 4 = 320GB/s => 320 x 8 = 2560Gbps
なんか、凄いんだけど。。
- NeuroCore v2
- 90 TFLOPS of FP16/BF16
NeuroCove v3
- 158 cFP8 TFLOPS,
- 79 BF16/FP16/TF32 TFLOPS
NeuronCore-v3 supports several sparsity patterns, including 4:16, 4:12, 4:8, 2:8, 2:4, 1:4, and 1:
Server
- Trn2 Instances
- Trn2 UltraServers
2つのパッケージを下図のように2個のせたものが2個載せたものが、8個で Trn2 Instances を構成しているようです。
これちょっと違うようです。



Trn2 Instances を 4つまとめたのが、Trn2 UltraServers

性能
性能については、SemiAnalysysの下記の記事が詳しいです。
- BF16で、650 T FLOPs
- BF8 で、1300 T TOPs
なので、NVIDIA H100 の BF16 約 1 TFLOPs の 2/3 ぐらいですね。
Networkは、Trn2 の方は最大 800Gbps で、Trn2 UltraServers の方は 最大 200Gbps のようでうs。
AWSも800Gbpsを用意してきましたね。
おわりに
- 2018/11 : Inferentia 発表 (7nm)
- 2022/11 : Trainium 発表 (7nm)
- 2023/04 : Inferentia 2 一般公開
- 2023/12 : Trainium 2 発表 (5nm)
- 2024/12 : Trainium 2 一般公開
- 2024/12 : Trainium 3 発表 (3nm)
と着実に自社開発を進めていますね。
AWS は、Inference用の開発は中止するようですね。