はじめに
SimiAnalysis の記事を眺めていると、学びしかない
SRAMのスケーリングのお話
TSMC N7 => N5 では、
- Logic Area は、1.8 X
- SRAM Area は、1.35 X
- Analog Area は、1.2 X
であり、SRAMが多いと、全体としてはあまりスケールしないということに。
TSMCによると、N5 では 35 - 40 % ぐらい。 TSMCとSamsungでは、3D stacked SRAM というアプローチを進めている (AMD の Milan => Milan-X : L3 Cache Stack 付)って感じですかね。
こちらの記事によると、SRAMのスケーリングは
- N7 => N5 では、1.35 X
- N5 => N3 では、1.2 X
になるということ。
Pad Limit のお話
- 通常の filip chip packaging は、150-micron ~ 200-micron bump pitch
fine pitch flip chip - TSMC N7 : bump pitch => 130-micron - Intel 10nm : bump pitch => 100-micron
- I/Oを増やすために、die を大きくする。そのために、内部にSRAMをたくさん置く。。。=> AMD の CPU や GPU (Infinity Cache)
- AMDのGPUでは、GDDR6 のバス幅を 384bit => 256bit に削減
Apple A14 Die => A15 Dieのお話
- A14 : TSMC N5 (107.69mm^2)
A15 : TSMC N5P (87.67 mm2)
22.8 % ダイサイズアップ
LPDDR4x PHYのサイズは同じ
big core : Avalanche <= Firestorm
- L1 speeds が 1-cycle accesses to cache lines (A14では、3 cycles)
L2 は、8MB => 12MB (access latency は、16 cycles => 18 cycles)、die size は 52% up
little core : Blizzard <= Icestorm
- 18.6 % size up、23 % performace up
- die size : 2.5 % up
- Blizzard core の性能は、A76 相当
いろいろなパッケージング
Wire bonding後のパッケージングのフローは、 - Fluxing - Die Placement - Reflow - Flux Cleaning - Underfill - Cure
下図は下記の記事から説明のために引用します。
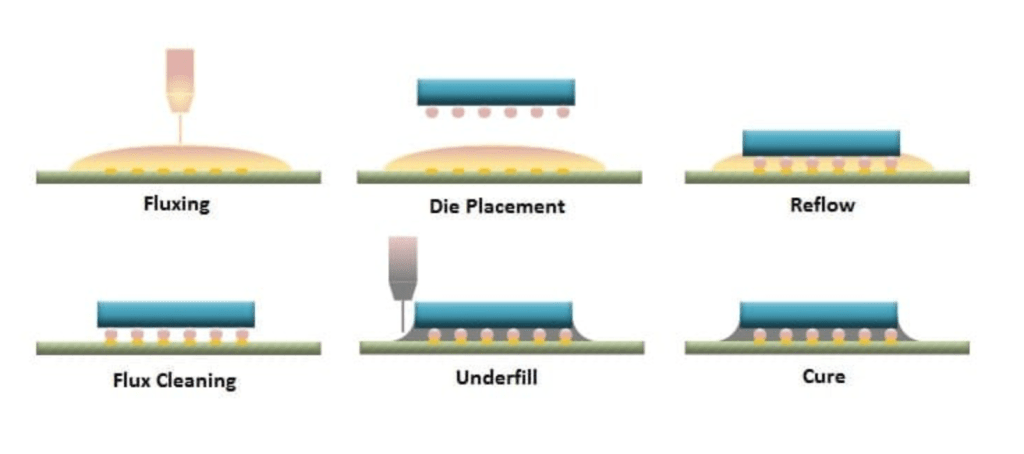
いろいろなパッケージでもこのフローが基本である
下表は、上記記事から説明のために引用します。
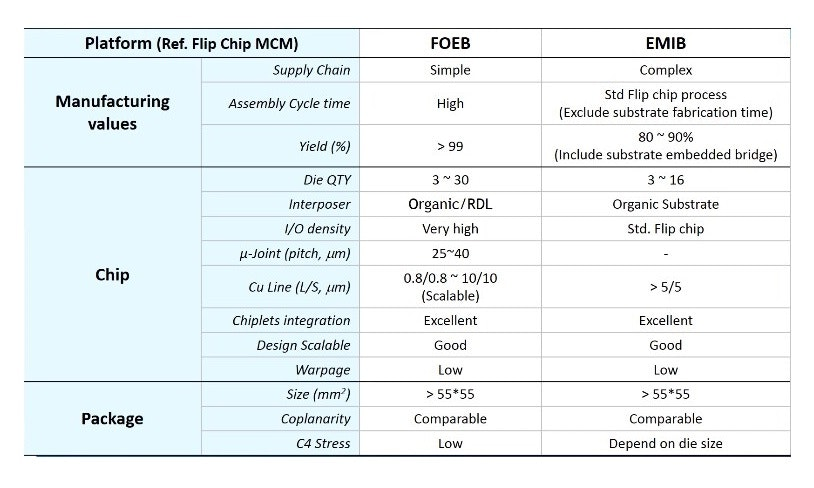
おわりに
SemiAnalysis 、これだけの記事が無料で読めるのは、とっても嬉しいです。。。